标签:后台 sql 进一步 数据 线程 必须 cas sql语句 隔离
内容总结自《MySQL技术内幕InnoDB存储引擎》第2版。
数据库:是一个操作系统文件,frm、MYD、MYI、ibd 等为结尾的文件。
实例:MySQL 由后台线程和一个共享内存区组成。真正用于操作数据库文件。
MySQL 被设计为一个单进程多线程的数据库。
存储引擎是基于表的,而不是数据库。
数据操纵语言 DML(Data Manipulation Language),用户通过它可以实现对数据库的基本操作。
数据完整性:
约束:
约束和索引的区别:
当用户创建了一个唯一的索引就创建了一个唯一的约束。但是约束和索引的概念是不同的。约束更是一个逻辑上的概念,用来保证数据完整性;而索引是一个数据结构,既有逻辑上的概念,在数据库中还代表着物理存储的方式。
外键约束:
foreign key (parent_id) refereces parent(id)
可以定义on delete 或者on update表示在父表进行delete或者update操作时,对子表所作的操作:
缺点:数据导入时,每一行都会进行外键检查,花费大量的时间(使用set foreign_key_checks=0可以避免外键检查)
支持事务,支持全文索引
特点:行级锁、支持外键、非锁定读、MVCC。
架构:InnoDB 由若干后台线程、缓存池、文件组成。
把缓冲池中的数据异步刷新到磁盘,保证数据一致性
处理 IO 请求
事务提交后,回收不再使用的 Undo 页
脏页刷新
InnoDB 将其中的记录按照页的方式进行管理,页默认大小为 16KB。
数据库怎么读取页?
数据库怎么修改页?
缓冲池中缓存的数据页有:
如何管理缓冲池?(通过 show engine innodb status 可以看到这些管理列表)
Write Ahead Log 策略
为了避免脏页刷新回数据库的时候,发生宕机,造成数据库不可恢复的问题,普遍采用 Write Ahead Log 策略。
当事务提交时,先写重做日志,再修改页。当由于数据库宕机而引发数据丢失时,可以通过重做日志来完成数据的恢复。这是 ACID 中 D 的要求。
CHECKPOINT 机制
试想,如果数据库更新的时候发生宕机,需要通过重做日志来恢复整个数据库,如果:
显然不可能恢复整个数据库。
因此,CHECKPOINT 机制用来解决上述问题:
当数据库发生宕机时,数据库不需要重做所有的日志,因为 CHECKPOINT 机制确保 CHECKPOINT 之前的页都已经刷新回磁盘。故数据库只需要对 CHECKPOINT 之后的重做日志进行恢复。当缓冲池不够用时, LRU 会移出最近最少使用的页,如果这个页是脏页,那么需要强制执行 CHECKPOINT ,将脏页刷新回磁盘。
有两种 CHECKPOINT :
(Innodb关键特性)自适应哈希索引
B+树查找次数取决于B+树的高度,一般B+树高度在3-4层,需要3-4次查询。
自适应哈希索引(Adaptive Hash Index):Innodb存储引擎监控表上个索引页的查询,如果观察到建立哈希所以可以带来速度提升,则会根据访问的频率和模式来自动地为某些热点页建立哈希索引,称为自适应哈希索引。例如,对于(a,b)这样的联合索引页,其访问模式可以是:
访问模式一样要求的是查询条件一样,如果交替进行上述两种查询,那么Innodb不会为之建立AHI。此外,AHI对频率要求如下:
注意:AHI只能用来搜索等值(=)的查询,而对于其他类型查找,如:范围查找,是不能使用哈希索引的。
(Innodb关键特性)异步IO(AIO)
用户可以在发出一个IO请求后立即再发出另一个IO请求,当全部IO请求发送完毕后,等待所有的IO操作完成,而不必按顺序的等待前一个IO完成,是为AIO。
