标签:执行 sed awk 开头 item find查找 mask 非交互 转换 搜索
一、Shell编程四剑客之Find
Find工具主要用于操作系统文件、目录的查找,其语法参数格式为:
find path -option [ -print ] [ -exec -ok command ] { } \;
其option常用参数详解如下:
-name filename #查找名为filename的文件; -type b/d/c/p/l/f #查是块设备、目录、字符设备、管道、符号链接、普通文件; -size n[c] #查长度为n块[或n字节]的文件; -perm #按执行权限来查找; -user username #按文件属主来查找; -group groupname #按组来查找; -mtime -n +n #按文件更改时间来查找文件,-n指n天以内,+n指n天以前; -atime -n +n #按文件访问时间来查找文件; -ctime -n +n #按文件创建时间来查找文件; -mmin -n +n #按文件更改时间来查找文件,-n指n分钟以内,+n指n分钟以前; -amin -n +n #按文件访问时间来查找文件; -cmin -n +n #按文件创建时间来查找文件; -nogroup #查无有效属组的文件; -nouser #查无有效属主的文件; -newer f1 !f2 #找文件,-n指n天以内,+n指n天以前; -depth #使查找在进入子目录前先行查找完本目录; -fstype #查更改时间比f1新但比f2旧的文件; -mount #查文件时不跨越文件系统mount点; -follow #如果遇到符号链接文件,就跟踪链接所指的文件; -cpio #查位于某一类型文件系统中的文件; -prune #忽略某个目录; -maxdepth #查找目录级别深度。
(1) Find工具-name参数案列:
find /data/ -name "*.txt" #查找/data/目录以.txt结尾的文件; find /data/ -name "[A-Z]*" #查找/data/目录以大写字母开头的文件; find /data/ -name "test*" #查找/data/目录以test开头的文件;
(2) Find工具-type参数案列:
find /data/ -type d #查找/data/目录下的文件夹; find /data/ ! -type d #查找/data/目录下的非文件夹; find /data/ -type l #查找/data/目录下的链接文件。 find /data/ -type d |xargs chmod 755 -R #查目录类型并将权限设置为755; find /data/ -type f |xargs chmod 644 -R #查文件类型并将权限设置为644;
(3) Find工具-size参数案列:
find /data/ -size +1M #查文件大小大于1Mb的文件; find /data/ -size 10M #查文件大小为10M的文件; find /data/ -size -1M #查文件大小小于1Mb的文件;
(4) Find工具-perm参数案列:
find /data/ -perm 755 #查找/data/目录权限为755的文件或者目录; find /data/ -perm -007 #与-perm 777相同,表示所有权限; find /data/ -perm +644 #文件权限符号644以上;
(5) Find工具-mtime参数案列:
atime,access time 文件被读取或者执行的时间; ctime,change time 文件状态改变时间; mtime,modify time 文件内容被修改的时间; find /data/ -mtime +30 -name "*.log" #查找30天以前的log文件; find /data/ -mtime -30 -name "*.txt" #查找30天以内的log文件; find /data/ -mtime 30 -name "*.txt" #查找第30天的log文件; find /data/ -mmin +30 -name "*.log" #查找30分钟以前修改的log文件; find /data/ -amin -30 -name "*.txt" #查找30分钟以内被访问的log文件; find /data/ -cmin 30 -name "*.txt" #查找第30分钟改变的log文件。
(6) Find工具参数综合案列:
#1.查找/data目录以.log结尾,文件大于10k的文件,同时cp到/tmp目录;
find /data/ -name "*.log" –type f -size +10k -exec cp {} /tmp/ \;
#2.查找/data目录以.txt结尾,文件大于10k的文件,权限为644并删除该文件;
find /data/ -name "*.log" –type f -size +10k -m perm 644 -exec rm –rf {} \;
#3.查找/data目录以.log结尾,30天以前的文件,大小大于10M并移动到/tmp目录;
find /data/ -name "*.log" –type f -mtime +30 –size +10M -exec mv {} /tmp/ \;
#4.查找目录类型并将权限设置755
find /data/ -type d |xargs chmod 755 -R
#5.当前目录下的第一级目录查找.txt结尾的文件
find . -maxdepth 1 -type f -name ‘*.txt‘
#6.查找/data目录以.log结尾的文件,大小大于10M并将其复制到/tmp目录;
find /data/ -name "*.log" -type f -size +10m -exec cp {} /tmp/ \;
#7.查找/data目录以.log结尾,30天以前的文件,大小大于10M并将其移动到/tmp目录;
find /data/ -name "*.log" -type f -mtime +30 -size +10m -exec mv {} /tmp/ \;
#8.当前目录下查找一天以内修改的文件,删除之。
# -maxdepth 1 一天以内的目录
# -name "*.text" 结尾为.text
# -type f 文件
# -mtime -1 1天以内修改的文件
# -exec rm -rf {} 把前面的结果承接引入到大括号位置
# \; 固定的格式
find . -maxdepth 1 -type f -name "*.text" -mtime -1 -exec rm -rf {} \;
#或者
find . -maxdepth 1 -type f -name "*.txt" -mtime -1 |xargs rm -rf {} \;
#9.当前目录下查找一天以内修改的文件,复制到home文件夹下
find . -maxdepth 1 -type f -name "*.txt" -mtime -1 -exec cp {} /home/ \;
