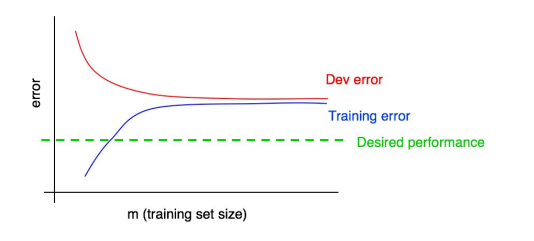
标签:也会 idea 设计模式 传统 span 依赖 方法 样本 中标
《Machine Learning Yearning》总结
原文地址:https://www.cnblogs.com/lokvahkoor/p/13605691.html