标签:orm name seconds receive xxx sys dev routes expr
前文写了关于Prometheus + Altermanager实现告警邮件的通知,接下来,实现企业微信告警通知。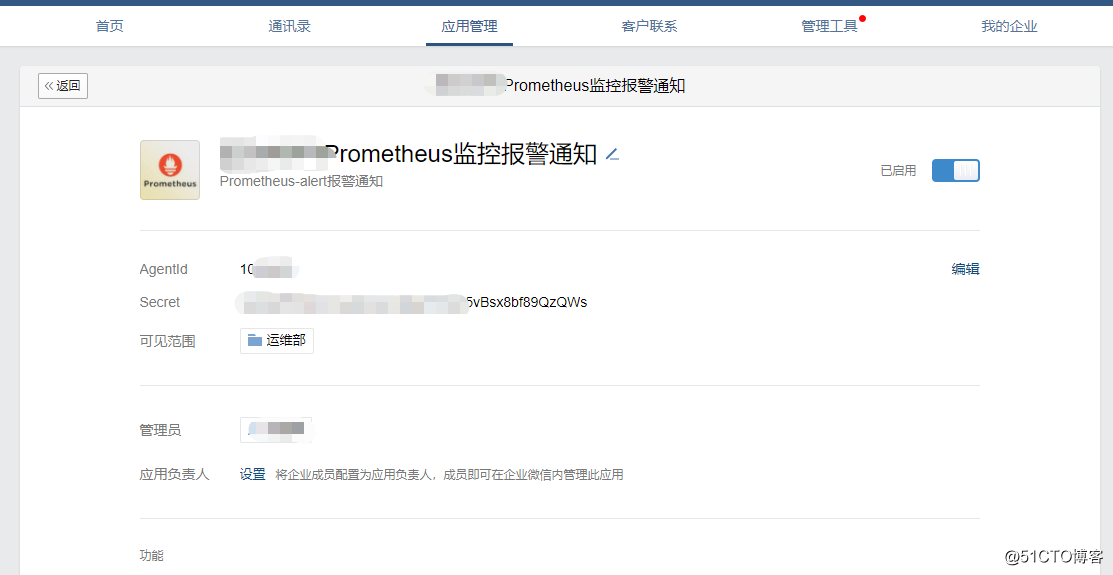
global:
resolve_timeout: 5m
# Email notifications
smtp_smarthost: ‘smtp.hicoco.com:25‘
smtp_from: ‘alter@hicore.com‘
smtp_auth_username: ‘alter@hicoco.com‘
smtp_auth_password: ‘123123‘
smtp_require_tls: false
# wechat templates
templates:
- ‘/data/prometheus/alertmanager/wechat.tmpl‘ # 报警模板地址
route:
group_by: [‘monitor_base‘] # 分组依据
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: wechat # receiver优先接收组,所以接下来优先由wechat发出报警通知。
routes: # route子节点
- receiver: mail
match_re:
level: mail # 匹配到 level 时,mail的使用邮件报警,这里的 level 是rules文件中的labels指定的
group_wait: 10s
receivers:
# email config
- name: ‘mail‘ # 子节点 email 报警配置
email_configs:
- to: ‘kobe@hicorco.com, james@hicoco.com‘ # 配置多个 email 地址
send_resolved: true
# wechat config
- name: ‘wechat‘ # 子节点 wechat 报警配置
wechat_configs:
- corp_id: ‘abc‘ # 企业账户唯一ID,我的企业 -> 企业信息 查看
to_party: ‘2xxx‘ # 发送的组,企业微信中 通信录 -> 选择组 -> 部门ID
agent_id: ‘1xxx‘ # 第三方企业应用ID,创建的第三方企业应用详情中查看
api_secret: ‘abcabc‘ # 第三方企业应用秘钥,创建的第三方企业应用详情中查看
send_resolved: true # 告警解除发送通知
inhibit_rules:
- source_match:
severity: ‘critical‘
target_match:
severity: ‘warning‘
equal: [‘alertname‘, ‘dev‘, ‘instance‘]微信报警模板文件 /data/prometheus/alertmanager/wechat.tmpl。
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
======== 监控报警 ========
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.level }}
告警类型:{{ $alert.Labels.alertname }}
告警应用:{{ $alert.Annotations.summary }}
告警主机:{{ $alert.Labels.instance }}
告警详情:{{ $alert.Annotations.description }}
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} # UTC时间调整为北京时间+8:00
======== END ========
{{ end }}
{{ end }}groups:
- name: monitor_base
rules:
- alert: CpuUsageAlert_waring
expr: sum(avg(irate(node_cpu_seconds_total{mode!=‘idle‘}[5m])) without (cpu)) by (instance) > 0.60
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 60% (current value: {{ $value }})"
- alert: CpuUsageAlert_serious
#expr: sum(avg(irate(node_cpu_seconds_total{mode!=‘idle‘}[5m])) without (cpu)) by (instance) > 0.85
expr: (100 - (avg by (instance) (irate(node_cpu_seconds_total{job=~".*",mode="idle"}[5m])) * 100)) > 85
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} CPU usage high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: MemUsageAlert_waring
expr: avg by(instance) ((1 - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) / node_memory_MemTotal_bytes) * 100) > 70
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{$labels.instance}}: MEM usage is above 70% (current value is: {{ $value }})"
- alert: MemUsageAlert_serious
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.90
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} MEM usage high"
description: "{{ $labels.instance }} MEM usage above 90% (current value: {{ $value }})"
- alert: DiskUsageAlert_warning
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 80
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk usage high"
description: "{{$labels.instance}}: Disk usage is above 80% (current value is: {{ $value }})"