#10.查找path目录下名称为filename的文件,一天以内修改的并删除
find /path/ -name "filename" -mtime -1 | xargs rm -rf {} \; xargs与管道“|”一起用,用于承接,将管道前面的语句放入 { } 中,进行删除, {} \; 为find命令结束语句。
#11.查找path目录下名称为filename的文件,30天以上修改的大小10k以上权限为755
find /path/ -name "filename" -type f -mtime +30 -size +10k -perm 755 查找过滤权限为755的文件
#.12.查找文件,并将文件统一修改权限为644:
find . -type f -exec chmod -R 644 {} \; R为可继承,子目录文件也会被修改
#13.查找目录,并将目录统一修改权限为755:
find . -type d -exec chmod -R 755 {} \;
#14.基于FIND查找Linux操作系统指定目录以.log名称,排除access.log 和error.log,查找10天以前的,查找文件类型而不是目录类型, 日志大小大于20M,小于35M,该日志文件拥有者是root用户, 然后将软件备份到/tmp/;
find / -name "*.log" ! -name "access.log" ! -name "error.log" -mtime -10 -type f -size +20M -size -35M -user root -exec cp {} /tmp/ \;
#15.-o 表示或者-a 表示and
find -name ‘a.*‘ -o -name ‘12.*‘
find -name ‘a.*‘ -a -type f
#16.将当前目录下所有文件或所有目录的权限修改为644或者755
find . -type f -exec chmod -R 644 {} \; #将当前目录下的所有文件的权限修改成664
find . -type d -exec chmod -R 755 {} \; #将当前目录下的所有目录的权限修改成755
#|xargs 表示将前面命令获得的结果作为一个整体,放到后面的{}中去
#-exec 将前面的结果作为后面的输入。
#|xargs 可换成-exec ,-exec 可支持的操作范围更广(如:cp mv chmod chown)
#|xargs 只支持 rm删除操作等少数。
#以后使用前面的命令结果,推荐只使用-exec
#ls -li # 可以查看文件的id号
二、Shell编程四剑客之sed
sed是一个非交互式文本编辑器,它可对文本文件和标准输入进行编辑,标准输入可以来自键盘输入、文本重定向、字符串、变量,甚至来自于管道的文本,与VIM编辑器类似,它一次处理一行内容,sed可以编辑一个或多个文件,简化对文件的反复操作、编写转换程序等。
在处理文本时把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),紧接着用sed命令处理缓冲区中的内容,处理完成后把缓冲区的内容输出至屏幕或者写入文件。
逐行处理直到文件末尾,然而如果打印在屏幕上,实质文件内容并没有改变,除非你使用重定向存储输出或者写入文件。其语法参数格式为:
sed [-Options] [‘Commands’] filename
sed工具默认处理文本,文本内容输出屏幕已经修改,但是文件内容其实没有修改,需要加-i参数即对文件彻底修改; x #x为指定行号; x,y #指定从x到y的行号范围; /pattern/ #查询包含模式的行; /pattern/pattern/ #查询包含两个模式的行; /pattern/,x #从与pattern的匹配行到x号行之间的行; x,/pattern/ #从x号行到与pattern的匹配行之间的行; x,y! #查询不包括x和y行号的行; r #从另一个文件中读文件; w #将文本写入到一个文件; y #变换字符; q #第一个模式匹配完成后退出; l #显示与八进制ASCII码等价的控制字符; {} #在定位行执行的命令组; p #打印匹配行; = #打印文件行号; a\ #在定位行号之后追加文本信息; i\ #在定位行号之前插入文本信息; d #删除定位行; c\ #用新文本替换定位文本; s #使用替换模式替换相应模式; n #读取下一个输入行,用下一个命令处理新的行; N #将当前读入行的下一行读取到当前的模式空间。 h #将模式缓冲区的文本复制到保持缓冲区; H #将模式缓冲区的文本追加到保持缓冲区; x #互换模式缓冲区和保持缓冲区的内容; g #将保持缓冲区的内容复制到模式缓冲区; G #将保持缓冲区的内容追加到模式缓冲区。
常用SED工具企业演练案列:
(1) 替换jfedu.txt文本中old为new: sed ‘s/old/new/g‘ jfedu.txt (2) 打印jfedu.txt文本第一行至第三行: sed -n ‘1,3p‘ jfedu.txt (3) 打印jfedu.txt文本中第一行与最后一行: sed -n ‘1p;$p‘ jfedu.txt (4) 删除jfedu.txt第一行至第三行、删除匹配行至最后一行: sed ‘1,3d‘ jfedu.txt sed ‘/jfedu/,$d‘ jfedu.txt (5) 删除jfedu.txt最后6行及删除最后一行: for i in `seq 1 6`;do sed -i ‘$d‘ jfedu.txt ;done sed ‘$d‘ jfedu.txt (6) 删除jfedu.txt最后一行: sed ‘$d‘ jfedu.txt (7) 在jfedu.txt查找jfedu所在行,并在其下一行添加word字符,a表示在其下一行添加字符串: sed ‘/jfedu/aword‘ jfedu.txt (8) 在jfedu.txt查找jfedu所在行,并在其上一行添加word字符,i表示在其上一行添加字符串: sed ‘/jfedu/iword‘ jfedu.txt (9) 在jfedu.txt查找以test结尾的行尾添加字符串word,$表示结尾标识,&在Sed中表示添加: sed ‘s/test$/&word/g‘ jfedu.txt (10) 在jfedu.txt查找www的行,在其行首添加字符串word,^表示起始标识,&在Sed中表示添加: sed ‘/www/s/^/&word/‘ jfedu.txt (11) 多个sed命令组合,使用-e参数: sed -e ‘/www.jd.com/s/^/&1./‘ -e ‘s/www.jd.com$/&./g‘ jfedu.txt (12) 多个sed命令组合,使用分号“;”分割: sed -e ‘/www.jd.com/s/^/&1./;s/www.jd.com$/&./g‘ jfedu.txt (13) Sed读取系统变量,变量替换: WEBSITE=WWW.JFEDU.NET Sed “s/www.jd.com/$WEBSITE/g” jfedu.txt (14) 修改Selinux策略enforcing为disabled,查找/SELINUX/行,然后将其行enforcing值改成disabled、!s表示不包括SELINUX行: sed -i ‘/SELINUX/s/enforcing/disabled/g‘ /etc/selinux/config sed -i ‘/SELINUX/!s/enforcing/disabled/g‘ /etc/selinux/config
