标签:bridge setting host def poi 附件 简写 lib exe
kubeadm安装k8s集群kubeadm的实现设计请参考:https://github.com/kubernetes/kubeadm/blob/master/docs/design/design_v1.10.md
| 节点网络 | Pod网络 | service网络 |
|---|---|---|
| 192.168.101.0/24 | 10.244.0.0/16(flannel网络默认) | 10.96.0.0/12 |
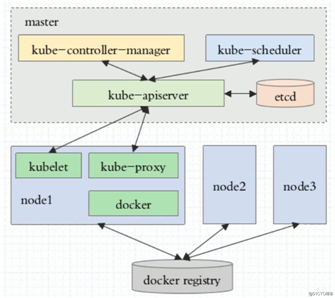
kubeadm init命令初始化,完成主节点的初化。在master节点上把API Server、controller-manager、scheduler和etcd运行成Pod,在各node节点上把kube-proxy也运行成Pod,这些Pod是静态化Pod;kubeadm join把节点加入到集群flannel附件也运行成在各master和nodes节点上,也运行成Pod| 节点角色 | IP地址 |
|---|---|
| master主节点 | 192.168.101.40 |
| node1工作节点 | 192.168.101.41 |
| node2工作节点 | 192.168.101.42 |
三个节点系统环境完全相同
root@node01:~# cat /etc/issue
Ubuntu 18.04.4 LTS \n \l
root@node01:~# uname -r
4.15.0-111-generic
root@node01:~# lsb_release -cr
Release: 18.04
Codename: bionicmaster和node节点上分别执行如下操作
# 禁用swap
# 增加开机启动时关闭swap
# 禁用 /etc/fstab 文件中swap的相关行
root@node01:~# swapoff -a
root@node01:~# vim /etc/rc.local
#/bin/bash
swapoff -a
root@node01:~# chmod +x /etc/rc.local
# 关闭ufw防火墙,如果是centos7系统,则需要关闭firewall,并disable
root@node01:~# systemctl stop ufw.service
root@node01:~# systemctl disable ufw.service
Synchronizing state of ufw.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install disable ufw
root@node01:~# systemctl list-unit-files | grep ufw
ufw.service disabled
# selinux未配置,如果是启用状态,得需要禁用
# 清空iptables规则
root@node01:~# dpkg -l | grep iptables # 默认已安装Iptables管理工具
ii iptables 1.6.1-2ubuntu2 amd64 administration tools for packet filtering and NAT
root@node01:~# iptables -F
root@node01:~# iptables -X
root@node01:~# iptables -Z
# 更改apt源,使用阿里的镜像源
root@node01:~# vim /etc/apt/sources.list
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
# 安装时间同步软件
root@node01:~# apt-get update && apt-get install chrony
# 修正时区
root@node01:~# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 增加aliyun的docker-ce源
root@node01:~# apt-get -y install apt-transport-https ca-certificates curl software-properties-common
root@node01:~# curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
root@node01:~# echo "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" > /etc/apt/sources.list.d/docker-ce.list
# 安装docker-ce
root@node01:~# apt-get update && apt-get install docker-ce
# 增加aliyun的kubernetes镜像源
root@node01:~# apt-get install -y apt-transport-https
root@node01:~# curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
root@node01:~# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
# 在/etc/hosts中增加各个节点的主机解析
192.168.101.40 node01.k8s.com node01
192.168.101.41 node02.k8s.com node02
192.168.101.42 node03.k8s.com node03ubuntu上的iptables不像centos系统上是以服务的形式来管理,iptable只是一个管理工具而已,只需要保证没有启用规则即可。
Ubutu阿里镜像源配置参考:https://developer.aliyun.com/mirror/ubuntu?spm=a2c6h.13651102.0.0.3e221b11HFtiVe
Docker-ce阿里镜像源配置参考:https://developer.aliyun.com/mirror/docker-ce?spm=a2c6h.13651102.0.0.3e221b11O3EaIz
kubernetes阿里镜像配置参考:https://developer.aliyun.com/mirror/kubernetes?spm=a2c6h.13651102.0.0.3e221b11HFtiVe
通过以上的步骤安装的docker-ce为19.03.12版本,对kubernetes来说该版本过高,在这里有说明:
Kubernetes system requirements:
if running on linux:
[error] if not Kernel 3.10+ or 4+ with specific KernelSpec.
