标签:个数 姓名 关于 字段 控制 级别 自己 normal 例子
事务就是满足 ACID 特性的一组操作,可以用 commit 提交一个事务,也可以用 rollback 回滚事务。
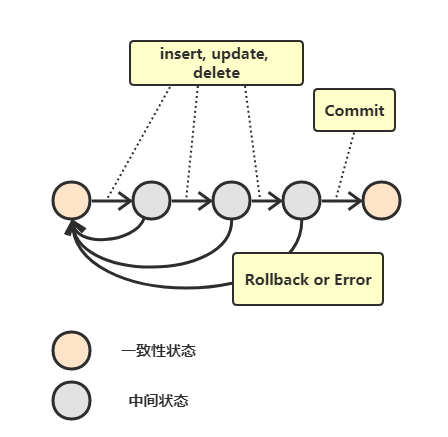
AUTOCOMMIT
MySQL 默认 自动提交模式。也就是说,如果不显式使用 START TRANSACTION 语句来开始一个事务,那么每个查询都会被当做一个事务自动提交
MySQL 支持多种存储引擎,甚至你可以自己写一个专属的存储引擎,可以看一下 MySQL 的多存储引擎架构
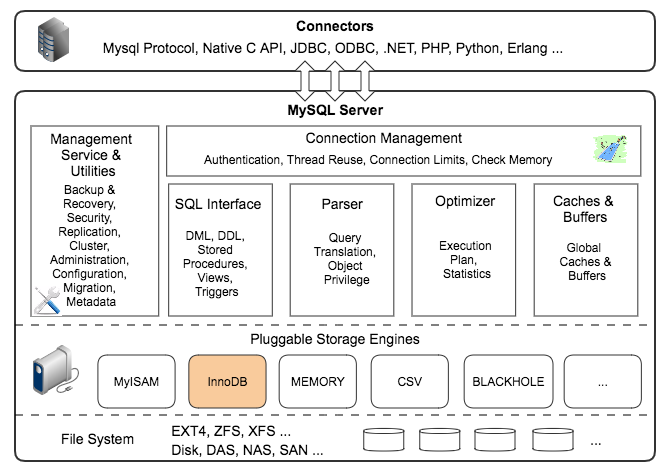
MySQL 中的数据用各种不同的技术存储在文件或内存中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁实现并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。存储引擎其实就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
如何选择引擎?
MySQL 5.5 以前的默认存储引擎是 MyISAM, 5.5 之后换成了 Innodb。
特性:
应用场景:
特性
应用场景
MySQL 中的引擎只是一个插件,如果技术好且有需要,甚至自己写一个引擎来使用也是可以的。在这里列举一些别的引擎,特性就不去看了,以后如果有机会用到再写
CSV
Archive
Memory
Merge
MaxDB
整数包括了 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT;
占用内存空间的情况
| TINYINT | SMALLINT | MEDIUMINT | INT | BIGINT |
|---|---|---|---|---|
| 1 byte | 2byte | 3 byte | 4 byte | 8 byte |
INT(1)、INT(10) 中的数字只是规定显示字符的个数,但是对于存储和计算是没有影响的。
浮点数包括 FLOAT 和 DOUBLE,还有一个 DECIMAL,是高精度小数类型,可以存比 BIGINT 还大的整数,因为 DECIMAL 是用字符串来保存的。。。。
还有关于单精度和双精度也记录一下
| 类型 | 符号位 | 指数位 | 小数位 |
|---|---|---|---|
| 单精度 | 1 位 | 8 位 | 23 位 |
| 双精度 | 1 位 | 11 位 | 52 位 |
字符串包括 char 和 varchar,区别在于 char 是定长的,而 varchar 是变长的,varchar 会根据实际需要的大小来进行存储,但是会额外占用一个字节(长度超过 255 时会占用两个字节)。
VARCHAR 会保留字符串末尾的空格,而 CHAR 会删除。
datetime 和 timestamp
datetime 与时区无关,而 timestamp 与时区有关
基于Innodb引擎
MySQL 中选择索引是优化器的工作,如果有多个索引都可以查到数据,优化器会估算使用每个索引的成本然后进行选择。
创建索引有 3 种方式
直接创建
create index indexName on tableName(columnName(lenth));
在建表的时候创建索引
create table tableName (
id int not null,
columnName varchar(16) not null,
key indexName (columnName),
);
修改表结构
alter table tableName add index indexName(columnName);
这里还遇到个小问题,之前一直没有注意过,原来 MySQL 中有 key 和 index 两个关键字,但是他们其实是一样的,在官方有介绍:
KEY is normally a synonym for INDEX. The key attribute PRIMARY KEY can also be specified as just KEY when given in a column definition. This was implemented for compatibility with other database systems.