通常而言,SED将待处理的行读入模式空间,脚本中的命令逐行进行处理,直到脚本执行完毕,然后该行被输出,模式空间请空;然后重复刚才的动作,文件中的新的一行被读入,直到文件处理完备。
如果用户希望在某个条件下脚本中的某个命令被执行,或者希望模式空间得到保留以便下一次的处理,都有可能使得sed在处理文件的时候不按照正常的流程来进行。这时可以使用SED高级语法来满足用户需求。总的来说,SED高级命令可以分为三种功能:
q N、D、P:处理多行模式空间的问题;
q H、h、G、g、x:将模式空间的内容放入存储空间以便接下来的编辑;
q :、b、t:在脚本中实现分支与条件结构。
(1) 在jfedu.txt每行后加入空行,也即每行占永两行空间,每一行后边插入一行空行、两行空行及前三行每行后插入空行: sed ‘/^$/d;G‘ jfedu.txt sed ‘/^$/d;G;G‘ jfedu.txt sed ‘/^$/d;1,3G;‘ jfedu.txt (2) 将jfedu.txt偶数行删除及隔两行删除一行: sed ‘n;d‘ jfedu.txt sed ‘n;n;d‘ jfedu.txt (3) 在jfedu.txt匹配行前一行、后一行插入空行以及同时在匹配前后插入空行: sed ‘/jfedu/{x;p;x;}‘ jfedu.txt sed ‘/jfedu/G‘ jfedu.txt sed ‘/jfedu/{x;p;x;G;}‘ jfedu.txt (4) 在jfedu.txt每行后加入空行,也即每行占永两行空间,每一行后边插入空行: sed ‘/^$/d;G‘ jfedu.txt (5) 在jfedu.txt每行后加入空行,也即每行占永两行空间,每一行后边插入空行: sed ‘/^$/d;G‘ jfedu.txt (6) 在jfedu.txt每行前加入顺序数字序号、加上制表符\t及.符号: sed = jfedu.txt| sed ‘N;s/\n/ /‘ sed = jfedu.txt| sed ‘N;s/\n/\t/‘ sed = jfedu.txt| sed ‘N;s/\n/\./‘ (7) 删除jfedu.txt行前和行尾的任意空格: sed ‘s/^[ \t]*//;s/[ \t]*$//‘ jfedu.txt (8) 打印jfedu.txt关键词old与new之间的内容: sed -n ‘/old/,/new/‘p jfedu.txt (9) 打印及删除jfedu.txt最后两行: sed ‘$!N;$!D‘ jfedu.txt sed ‘N;$!P;$!D;$d‘ jfedu.txt (10) 合并上下两行,也即两行合并: sed ‘$!N;s/\n/ /‘ jfedu.txt sed ‘N;s/\n/ /‘ jfedu.txt
动作说明:
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
sed命令的选项(option):
-n :只打印模式匹配的行
-e :直接在命令行模式上进行sed动作编辑,此为默认选项
-f :将sed的动作写在一个文件内,用–f filename 执行filename内的sed动作
-r :支持扩展表达式
-i :直接修改文件内容
作用:文件外命令对文件内容进行操作
? vi test.txt # name info My name is kongdesheng This is my first scripts! 192.168.1.11 192.168 ? :%s/169/168/g #文件中把全部169改成168
sed ‘s/192/10/g‘ test.txt //缓存修改,实际文件内容未变 sed -i ‘s/192/10/g‘ test.txt //文件内容真正被修改
#在文件内容的行首添加一个空格,‘^’:代表开始 sed ‘s/^/& /g‘ test.txt #在文件内容的行首添加一个id空格,在实际工作中用for循环把id替换成1,2,这种行号一行一行的加入行号 sed ‘s/^/&id /g‘ test.txt
#在文件内容的行尾添加一个空格id,‘$’:代表开始 sed ‘s/$/& id/g‘ test.txt
#‘a‘:下一行新增 sed ‘/kongdesheng/a and is lisi‘ test.txt
#‘i‘:前一行新增 sed ‘/kongdesheng/i and is lisi‘ test.txt
#‘-n‘ :只打印模式匹配的行 sed -n ‘/kongdesheng/p‘ test.txt
sed -n ‘1p‘ test.txt #打印第一行 sed -n ‘3p‘ test.txt #打印第三行 sed -n ‘1,5p‘ test.txt #打印1至5行
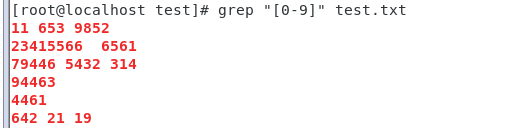
vi test.txt 11 653 9852 23415566 6561 ? 79446 5432 314 94463 4461 642 21 19
命令:
#sed‘s/ /\n/g‘ 把空格换行,把每个数字为一行 #grep -v "^$" grep:分组过滤筛选数据,-v:剔除匹配后面结果的行,这里作用是去除空行 #sort -nr 排序(-nr:降序, -n:升序) -r将数字当做字符进行排序,-nr 按照整个数字来排序 #sed -n ‘1p‘ 打印第一行 #sed -n ‘1p;$p‘ $代表最后一个,这里$p代表最后一行 cat test.txt |sed ‘s/ /\n/g‘|grep -v "^$"|sort -nr|sed -n ‘1p;$p‘
再来一组示例
删除第1行和第2行(d表示删除) sed ‘1,2d‘ test.txt 删除第3行到最后一行($表示最后一行,$-1表示倒数第二行) sed ‘3,$d‘ test.txt 模式匹配,删除包含oot的行 sed ‘/oot/d‘ test.txt 显示以/开始的行,会重复显示,因为模式空间还会显示一次,可加‘-n‘静默模式不显示模式空间的内容 sed ‘/^\//p‘ test.txt 在以/开头的行后面加上hello sed -n ‘/^\//a \hello‘ test.txt 把包含oot的行数据保存到etc/fstab中 sed -n ‘/oot/w test.txt‘ /etc/fstab 把文件中的oot替换成OOT(默认只替换每行中第一次被匹配的字符串,加了修饰g,全局替换) sed ‘s/oot/OOT/g‘ test.txt