InnoDB支持以下常见索引:
B+树索引并不能直接找到给定键值所在的具体行,而是找到数据行所在的页,然后数据库把页读到内存,再在内存中进行查找(页内空间连续且顺序,二分查找),最后得到想要的数据。
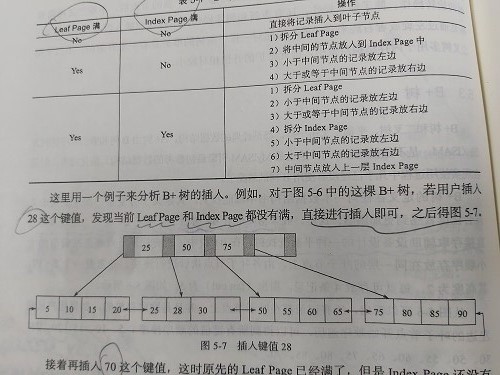
B+树节点插入:
| Leaf Page | Index Page | 操作 |
| 不满 | 不满 | 直接将记录插入叶子节点 |
| 满 | 不满 |
1. 拆分 Leaf Page为左右两个 2. 将中间的节点放到Index Page中 3. 小于中间节点的记录放在左Leaf Page 4. 大于中间节点的记录放在右Leaf Page |
| 满 | 满 |
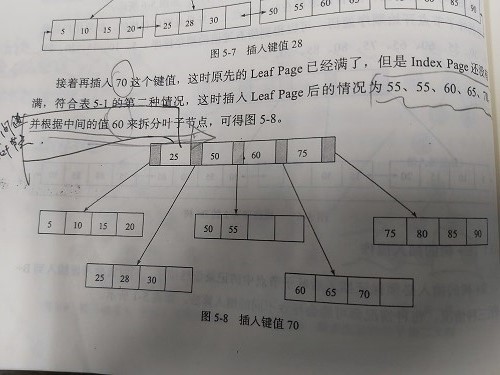
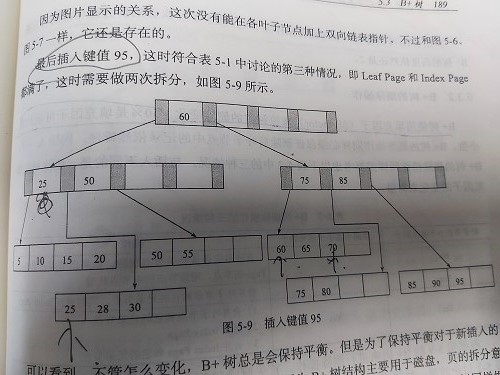
1. 拆分 Leaf Page为左右 2. 小于中间节点的记录放在左Leaf Page 3. 大于中间节点的记录放在右Leaf Page 4. 拆分 Index Page为左右 5. 小于中间节点的记录放在左Index Page 6. 大于中间节点的记录放在右Index Page 7. 中间节点放入上一层Index Page |
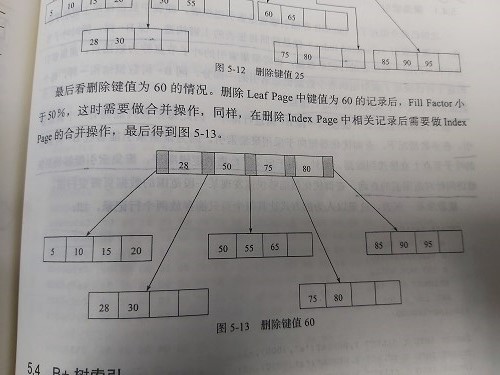
B+树节点删除:
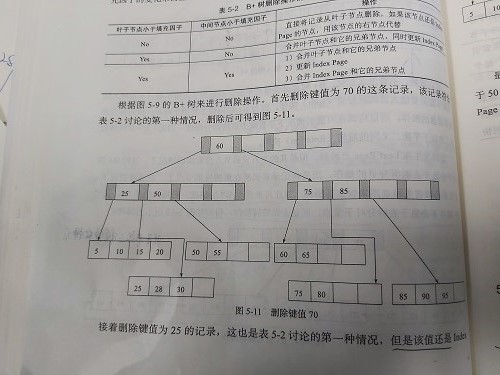
| 叶节点小于填充因子 | 中间节点小于填充因子 | 操作 |
| no | no | 直接将记录从叶子节点删除,若该节点是Index Page的节点,用该节点的右节点代替 |
| yes | no | 合并叶子节点和它的兄弟节点,同时更新Index Page |
| yes | yes |
1. 合并叶子节点和它的兄弟节点 2. 更新Index Page 3. 合并Index Page和他的兄弟节点 |
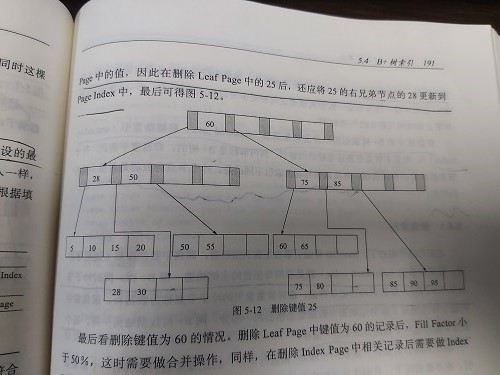
按照表的主键构建一颗二B+树,每张表最多有一个聚集索引。聚集索引的存储物理上并不一定连续,但逻辑上是连续的。
优点:
聚集索引对主键的排序查找特别快:例如,一张注册用户表,要查找最后10位注册的用户,用户可以快速定位最后一个数据页,并取出其中的最后10条记录(select * from regesters_tb order by id limit 10)。
和范围查找特别快(由上层B+树索引就可以大致确定页的范围,然后在页(叶节点)中进行范围内的顺序查找即可)
叶子节点并不包含行记录的全部数据,它包含键值(并非主键)和一个书签。该书签即相应行数据的聚集索引键。每张表可以有多个辅助索引。
alter table t add key idx_name(name) // 为name属性创建辅助索引,辅助索引名字为idx_name
drop index idx_name on name
show index from t
对于高选择性的字段,它们可取值的范围非常广,几乎没有重复,为它们建立索引是合适的。
例如:id,phone_number
对于低选择性的字段,它们取值范围窄。为它们建立索引是不合适的。
例如:sex(性别)
Cardinality值可以预估一个字段的选择性高低,通过show index 可以查到这个值(通过随机采样的方法,样品中的非重复个数),Cardinality/n_rows_in_table应尽可能等于1。
联合索引是指对表上的多个列进行索引.