[error] if required cgroups subsystem aren‘t in set up.
if using docker:
[error/warning] if Docker endpoint does not exist or does not work, if docker version >17.03. Note: starting from 1.9, kubeadm provides better support for CRI-generic functionality; in that case, docker specific controls are skipped or replaced by similar controls for crictl如果是生产环境,请安装17.03的版本。
root@node01:~# apt-get install kubelet kubeadm kubectl
...
o you want to continue? [Y/n] y
Get:1 http://mirrors.aliyun.com/ubuntu bionic/main amd64 conntrack amd64 1:1.4.4+snapshot20161117-6ubuntu2 [30.6 kB]
Get:2 http://mirrors.aliyun.com/ubuntu bionic/main amd64 socat amd64 1.7.3.2-2ubuntu2 [342 kB]
Get:3 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 cri-tools amd64 1.13.0-01 [8775 kB]
Get:4 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 kubernetes-cni amd64 0.8.6-00 [25.0 MB]
Get:5 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 kubelet amd64 1.18.6-00 [19.4 MB]
Get:6 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 kubectl amd64 1.18.6-00 [8826 kB]
Get:7 https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 kubeadm amd64 1.18.6-00 [8167 kB]
Fetched 70.6 MB in 15s (4599 kB/s)
...kubectl: API Server的客户端工具,node节点上不执行API Server相关命令就不用安装
kubeadm在初始化时会下载一些镜像到本地,而这些镜像是托管在k8s.gcr.io,在大陆地区无法访问。可以想办法搭建一个代理来解决,要让docker deamon在拉取镜像时走代理,配置如下:
root@node01:~# vim /lib/systemd/system/docker.service
[Service]
Environment="HTTPS_PROXY=http://x.x.x.x:10080"
Environment="NO_PROXY=127.0.0.0/8,192.168.101.0/24"
...
# 重新启动docker
root@node01:~# systemctl daemon-reload
root@node01:~# systemctl stop docker
root@node01:~# systemctl start docker确保关于iptable的两个内核参数值为1
root@node01:~# cat /proc/sys/net/bridge/bridge-nf-call-iptables
1
root@node01:~# cat /proc/sys/net/bridge/bridge-nf-call-ip6tables
1确保kubelet服务设置为开机启动,但当前处理关闭状态
root@node01:~# systemctl is-enabled kubelet
enabled
增加docker运行加载参数
root@node01:~# vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
....
}如果不加此选项,那kubeadm init在初始化时会有警告信息,并且初始化失败,警告信息如下:
...
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
...
[kubelet-check] It seems like the kubelet isn‘t running or healthy.
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz‘ failed with error: Get http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn‘t running or healthy.
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz‘ failed with error: Get http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn‘t running or healthy.
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz‘ failed with error: Get http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn‘t running or healthy.
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz‘ failed with error: Get http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn‘t running or healthy.