唯一索引是指索引列没有重复的索引,包括了主键索引和其它索引。
主键索引也可以称作聚簇索引,我们都知道,Innodb 底层是用 B+ 树实现的,在叶子节点存储的是数据,并且每一条数据肯定都有对应的键。如果在建表的时候没有指定主键索引,MySQL 会自动生成一个自增的主键。用一张图来展示一下数据在主键中的存储情况。
泛指定义为唯一索引但是又不是主键索引的索引
创建唯一索引的方式和上面类似,只不过需要多一个 unique 关键字,而且 Innodb 引擎允许唯一索引值为 null。
初始化表
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT ‘‘,
index k(k))
engine=InnoDB;
insert into T values(100,1, ‘aa‘),(200,2,‘bb‘),(300,3,‘cc‘),(500,5,‘ee‘),(600,6,‘ff‘),(700,7,‘gg‘);
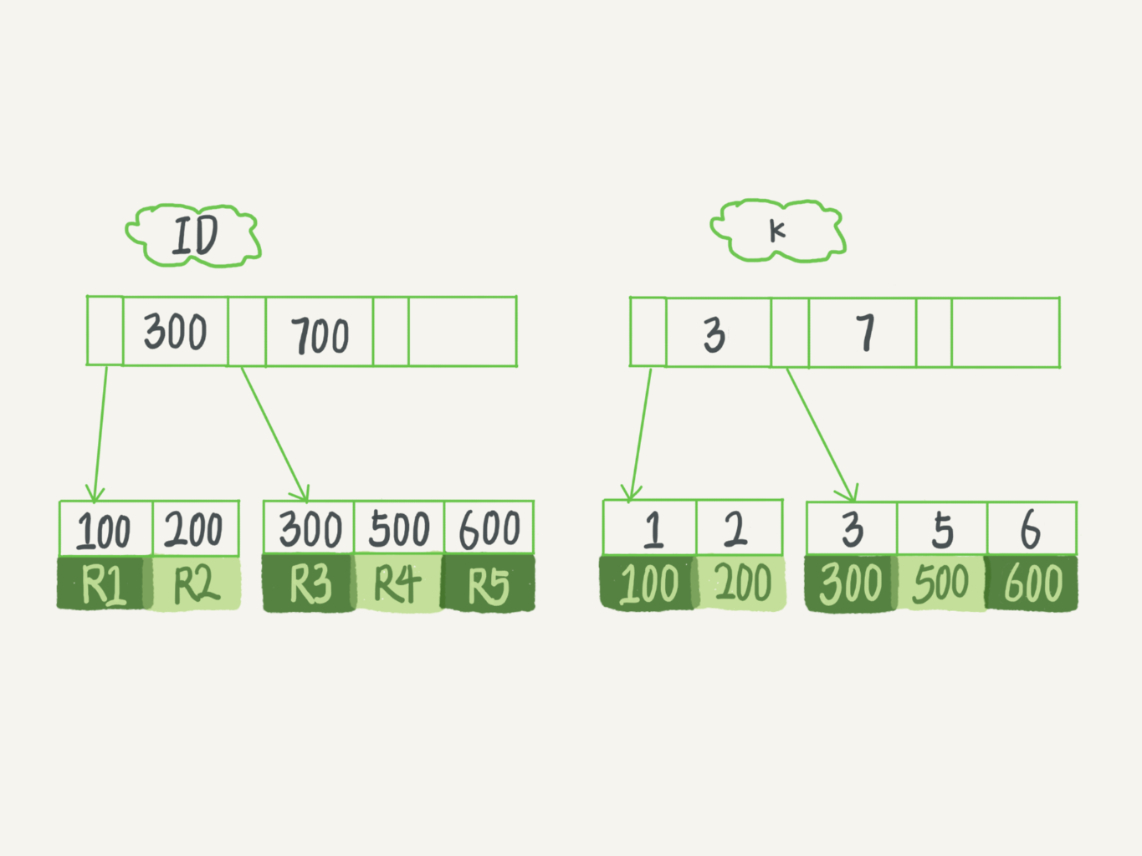
图片来自极客时间专栏,丁奇老师的《MySQL45讲》真的很赞。
如果在上面的表中执行这条语句 select * from T where k between 3 and 5 执行流程是怎样的呢?
普通索引没有索引列必须唯一的限制。
在查询的时候,唯一索引和普通索引还是有点区别的。如果使用的是普通索引,那么查询语句会在找到第一个不满足条件的时候结束查询,而唯一索引只要找到一个满足条件就会结束查询。不过在查询方面,唯一索引和普通索引的消耗是差不多的,因为在 MySQL 中数据是按页存储的,一次读入一整页,一页可以存上千条 key,但是再更新的时候,两者就有区别了。
文章开头创建的索引都是只有一列的,也叫单列索引,而覆盖索引也叫多列索引。借用丁奇老师的例子,对一个城市中的市民建立索引,如果用名字来做索引肯定不行,重名的人很多,还需要其他的判断条件来进行筛选。既然如此,可以选择用身份证号码来做索引,但是这也会有一个问题,如果我要查询的是姓名,但是索引里只有身份证号,这个时候就需要回表去主键索引上查找,多了一次查询。为了解决这个问题,就可以用姓名和身份证号建立联合索引,减少一个回表的消耗。
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`) //覆盖索引必须保证索引列没有重复
) ENGINE=InnoDB
要知道,索引在存储的时候是有序的,对于多列索引而言,先保证第一列有序,然后在此基础上第二列有序,以此类推。因此在使用多列索引的时候,会先对第一列索引字段进行匹配,然后再匹配第二列。
公众号:没有梦想的阿巧 后台回复 "群聊",一起学习,一起进步
标签:个数 姓名 关于 字段 控制 级别 自己 normal 例子
原文地址:https://www.cnblogs.com/beyondexp/p/13774300.html