查找当前目录下包含127.0.0.1关键字的文件 grep -rl ‘127.0.0.1‘ ./ find . -type f |xargs grep "127.0.0.1" find . -type f -exec awk ‘/127.0.0.1/‘ {} \; 显示除过第3行到第10行的内容 sed ‘3,10d‘ test.txt awk ‘!(NR>=3&&NR<=10)‘ test.txt 显示第3行到第10行的内容 sed -n ‘3,10p‘ test.txt awk ‘NR>=3&&NR<=10‘ test.txt head -10 test.txt|tail -8 awk ‘NR==3,NR==7‘ test.txt (逗号表示连续,第一次匹配到第二次匹配中间的所有行) 只显示第3行和第10行的内容 awk ‘NR==3;NR==10‘ test.txt (分号表示分隔符,分割多条命令)
另有:
用于筛选行数据,不会对原文件进行修改,所以需要写-i (imediate)选项将修改保存到原文件中 格式是 sed 参数 ‘脚本语句‘待操作文件 sed 参数 -f ‘脚本文件‘ 待操作文件 -i 直接写入源文件中,若不加只是输出到屏幕上 a appen 追加 i insert **a和i的区别是,a插到指定行的后边,i插到制定行的前边** d delete s substitution **eg. sed -i ‘4a xxxxxxxx‘ 待操作文件** **eg 删除:sed -i ‘2,7d‘ 待操作文件,删除文件中的2到7行** **eg. sed‘s/原始词/目标词/g‘** 删除和打印 sed /pattern/p 打印匹配pattern 的行 eg. **sed -n ‘/abc/p‘ test.txt** 删除包含abc的行(-n表示只显示输出结果) sed /pattern/d 删除打印pattern的行 eg.sed ‘/abc/d‘ text.txt 删除包含abc的行 复制替换 sed ‘s/bc/-&-/‘ textfile(将bc替换为-bc) 写扩展正则时需要加 -r选项 sed ‘s/目标词/替换后的词;s/目标词/替换后的词‘用;隔开做多次替换,也可以用-e表示多个替换,eg sed -e‘s/目标词/替换后的词 -e ‘s/目标词/替换后的词‘ 大小写转换 echo ‘ABCD‘|sed -E ‘s/(\w+)/\L\1/‘ 替换成小写 \L是low转化成小写 \U是uper转化成大学 \u是首字母大写 \E是停止转换
#打印文件的第5行到第10行 sed -n ‘5,10p‘ jk.txt #替换 sed ‘s/v/V/‘ jk.txt ->此时并没有替换文件里面的内容,只是内容显示替换 sed ‘s/v/V/g‘ jk.txt ->全部替换 要求: 把所有的/ 换成空白 sed -i “s///g” 文件名 [root@jk ~]# sed -i "s/\///g" data [root@jk ~]# sed -i "s#/##g" data #"s///g"和"s///"的区别 前一个就是替换所有的,后一个是替换第一个
#sed -n ‘/起始时间/,/结束时间/p‘ 日志文件 #sed 查找某个时间范围内所有的日志信息 sed -n ‘/2019-04-01$19:/,/2019-04-01$21:/p‘ server_*log.2019-04-01 >> /data/backup/data.txt #截取指定行数之间的日志 sed -n ‘开始行数,结束行数p‘ 待截取的文件 >> 保存的新文件
三、Shell编程四剑客之AWK
AWK是一个优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一,以Aho、Weinberger、Kernighan三位发明者名字首字母命名为AWK,AWK是一个行级文本高效处理工具,AWK经过改进生成的新的版本有Nawk、Gawk,一般Linux默认为Gawk,Gawk是 AWK的GNU开源免费版本。
AWK基本原理是逐行处理文件中的数据,查找与命令行中所给定内容相匹配的模式,如果发现匹配内容,则进行下一个编程步骤,如果找不到匹配内容,则 继续处理下一行。其语法参数格式为,AWK常用参数、变量、函数详解如下:
awk ‘pattern + {action}‘ file
(1) AWK基本语法参数详解: q 单引号‘ ‘是为了和shell命令区分开; q 大括号{ }表示一个命令分组; q pattern是一个过滤器,表示匹配pattern条件的行才进行Action处理; q action是处理动作,常见动作为Print; q 使用#作为注释,pattern和action可以只有其一,但不能两者都没有。 (2) AWK内置变量详解: q FS 分隔符,默认是空格; q OFS 输出分隔符; q NR 当前行数,从1开始; q NF 当前记录字段个数; q $0 当前记录; q $1~$n 当前记录第n个字段(列)。 (3) AWK内置函数详解: q gsub(r,s):在$0中用s代替r; q index(s,t):返回s中t的第一个位置; q length(s):s的长度; q match(s,r):s是否匹配r; q split(s,a,fs):在fs上将s分成序列a; q substr(s,p):返回s从p开始的子串。 (4) AWK常用操作符,运算符及判断符: q ++ -- 增加与减少( 前置或后置); q ^ ** 指数( 右结合性); q ! + - 非、一元(unary) 加号、一元减号; q + - * / % 加、减、乘、除、余数; q < <= == != > >= 数字比较; q && 逻辑and; q || 逻辑or; q = += -= *= /= %= ^= **= 赋值。 (5) AWK与流程控制语句: q if(condition) { } else { }; q while { }; q do{ }while(condition); q for(init;condition;step){ }; q break/continue。
常用AWK工具企业演练案列:
(1) AWK打印硬盘设备名称,默认以空格为分割: df -h|awk ‘{print $1}‘ (2) AWK以空格、冒号、\t、分号为分割: awk -F ‘[ :\t;]‘ ‘{print $1}‘ jfedu.txt (3) AWK以冒号分割,打印第一列,同时将内容追加到/tmp/awk.log下: awk -F: ‘{print $1 >>"/tmp/awk.log"}‘ jfedu.txt (4) 打印jfedu.txt文件中的第3行至第5行,NR表示打印行,$0表示文本所有域: awk ‘NR==3,NR==5 {print}‘ jfedu.txt awk ‘NR==3,NR==5 {print $0}‘ jfedu.txt (5) 打印jfedu.txt文件中的第3行至第5行的第一列与最后一列: awk ‘NR==3,NR==5 {print $1,$NF}‘ jfedu.txt (6) 打印jfedu.txt文件中,长度大于80的行号: awk ‘length($0)>80 {print NR}‘ jfedu.txt (7) AWK引用Shell变量,使用-v或者双引号+单引号即可: awk -v STR=hello ‘{print STR,$NF}‘ jfedu.txt STR="hello";echo| awk ‘{print "‘${STR}‘";}‘ (8) AWK以冒号切割,打印第一列同时只显示前5行: cat /etc/passwd|head -5|awk -F: ‘{print $1}‘ awk -F: ‘NR>=1&&NR<=5 {print $1}‘ /etc/passwd (9) Awk指定文件jfedu.txt第一列的总和: cat jfedu.txt |awk ‘{sum+=$1}END{print sum}‘ (10) AWK NR行号除以2余数为0则跳过该行,继续执行下一行,打印在屏幕: awk -F: ‘NR%2==0 {next} {print NR,$1}‘ /etc/passwd (11) AWK添加自定义字符: ifconfig eth0|grep "Bcast"|awk ‘{print "ip_"$2}‘ (12) AWK格式化输出passwd内容,printf打印字符串,%格式化输出分隔符,s表示字符串类型,-12表示12个字符,-6表示6个字符: awk -F: ‘{printf "%-12s %-6s %-8s\n",$1,$2,$NF}‘ /etc/passwd (13) AWK OFS输出格式化\t: netstat -an|awk ‘$6 ~ /LISTEN/&&NR>=1&&NR<=10 {print NR,$4,$5,$6}‘ OFS="\t" (14) AWK与if组合实战,判断数字比较: echo 3 2 1 | awk ‘{ if(($1>$2)||($1>$3)) { print $2} else {print $1} }‘ (15) AWK与数组组合实战,统计passwd文件用户数: awk -F ‘:‘ ‘BEGIN {count=0;} {name[count] = $1;count++;};END{for (i = 0;i < NR;i++) print i, name[i]}‘ /etc/passwd (16) awk分析Nginx访问日志的状态码404、502等错误信息页面,统计次数大于20的IP地址。 awk ‘{if ($9~/502|499|500|503|404/) print $1,$9}‘ access.log|sort|uniq –c|sort –nr | awk ‘{if($1>20) print $2}‘ (17) 用/etc/shadow文件中的密文部分替换/etc/passwd中的"x"位置,生成新的/tmp/passwd文件。 awk ‘BEGIN{OFS=FS=":"} NR==FNR{a[$1]=$2}NR>FNR{$2=a[$1];print >>"/tmp/passwd"}‘ /etc/shadow /etc/passwd (18) Awk统计服务器状态连接数: netstat -an | awk ‘/tcp/ {s[$NF]++} END {for(a in s) {print a,s[a]}}‘ netstat -an | awk ‘/tcp/ {print $NF}‘ | sort | uniq -c
#打印文本中需要的某个字段 awk -F" " ‘{print $6}‘ jk.txt
【例题】 打印出该服务器的ip ifconfig | grep broadcast | awk -F‘ ‘ ‘{print $2}‘ ip addr | grep brd | awk ‘NR==3 {print $2}‘ 特别的: NR表示需要打印的行号,NF表示最后一列
#将相同名称后的所有内容配置成一行,且用逗号将前后进行区分 awk ‘{a[$1]=a[$1]" "$2} END{for(i in a ) print i","a[i]}‘ 【示例】 [root@localhost tmp]# cat image.txt tfboys karry tfboys roy tfboys jackson [root@localhost tmp]# cat image.txt | awk ‘{a[$1]=a[$1]" "$2} END{for(i in a ) print i","a[i]}‘ tfboys, karry roy jackson
#实现不同单位行的累加计算,即K、M、G之间的计算 [root@Legion80 ~]# cat 123 75955M 13232K 17492K 75953M 75963M 2G 10G 5T [root@Legion80 ~]# awk ‘{a+=/T/?$0*1024:(/M/?$0/1024:(/K/?$0/(1024^2):$0))}END{print a"G"}‘ 123 5354.56G [root@Legion80 ~]# awk ‘{a+=/G/?$0/1024:(/M/?$0/(1024^2):(/K/?$0/(1024^3):$0))}END{print a"T"}‘ 123 5.22906T [root@Legion80 ~]# awk ‘{a+=/T/?$0*(1024^2):(/G/?$0*1024:(/K/?$0/1024:$0))}END{print a"M"}‘ 123 5.48307e+06M [root@Legion80 ~]# awk ‘{a+=/T/?$0*(1024^2):(/G/?$0*1024:(/K/?$0/1024:$0))}END{printf"%.fM\n",a}‘ 123 5483069M #另一方案: #!/bin/bash total=0 while read LINE do var=$(echo $LINE | tr -d ‘[0-9.]‘) # 获取除0-9数字和.外的字符 num=$(echo $LINE | tr -cd ‘[0-9.]‘) # 仅需0-9和. case $var in [Kk]*) total=$(echo "$total + $num * 1024" | bc) ;; # 匹配k,K [Mm]*) total=$(echo "$total + $num * 1024 * 1024" | bc) ;; # 匹配m,M [Gg]*) total=$(echo "$total + $num * 1024 * 1024 * 1024" | bc) ;;# 匹配g,G *) total=$(echo "$total + $num" | bc) ;; # 浮点型和整数通过bc来计算 esac done < cat 123 echo "total = $total"
#awk求和,第一列相同时,对第二列进行计算 awk ‘{sum[$2]+=$1/(1024^2)}END{for(c in sum){print sum[c],c}}‘
1、与if判断语句进行嵌套使用