[kubelet-check] The HTTP call equal to ‘curl -sSL http://localhost:10248/healthz‘ failed with error: Get http://localhost:10248/healthz: dial tcp 127.0.0.1:10248: connect: connection refused.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- ‘systemctl status kubelet‘
- ‘journalctl -xeu kubelet‘
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in docker:
- ‘docker ps -a | grep kube | grep -v pause‘
Once you have found the failing container, you can inspect its logs with:
- ‘docker logs CONTAINERID‘初始化kubernetes
# 查看需要拉取哪些镜像
root@node01:~# kubeadm config images list
W0725 13:02:07.511180 6409 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
k8s.gcr.io/kube-apiserver:v1.18.6
k8s.gcr.io/kube-controller-manager:v1.18.6
k8s.gcr.io/kube-scheduler:v1.18.6
k8s.gcr.io/kube-proxy:v1.18.6
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.7
# 先拉取所需要的镜像
root@node01:~# kubeadm config images pull
W0722 16:17:21.699535 8329 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[config/images] Pulled k8s.gcr.io/kube-apiserver:v1.18.6
[config/images] Pulled k8s.gcr.io/kube-controller-manager:v1.18.6
[config/images] Pulled k8s.gcr.io/kube-scheduler:v1.18.6
[config/images] Pulled k8s.gcr.io/kube-proxy:v1.18.6
[config/images] Pulled k8s.gcr.io/pause:3.2
[config/images] Pulled k8s.gcr.io/etcd:3.4.3-0
[config/images] Pulled k8s.gcr.io/coredns:1.6.7
# 初始化为master
root@node01:~# kubeadm init --kubernetes-version=v1.18.6 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12
W0722 17:02:21.625550 25074 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.18.6
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ‘kubeadm config images pull‘
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [node01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.101.40]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [node01 localhost] and IPs [192.168.101.40 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [node01 localhost] and IPs [192.168.101.40 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0722 17:02:25.619105 25074 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0722 17:02:25.620260 25074 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 25.005958 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.18" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node node01 as control-plane by adding the label "node-role.kubernetes.io/master=‘‘"
[mark-control-plane] Marking the node node01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: ri964b.aos1fa4h7y2zmu5g
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.101.40:6443 --token ri964b.aos1fa4h7y2zmu5g --discovery-token-ca-cert-hash sha256:c7c8e629116b4bda1af8ad83236291f1a38ca01bb0abd8a7a8a46c286547d609注意:
kubeadm join 192.168.101.40:6443 --token ri964b.aos1fa4h7y2zmu5g --discovery-token-ca-cert-hash sha256:c7c8e629116b4bda1af8ad83236291f1a38ca01bb0abd8a7a8a46c286547d609
这个增加工作节点命令中的“token”是有时效性的,默认为24小时,过期后在增加工作节点时出现“error execution phase preflight: couldn‘t validate the identity of the API Server: could not find a JWS signature in the cluster-info ConfigMap for token ID...”这样的错误,那就说明token过期了,解决办法:
在master节点上使用“kubeadm token create --ttl 0”来生成新的token,其中“--ttl 0”表示token不过期,根据需要看是否增加此选项。"kubeadm token list"列出token有哪些。master节点初始化完成,按照提示创建创建一个普通用户来管理kubernetes集群
root@node01:~# adduser k8s
# 配置sudo权限
root@node01:~# visudo
# 增加一行
k8s ALL=(ALL) NOPASSWD:ALL
#
k8s@node01:~$ mkdir -p $HOME/.kube
k8s@node01:~$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
k8s@node01:~$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
k8s@node01:~$ ls -al .kube/config
-rw------- 1 k8s k8s 5454 Jul 22 17:37 .kube/config此时查看集群状态,节点状态,运行Pod信息都是有问题的,如下
# 集群状态不健康
k8s@node01:~$ sudo kubectl get componentstatus