create table t(
a int,
b int,
primary key(a),
key idx_ab(a, b)
)engine = innodb
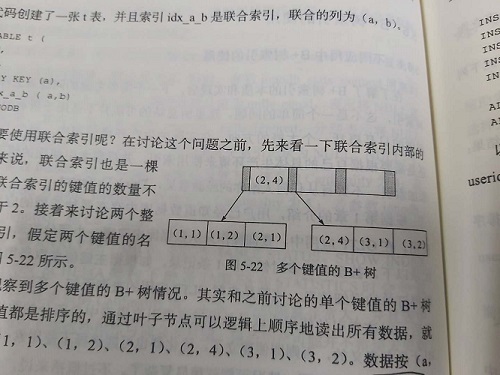
数据按照(a,b)的顺序进行了排列(先根据a再根据b排序)。
对于查询:
where a = xx and b = yy,可以使用此联合查询
where a = xx,可以使用此联合查询
where a = xx order by b,可以使用此联合查询快速的查找数据
而对于查询:
where b = xx,不可以使用此联合查询
从辅助索引中就可以得到查询的记录,而不需要再查询聚集索引中的记录。
优点:
辅助索引不包含整行记录的所有信息,所以大小远小于聚集索引,因此可以减少大量IO操作。
什么时候选择覆盖索引优化?
如果查询不需要知道该行记录的具体内容,只需要知道一些统计信息例如:个数,那么根据辅助索引即可得到统计结果,而不用进一步使用聚集索引找到具体行记录,那么此时使用覆盖索引优化。
select count(*) from tb_1
note:使用explain可以得到执行计划
全文检索通常使用倒排索引来实现。它存储了单词与单词自身在一个或多个文档中所在位置之间的映射(通常使用关联数组):
lock的对象是事务,用来锁定数据库中的表、页、行等。
Innodb实现了两种标准的行级锁:
共享锁(s lock):允许事务读一行数据
排它锁(x lock):允许事务删除或更新一行数据
| X | S | |
| X | 不兼容 | 不兼容 |
| S | 不兼容 | 兼容 |
多粒度锁(意向锁):
允许事务在行级和表级上的锁同时存在。称之为意向锁,分为:
意向共享锁(IS lock),事务想要获得一张表中某几行的共享锁
意向排它锁(IX lock),事务想要获得一张表中某几行的排他锁
| IS | IX | S | X | |
| IS | 兼容 | 兼容 | 兼容 | 不兼容 |
| IX | 兼容 | 兼容 | 不兼容 | 不兼容 |
| S | 兼容 | 不兼容 | 兼容 | 不兼容 |
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
如果需要对页上的记录上X锁,首先要对对应的数据库、表、页上IX锁,如果其中任何一个部分等待,那么该操作需要等待粗粒度锁的完成。
数据库默认隔离级别为RR,使用一致性非锁定读。
一致性非锁定读是指InnoDB存储引擎通过MVCC的方法来读取当前执行时间数据库中行的数据。
如果读取的行正在执行update或者delete操作,这时读取操作不会等待锁的释放,而是读取行的一个内存快照。
在RC事务隔离级别下,对于快照数据,非一致性锁定读总是读取被锁定行的最新一份数据快照。
在RR事务隔离级别下,对于快照数据,非一致性锁定读读取事务开始时对应的行数据版本。
InnoDB对于select支持两种一致性的锁定读操作:
注意:如果不对上述两条语句开启事务,那么仍然使用一致性非锁定读进行读取,因为锁的对象是事务,当事务提交了,锁就释放了。
因此,使用上述语句必须加上 begin,start transaction
对于外键的更新,首先要使用select定位父表中记录,但是此select使用的是select xx lock in share mode。如果父表中对应行记录正在进行update或者delete操作,加了X锁,那么操作子表的事务就会阻塞,直到父表事务释放X锁。
Record Lock:单个行记录上的锁(RC隔离级别下默认)
Gap Lock:间隙锁,锁定一个范围,但不包含记录本身(RR隔离级别下默认)