#第一个字段大于5,则打印第一第二字段 awk ‘{if($1 >= 5) print $1,$2}‘ file #第一个字段大于5,则打印第一第三字段 awk ‘{if($1 >= 5) {print $1,$2} else {print $1,$3}}‘ #在进行访问日志排查的时候,经常会遇到500、502这样的错误,需要根据字段进行排查 awk ‘{if($9 = 500) print $0}‘ /var/log/nginx/access.log
2、与for循环语句进行嵌套使
[root@localhost] awk ‘BEGIN { for (i = 1; i <= 5; ++i) print i }‘
3、与while循环语句的嵌套使用
[root@localhost] awk ‘BEGIN {i = 1; while (i < 6) { print i; ++i }
4、与do-while循环语句的嵌套使用
[root@localhost] awk ‘BEGIN {i = 1; do { print i; ++i } while (i < 6) }‘
5、break、continue的嵌套使用
[root@localhost]awk ‘BEGIN { sum = 0; for (i = 0; i < 20; ++i) { sum += i; if (sum > 50) break; else print "Sum =", sum } }‘
[root@localhost] awk ‘BEGIN {for (i = 1; i <= 20; ++i) {if (i % 2 == 0) print i ; else continue} }‘
说明:所有的嵌套使用规律其实和其单独使用是一样的,只要熟练使用各个循环语句和判断语句以及awk的使用方法,就可以实现嵌套
6、处理列数据
awk -F:"{print ¥7}" 文件名 -F:表示分割符是:,原先默认的分割符是空格或制表符,¥+数字,表示要提取哪一列脚本语句要放在‘/pattern/{action}‘里 $0表示全部打印,¥1.。。表示每一列
vi test.txt
My name is kongdesheng
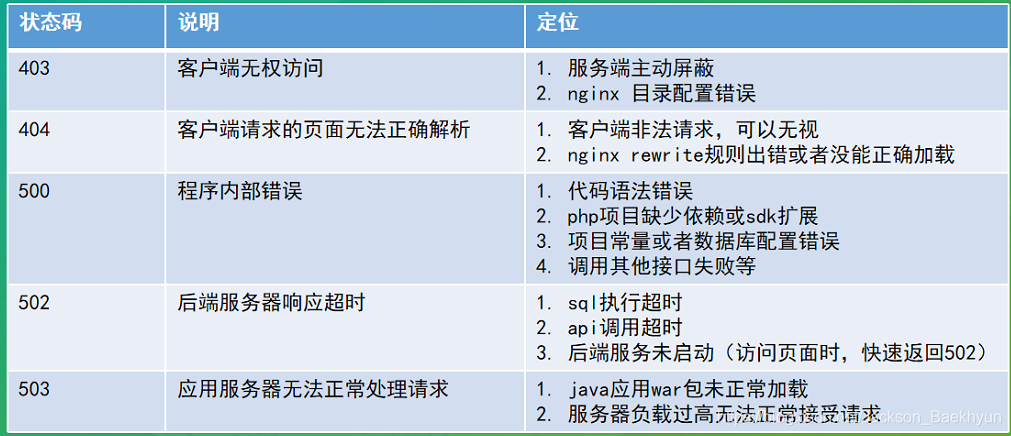
#$4:打印第四列 awk ‘{print $4}‘ test.txt #或者 cat test.txt |awk ‘{print $4}‘ ? #$nf:打印全部 awk ‘{print $nf}‘ test.txt ? #$NF:打印最后一列 awk ‘{print $NF}‘ test.txt
列2:打印/etc/passwd文件中的第一列(用户)
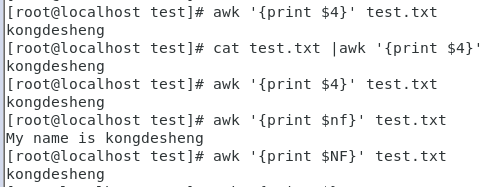
#-F:以‘:‘为分隔划分列(默认是空格划分列) cat /etc/passwd |awk -F: ‘{print $1}‘ #或者如下 #sed ‘s/:/ /g‘:把冒号换成空格 cat /etc/passwd |sed ‘s/:/ /g‘ |awk ‘{print $1}‘
列3:从ifconfig命令集得到ip地址
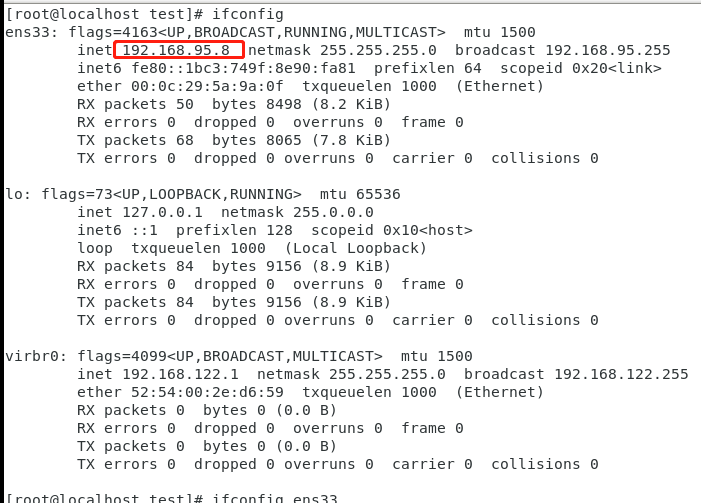
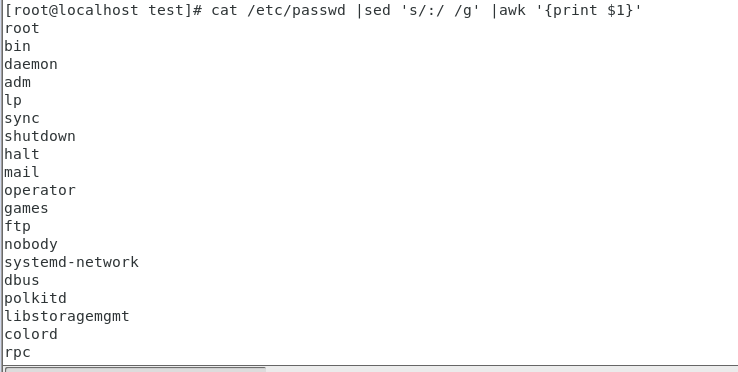
#grep ‘netmask‘ :查找包含‘netmask‘的行 #awk ‘{print$2}‘:第二列 ifconfig ens33 |grep ‘netmask‘|awk ‘{print$2}‘

列4:df -h 检查linux服务器的文件系统的磁盘空间占用情况,返回占用率
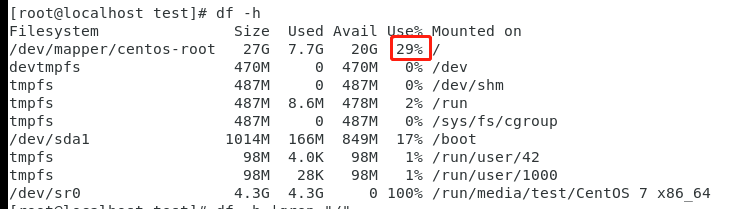
#grep "/$" :以‘/‘结尾的行 #awk ‘{print$5}‘ :第五列 df -h |grep "/$" |awk ‘{print$5}‘ # sed ‘s/%//g‘ :去除‘%‘号 df -h |grep "/$" |awk ‘{print$5}‘| sed ‘s/%//g‘


列4: 在内容前面加属性

#‘^‘ 开始 #‘$‘ 末尾 awk ‘{print$NF}‘ test.txt |sed ‘s/^/Name:/g‘ 或者 awk ‘{print"Name:"$NF}‘ test.txt

awk 可以打印某一行或者某一列(列是以空格分隔的)
awk ‘{print $1}‘ test.txt 打印文件第一列
awk ‘{print $3}‘ test.txt 打印文件第3列
awk ‘{print $NF}‘ test.txt 打印文件倒数第1个域 NF 表示最后一个
awk ‘{print $(NF-1)}‘ test.txt 打印文件倒数第2个域
awk -F: ‘{print $1,$NF}‘ /etc/passwd|head 5 打印前5行的第一列和最后一列
-F: 格式匹配,这样就可以不显示文本行中的 : 冒号了
awk -F: ‘{print $1":"$NF}‘ /etc/passwd|head 5 在第一列与最后一列之间添加一个:冒号
awk -F: ‘{print $1" secret "$NF}‘ /etc/passwd|head 5 在第一列与最后一列之间 多加一列 secret
-F: 表示以:符号做分隔
192.168.1.68 将其转换成 192-168-1-68
ifconfig|grep "inet addr"|grep 192 |awk ‘{print $2}‘
ifconfig|grep "inet addr"|grep -v "172.0.0.1|awk ‘{print $2}‘|awk -F"addr:" ‘{print $2}‘|awk -F. ‘{print $1"-"$2"-"$3"-"$4}‘
NR:number of record(行号)
NF:number of field(列号)
显示所有数据并在第一列加上行号 awk ‘{print NR "\t" $0}‘ test.txt 显示所有数据并在第一列显示当前行的列数(空格分割为界) awk ‘{print NF "\t" $0}‘ test.txt 查找功能 查找第一列为bob的数据 awk ‘$1=="bob"{print $0}‘ test.txt 查找第7行数据 awk ‘NR==7{print $0}‘ test.txt 输入按逗号分割开,输出按制表符分割显示(输入输出分隔符默认都是空格) awk ‘BEGIN{FS=","; OFS="\t"} {print $1, $2}‘ 将第3列的数据隐藏,显示为xxx awk ‘{$3="xxx"; print $0}‘ data.txt 打出文件的最后一列数据 awk ‘{print $NF}‘ data.txt awk ‘{a=2; b="apple"; c=3; print b+c}‘ 输出3,字符串和数字相加会把字符串中的最前面数字部分才会相加,没有数字部分则为0 awk ‘{a=2; b="32apple"; c=3; print b+c}‘ 输出35,只有最前面是数字才会相加