NAME STATUS MESSAGE ERROR
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: connect: connection refused
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Healthy {"health":"true"}
# 有两个Pod没有正常运行
k8s@node01:~$ sudo kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-7dr57 0/1 Pending 0 85m
coredns-66bff467f8-xzf9p 0/1 Pending 0 85m
etcd-node01 1/1 Running 0 85m
kube-apiserver-node01 1/1 Running 0 85m
kube-controller-manager-node01 1/1 Running 0 85m
kube-proxy-vlbxb 1/1 Running 0 85m
kube-scheduler-node01 1/1 Running 0 85m
# master节点也是未就绪状态
k8s@node01:~$ sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 NotReady master 49m v1.18.6后两个问题都将在安装网络插件flannel后得到解决。
安装网络插件flannel
k8s@node01:~$ sudo kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x createddocker安装好后默认使用的Cgroup Driver为cgroupfs,如下
root@node03:/var/lib/kubelet# docker info | grep -i cgroup
Cgroup Driver: cgroupfs而kuebelet默认使用的Cgroup Driver为systemd,所以kubelet与docker使用的驱动要一致才能正常的协调工作,在初始化master时,是修改的/etc/docker/daemon.json文件,给docker daemon传递一个参数让其Cgroup Driver设置为systemd,也可以修改kubelet的启动参数,让其工作在cgroupfs模式,确保以下配置文件中--cgroup-driver=cgroupfs即可
$ cat /var/lib/kubelet/kubeadm-flags.env
KUBELET_KUBEADM_ARGS="--cgroup-driver=cgroupfs --network-plugin=cni --pod-infra-container-image=k8s.gcr.io/pause:3.2 --resolv-conf=/run/systemd/resolve/resolv.conf"工作节点node03就是以这种方式加入到集群的。
kubectl get componentstatus可简写为kubectl cs 列出集群健康状态信息
kubectl get nodes 列出集群节点信息
kubectl get pods -n kube-system 列出名称空间为“kube-system”中Pod的运行状态
kubectl get ns 列出集群的名称空间
kubectl get deployment -w 实时监控deployment的信息
kubectl describe node NODENAME 查看一个节点的详细信息
kubectl cluster-info 集群信息
kubectl get services简写为kubectl get svc 列出services
kubectl get pods --show-labels 显示pods资源时一并显示相应的标签信息
kubectl edit svc SERVICE_NAME 修改一个服务的运行中的信息
kubectl describe deployment DEPLOYMENT_NAME 显示指定deployment的详细信息
# 安装所需要组件
root@node02:~# apt-get update && apt-get -y install kubelet kubeadm
# 复制master节点上的/etc/docker/daemon.json文件,主要是配置“"exec-opts": ["native.cgroupdriver=systemd"],”,否则
# kubelet无法启动,配置更改后重启docker
# 设置开机启动
oot@node02:~# systemctl enable docker kubelet
# 加入集群
root@node02:~# kubeadm join 192.168.101.40:6443 --token ri964b.aos1fa4h7y2zmu5g --discovery-token-ca-cert-hash sha256:c7c8e629116b4bda1af8ad83236291f1a38ca01bb0abd8a7a8a46c286547d609
W0722 18:42:58.676548 25113 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -oyaml‘
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run ‘kubectl get nodes‘ on the control-plane to see this node join the cluster.再回到master节点查看状态信息
# 集群状态已就绪
k8s@node01:~$ sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready master 117m v1.18.6
node02 Ready <none> 24m v1.18.6
# 各Pod已正常运行
k8s@node01:~$ sudo kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-66bff467f8-7dr57 1/1 Running 0 116m 10.244.1.3 node02 <none> <none>
coredns-66bff467f8-xzf9p 1/1 Running 0 116m 10.244.1.2 node02 <none> <none>
etcd-node01 1/1 Running 0 116m 192.168.101.40 node01 <none> <none>
kube-apiserver-node01 1/1 Running 0 116m 192.168.101.40 node01 <none> <none>
kube-controller-manager-node01 1/1 Running 0 116m 192.168.101.40 node01 <none> <none>
kube-flannel-ds-amd64-djjs7 1/1 Running 0 6m35s 192.168.101.41 node02 <none> <none>
kube-flannel-ds-amd64-hthnk 1/1 Running 0 6m35s 192.168.101.40 node01 <none> <none>
kube-proxy-r2v2p 1/1 Running 0 23m 192.168.101.41 node02 <none> <none>
kube-proxy-vlbxb 1/1 Running 0 116m 192.168.101.40 node01 <none> <none>
kube-scheduler-node01 1/1 Running 0 116m 192.168.101.40 node01 <none> <none>node03以同样的方式加入到集群,最终集群状态如下
k8s@node01:~$ sudo kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready master 124m v1.18.6
node02 Ready <none> 31m v1.18.6