- alert: DiskUsageAlert_serious
expr: (1 - node_filesystem_free_bytes{fstype!="rootfs",mountpoint!="",mountpoint!~"/(run|var|sys|dev).*"} / node_filesystem_size_bytes) * 100 > 90
for: 3m
labels:
level: serious
annotations:
summary: "Instance {{ $labels.instance }} Disk usage high"
description: "{{$labels.instance}}: Disk usage is above 90% (current value is: {{ $value }})"
- alert: NodeFileDescriptorUsage
expr: avg by (instance) (node_filefd_allocated{} / node_filefd_maximum{}) * 100 > 60
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} File Descriptor usage high"
description: "{{$labels.instance}}: File Descriptor usage is above 60% (current value is: {{ $value }})"
- alert: NodeLoad15
expr: avg by (instance) (node_load15{}) > 80
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Load15 usage high"
description: "{{$labels.instance}}: Load15 is above 80 (current value is: {{ $value }})"
- alert: NodeAgentStatus
expr: avg by (instance) (up{}) == 0
for: 2m
labels:
level: warning
annotations:
summary: "{{$labels.instance}}: has been down"
description: "{{$labels.instance}}: Node_Exporter Agent is down (current value is: {{ $value }})"
- alert: NodeProcsBlocked
expr: avg by (instance) (node_procs_blocked{}) > 10
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Process Blocked usage high"
description: "{{$labels.instance}}: Node Blocked Procs detected! above 10 (current value is: {{ $value }})"
- alert: NetworkTransmitRate
#expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50
expr: avg by (instance) (floor(irate(node_network_transmit_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40
for: 1m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Network Transmit Rate usage high"
description: "{{$labels.instance}}: Node Transmit Rate (Upload) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)"
- alert: NetworkReceiveRate
#expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{device="ens192"}[2m]) / 1024 / 1024)) > 50
expr: avg by (instance) (floor(irate(node_network_receive_bytes_total{}[2m]) / 1024 / 1024 * 8 )) > 40
for: 1m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Network Receive Rate usage high"
description: "{{$labels.instance}}: Node Receive Rate (Download) is above 40Mbps/s (current value is: {{ $value }}Mbps/s)"
- alert: DiskReadRate
expr: avg by (instance) (floor(irate(node_disk_read_bytes_total{}[2m]) / 1024 )) > 200
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk Read Rate usage high"
description: "{{$labels.instance}}: Node Disk Read Rate is above 200KB/s (current value is: {{ $value }}KB/s)"
- alert: DiskWriteRate
expr: avg by (instance) (floor(irate(node_disk_written_bytes_total{}[2m]) / 1024 / 1024 )) > 20
for: 2m
labels:
level: warning
annotations:
summary: "Instance {{ $labels.instance }} Disk Write Rate usage high"
description: "{{$labels.instance}}: Node Disk Write Rate is above 20MB/s (current value is: {{ $value }}MB/s)"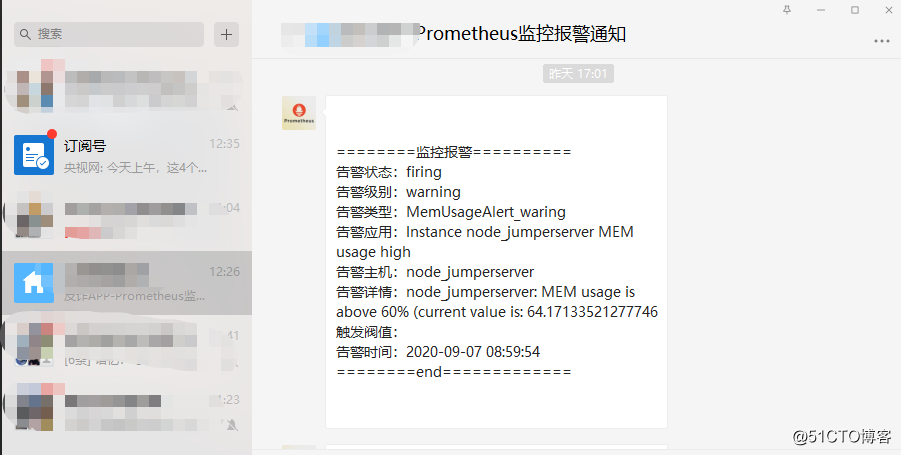
Prometheus + Altermanager实现告警微信通知
标签:orm name seconds receive xxx sys dev routes expr
原文地址:https://blog.51cto.com/10874766/2530127