Regular Expression(正则表达式)
匹配字符串中含有abc的值 awk ‘/abc/{print $0}‘ data.txt 匹配字符串中含有‘a+一个任意字符+c‘的值 awk ‘/a.c/{print $0}‘ data.txt 如果就要匹配‘a.c‘这个字符串就需要用转义字符 awk ‘/a\.c/{print $0}‘ data.txt ^和$ 表示开始和结尾 匹配必须以abc开始的值 awk ‘/^abc/{print $0}‘ data.txt 匹配必须以abc结尾的值 awk ‘/abc$/{print $0}‘ data.txt 匹配‘a+a到z任意一个字符+c‘ awk ‘/a[a-z]c/{print $0}‘ data.txt 匹配‘a+除了小写a到z之外的一个字符+c‘ awk ‘/a[^a-z]c/{print $0}‘ data.txt 匹配‘0个a或者任意个a+b‘ awk ‘/a*b/{print $0}‘ data.txt 匹配‘至少一个a+b‘ awk ‘/a+b/{print $0}‘ data.txt 匹配‘a可以有也可以没有+b‘ awk ‘/a?b/{print $0}‘ data.txt 匹配‘abbbc‘ awk ‘/ab{3}c/{print $0}‘ data.txt 匹配‘a+3个b到10个b+c‘ awk ‘/ab{3,10}c/{print $0}‘ data.txt
四、Shell编程四剑客之GREP
全面搜索正则表达式(Global search regular expression(RE) ,GREP)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
Unix/Linux的grep家族包括grep、egrep和fgrep,其中egrep和fgrep的命令跟grep有细微的区别,egrep是grep的扩展,支持更多的re元字符, fgrep是fixed grep或fast grep简写,它们把所有的字母都看作单词,正则表达式中的元字符表示其自身的字面意义,不再有其他特殊的含义,一般使用比较少。
目前Linux操作系统默认使用GNU版本的grep。它功能更强,可以通过-G、-E、-F命令行选项来使用egrep和fgrep的功能。其语法格式及常用参数详解如下:
grep -[acinv] ‘word‘ Filename
Grep常用参数详解如下:
-a 以文本文件方式搜索; -c 计算找到的符合行的次数; -i 忽略大小写; -n 顺便输出行号; -v 反向选择,即显示不包含匹配文本的所有行; -h 查询多文件时不显示文件名; -l 查询多文件时只输出包含匹配字符的文件名; -s 不显示不存在或无匹配文本的错误信息; -E 允许使用egrep扩展模式匹配。
学习Grep时,需要了解通配符、正则表达式两个概念,很多读者容易把彼此搞混淆,通配符主要用在Linux的Shell命令中,常用于文件或者文件名称的操作,而正则表达式用于文本内容中的字符串搜索和替换,常用在AWK、GREP、SED、VIM工具中对文本的操作。
通配符类型详解:
* 0个或者多个字符、数字; ? 匹配任意一个字符; # 表示注解; | 管道符号; ; 多个命令连续执行; & 后台运行指令; ! 逻辑运算非; [ ] 内容范围,匹配括号中内容; { } 命令块,多个命令匹配。
正则表达式详解:
* 前一个字符匹配0次或多次; . 匹配除了换行符以外任意一个字符; .* 代表任意字符; ^ 匹配行首,即以某个字符开头; $ 匹配行尾,即以某个字符结尾; .... 标记匹配字符; [] 匹配中括号里的任意指定字符,但只匹配一个字符; [^] 匹配除中括号以外的任意一个字符; \ 转义符,取消特殊含义; \< 锚定单词的开始; \> 锚定单词的结束; {n} 匹配字符出现n次; {n,} 匹配字符出现大于等于n次; {n,m} 匹配字符至少出现n次,最多出现m次; \w 匹配文字和数字字符; \W \w的反置形式,匹配一个或多个非单词字符; \b 单词锁定符; \s 匹配任何空白字符; \d 匹配一个数字字符,等价于[0-9]。
常用GREP工具企业演练案列:
grep -c "test" jfedu.txt 统计test字符总行数; grep -i "TEST" jfedu.txt 不区分大小写查找TEST所有的行; grep -n "test" jfedu.txt 打印test的行及行号; grep -v "test" jfedu.txt 不打印test的行; grep "test[53]" jfedu.txt 以字符test开头,接5或者3的行; grep "^[^test]" jfedu.txt 显示输出行首不是test的行; grep "[Mm]ay" jfedu.txt 匹配M或m开头的行; grep "K…D" jfedu.txt 匹配K,三个任意字符,紧接D的行; grep "[A-Z][9]D" jfedu.txt 匹配大写字母,紧跟9D的字符行; grep "T\{2,\}" jfedu.txt 打印字符T字符连续出现2次以上的行; grep "T\{4,6\}" jfedu.txt 打印字符T字符连续出现4次及6次的行; grep -n "^$" jfedu.txt 打印空行的所在的行号; grep -vE "#|^$" jfedu.txt 不匹配文件中的#和空行; grep --color -ra -E "db|config|sql" * 匹配包含db或者config或者sql的文件; grep --color -E "\<([0-9]{1,3}\.){3}([0-9]{1,3})\>" jfedu.txt 匹配IPV4地址。
转载于:https://www.cnblogs.com/Lonelychampion/p/11427598.html
列1: 匹配以11开始的文件行
grep "^11" test.txt

列2: 匹配以61结尾的文件行
grep "61$" test.txt

列3: 匹配包含有0至9的文件行
grep "[0-9]" test.txt
列4: 匹配包含有a至z的文件行
grep "[a-z]" test.txt #匹配大写A-Z开始的行 grep "^[A-Z]" test.txt


列5: 默认匹配为模糊匹配(包含关系)
grep "168" test.txt

列6: 绝对匹配(相等关系)
grep "^192.168$" test.txt

列7: 匹配ip
#-E:将样式为延伸的正则表达式来使用 #[0-9]:匹配的参数 #{1,3}:出现的次数 grep -E "([0-9]{1,3}\.){3}[0-9]{1,3}" test.txt #或者如下语句,作用是一样的 cat test.txt |grep -E "([0-9]{1,3}\.){3}[0-9]{1,3}"

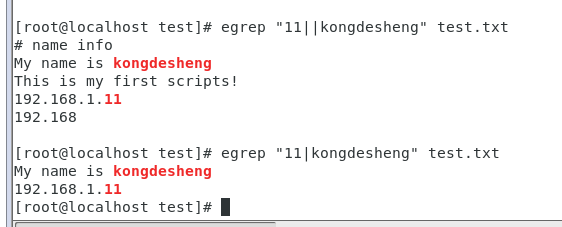