node03 Ready <none> 47s v1.18.6如果想移除集群中的节点依次进行如下操作
k8s@node01:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready master 12d v1.18.6
node02 Ready <none> 12d v1.18.6
node03 Ready <none> 12d v1.18.6
node04 Ready <none> 24h v1.18.6 # 需要移除node04节点
# 迁移node04节点上的pod,daemonset类型的pod不用迁移
k8s@node01:~$ kubectl drain node04 --delete-local-data --force --ignore-daemonsets
node/node04 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/canal-ggt5n, kube-system/kube-flannel-ds-amd64-xhksw, kube-system/kube-proxy-g9rpd
node/node04 drained
k8s@node01:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready master 12d v1.18.6
node02 Ready <none> 12d v1.18.6
node03 Ready <none> 12d v1.18.6
node04 Ready,SchedulingDisabled <none> 24h v1.18.6
k8s@node01:~$ kubectl delete nodes node04
node "node04" deleted
k8s@node01:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready master 12d v1.18.6
node02 Ready <none> 12d v1.18.6
node03 Ready <none> 12d v1.18.6
# 再到node04节点上执行
root@node01:~# kubeadm resetmaster初始化完成后,以下两个组件状态显示依然为Unhealthy
k8s@node01:~$ sudo kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: connect: connection refused
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: connect: connection refused
etcd-0 Healthy {"health":"true"}网络搜寻说是controller-manager与scheduler两个组件运行所在节点与执行kubectl get cs的节点不是同一个节点,所以才导致访问http://127.0.0.1:10252失败,但我这里执行`kubectl get cs命令的节点与controller-manager与scheduler两个组件运行的节点都是node01节点,但经测试不影响集群使用。
问题处理思路:
先查看master节点的确没有监听10251与10252这两个端口
查看两个组件的Pod是否正常运行
k8s@node01:~$ sudo kubectl get pods -n kube-system -o wide | grep ‘scheduler\|controller-manager‘
kube-controller-manager-node01 1/1 Running 1 7m42s 192.168.101.40 node01 <none> <none>
kube-scheduler-node01 1/1 Running 0 6h32m 192.168.101.40 node01 <none> <none>两个组件已正常运行
那的确是两个组件的相应Pod运行时没有监听相应的端口,那得找到运行两个组件的配置文件,在主节点初化时的输出信息中在/etc/kubernetes/manifests目录下创建了各个组件的相应静态Pod的清单文件,从这里入手
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0722 17:02:25.619105 25074 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"k8s@node01:~$ ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml修改清单文件,去掉--port=0这一行,在对清单文件进行修改时先做备份操作
注意:
在对清单文件做备份时,不要直接把清单文件备份在平级目录里,即/etc/kubernetes/manifests目录,需要备份到其他目录中或在平级目录再创建一个类似/etc/kubernetes/manifests/bak的备份目录,否则按照以下操作后master节点上依然无法监听10251和10252两个端口,组件健康状态依然无法恢复为health状态。
k8s@node01:~$ sudo vim /etc/kubernetes/manifests/kube-controller-manager.yaml
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=127.0.0.1
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.244.0.0/16
- --cluster-name=kubernetes
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --node-cidr-mask-size=24
- --port=0 ########################## 删除这行 #########
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --root-ca-file=/etc/kubernetes/pki/ca.crt
- --service-account-private-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=10.96.0.0/12
- --use-service-account-credentials=true
k8s@node01:~$ sudo vim /etc/kubernetes/manifests/kube-scheduler.yaml
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=127.0.0.1
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
- --port=0 ########### 删除这行 #################
# 重启kubelet服务
k8s@node01:~$ sudo systemctl restart kubelet
# 查看监听监听端口以及组件状态
k8s@node01:~$ sudo ss -tanlp | grep ‘10251\|10252‘
LISTEN 0 128 *:10251 *:* users:(("kube-scheduler",pid=51054,fd=5))
LISTEN 0 128 *:10252 *:* users:(("kube-controller",pid=51100,fd=5))
k8s@node01:~$ sudo kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}至此,kubernetes单master集群安装完成。master HA的安装请参考官方文档:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/high-availability/
标签:bridge setting host def poi 附件 简写 lib exe
原文地址:https://blog.51cto.com/zhaochj/2530901