Next-Key Lock:锁定一个范围,同时锁定记录本身(RR隔离级别下,使用此种算法避免幻读)(当查询的索引含有唯一属性时,会降级为Record Lock,锁住索引本身)
Next-Key Lock降级为Record Lock示例:
| 时间 | 事务A | 事务B |
| 1 | begin; | |
| 2 |
select * from t where a = 5 for update; |
|
| 3 | begin; | |
| 4 | insert into t select 4; | |
| 5 |
commit; #成功,无需等待 |
|
| 6 | commit; |
phantom problem(幻象问题):在同一事务下,连续执行两次同样的SQL语句,可能导致不同的结果,第二次的SQL语句可能会返回之前不存在的行。
| 时间 | 事务1 | 事务2 |
| 1 | begin; | |
| 2 |
select * from z_tb where b > 2 for update; #输出4 |
|
| 3 |
begin; |
|
| 4 |
|
insert into z_tb select 4; #阻塞 |
| 5 |
commit; |
|
| 6 |
select * from z_tb where b > 2 for update; #输出a:4 |
事务1where条件为>2,实际上对(2,正无穷)加了X锁,因此任何对于这个范围的插入都不是允许的,从而避免了幻读问题。
| 锁问题 | 发生条件 | 解决 | 本质 |
| 脏读 | 隔离级别 <= READ UNCOMMITED | READ COMMITED | 读到了未提交事务更改的数据 |
| 不可重复读 | 隔离级别 <= READ COMMITED | READ REPEATABLE | 读到已提交事务更改的数据(两个事务同时开启) |
| 丢失更新 |
事务1查询一行数据,放入本地内存,并显示给一个终端用户user1 事务2查询同一行数据,并显示给一个终端用户user2 user1修改这行记录,更新数据库并提交(更新丢失) user2修改这行记录,更新数据库并提交(更新生效) |
串行化(加x锁) | 一个事务的更新结果被另一个事务覆盖 |
概念:两个或两个以上的事务在执行过程中,因争夺资源而造成的一种相互等待的现象。
数据库使用wait-for graph(等待图)的方式进行死锁检测,具体为数据库保存两个信息:
如果事务A等待事务B所占的资源,那么A到B存在一条有向边。
如果等待图中存在回路,则存在死锁。
解决死锁:回滚undo量最小的事务。
死锁示例:
| 时间 | 事务1 | 事务2 |
| 1 | begin; | |
| 2 |
select * from t where a = 1 for update; |
begin; |
| 3 |
select * from t where a = 2 for update; |
|
| 4 |
select * from t where a = 2 for update; #等待 |
|
| 5 |
select * from t where a = 1 for update; #死锁 |
不支持事务、不支持表锁,支持全文索引。
MyISAM 由 MYI 和 MYD 组成,MYD 用来存储数据文件,MYI 用来存储索引文件。只查询而不需要业务的场景可以使用MyISAM引擎。
标签:后台 sql 进一步 数据 线程 必须 cas sql语句 隔离
原文地址:https://www.cnblogs.com/icky1024/p/mysql-innodb1.html