#‘||‘:全部打印,标红匹配内容 #‘|‘ :打印匹配的行内容 # -n 打印行号 egrep -n "11|kongdesheng" test.txt #或者 grep -E "11|kongdesheng" test.txt
转至https://www.cnblogs.com/KdeS/p/13214239.html
根据 字符串 查找文件内容 并执行 一些操作
grep -n --color ‘^hello‘ ~/Desktop/2.txt
(-n ==> 显示行数, -color ==> 显示颜色, ‘^hello‘ ⇒ 查找的字符串, ^ ==>字符串开头,
$ ==> 字符串结尾, ~/Desktop/2.txt ==> 查找的文件路径)
-------------------------------------------------------------------------------------------------
grep -v --color ‘^hello‘ ~/Desktop/2.txt | grep -v "^$"
(-v ==> 取反,不要以 hello 开头的内容, -v ”^$” ==> 去掉空行)
-------------------------------------------------------------------------------------------------
egrep ‘[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$‘ 2.txt egrep ‘([0-9]{1,3}\.){3}[0-9]{1,3}$‘ 2.txt (‘[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$‘ ==> 正则表达式匹配ip地址 xxx.xxx.xxx.xxx)
cat /etc/passwd
grep 命令用于查找文件中的内容。匹配文件中的内容
grep -n --color "root" /etc/passwd
-n 表示查找的结果在passwd文件的 行号
--color ==>为关键字加上颜色
/etc/passwd 这个文件
grep -n --color "^root" /etc/passwd
^root 表示以root开头的行,文本后面出现root关键字没有用
grep -n --color "root$" /etc/passwd
grep -n --color "bash$" /etc/passwd
root$ 表示文本所在行以root结尾
bash$ 表示文本所在行以bash结尾
grep "#" /etc/passwd #查找passwd文件中包含#的行 grep -v "#" /etc/passwd #查找passwd文件中不包含#的行
-v 表示不包含
grep -v "#" /etc/passwd | grep -v "^$" #查找passwd文件中不包含#的行,并去除空行
grep -v "^$" 表示不包含空行,即去除空行
使用grep查找文件中的ip地址
grep --color "[0-9][0-9]" test.txt "[0-9]" 表示0~9任意一个字符 "[0-9][0-9]" 两个连续数字 grep --color "[0-9]\{1,3}" test.txt #匹配1~3次
egrep --color "[0-9]\{1,3}\.[0-9]\{1,3}\.[0-9]\{1,3}\.[0-9]\{1,3}$" test.txt
[0-9]\{1,3}\. 表示以1~3位数字,并且后面有一个 . 号
\. 表示转义的. 一定要加上
[0-9]\{1,3}$ 表示以1~3位数字结尾,如果是4位数字或以上就不行
[a-z] 表示一个字母
egrep --color "([0-9]\{1,3}\.){3}[0-9]\{1,3}$" test.txt
{} 表示匹配的的次数
([0-9]\{1,3}\.){3} 将前面的形式匹配3次
[^] 匹配一个不在指定范围内的字符 ex: ‘[^A-FH-Z]rep‘ 匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
ls -l |grep ‘^a‘通过管道过滤ls -l 输出的内容,只显示以a开头的行
grep ‘test‘ aa bb cc 显示在aa,bb,cc文件中匹配test行
grep ‘[a-z]/{5/}‘ aa显示所有包含每个字符串至少有5个连续小写字符的字符串的行
grep -c "48" test.txt 统计所有以"48"字符开头的行有多少
grep -i "May" test.txt 不区分大小写查找 "May"所有的行
grep -n "May" test.txt 显示行号
grep -v "48" test.txt 显示输出没有字符"48" 所有的行
([a-z]+[a-z0-9]) 表示匹配任意一个字母 + 任意一个数字或字母
([a-z]+[a-z0-9]+) 这边的+号表示可以匹配多个
grep:查找文件内容
grep "root" filename 查找passwd文件内的root
grep --color "root" filename 给关键字上色
grep -n --color "^root" filename -n:显示行号。查找以root开头的文件内容
grep -n --color "root$" filename 查找以root结尾的文件内容
grep -v "#" filename -v:取反。查找不含#的文件内容
grep -v "#" filename | grep -v "^$" 筛出文件内的空行:以空行开头,以空行结尾
grep "[0-9]" filename 匹配文件内容含0~9数字的内容
grep --color "[0-9][0-9]" filename 匹配文件内连续两个数字,并标记
grep --color "[0-9]{1,3\}" filename 匹配1~3次。格式:{num1,num2\}
当需要匹配IP地址时,注意“.” 在shell中需要加 “\” 转义:
grep --color "[0-9]{1,3\}\." filename 匹配诸如 192.168.0.1 一类的文本。
egrep的使用:
egrep --color "[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}$" filename 这样就可以匹配IP地址了。注意最后是以数字结尾。
简化版:
egrep --color "([0-9]{1,3}\.){3}[0-9]{1,3}$" filename
注:Grep Sed AWK 对文件内容进行匹配 按照行为单位;FIND 对文 件/目录的名称。

Shell编程四剑客包括:find、sed、grep、awk
标签:执行 sed awk 开头 item find查找 mask 非交互 转换 搜索
原文地址:https://www.cnblogs.com/my-first-blog-lgz/p/13612688.html