标签:更新 引入 延迟 str 事务 效果 内容 ott otto
1、主从复制之异步复制
MySQL主从异步复制是最常见的复制场景。数据的完整性依赖于主库BINLOG的不丢失,只要主库的BINLOG不丢失,那么就算主库宕机了,我们还可以通过BINLOG把丢失的部分数据通过手工同步到从库上去。
传统的MySQL复制采用主从的方式进行,可以一主一从也可以一主多从,主库执行一个事务,提交后稍后异步的传送到从库中,如果是基于语句的复制则会重新执行,如果是基于行的负责则会应用日志,同时是shared-nothing的架构,即所有服务器拥有同样的数据复制
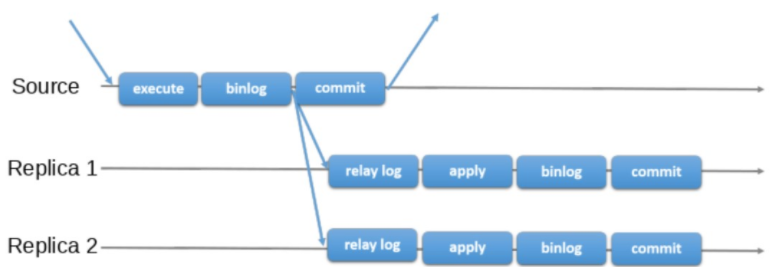
传统的数据主从复制均属于异步复制,从库起IO线程连接主库,获取主库二进制日志写到本地中继日志,并更新master-info文件(存放主库相关信息),从库再利用SQL线程执行中继日志。
补充:为了保证Binlog的安全,MySQL引入sync_binlog参数来控制BINLOG刷新到磁盘的频率。
2、主从复制之半同步复制(即同步复制)
MySQL也提供了一个半同步复制,即同步复制,其要求主库在commit时等待从库接受完事务并返回确认信息后才能提交。半同步复制是建立在基本的主从复制基础上,利用插件完成半同步复制,传统的主从复制,不管从库是否正确获取到二进制日志,主库不断更新,半同步复制则当确认了从库把二进制日志写入中继日志才会允许提交,如果从库迟迟不返回ack,主库会自动将半同步复制状态取消,进入最基本的主从复制模式。
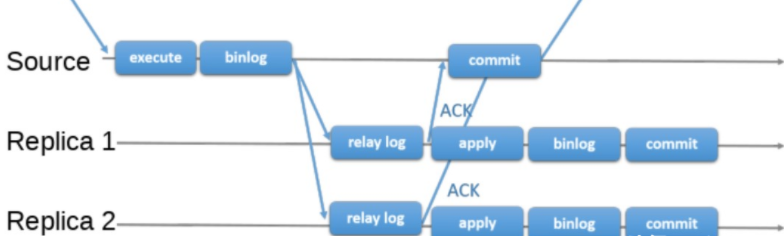
半同步复制保证了事务成功提交后,至少有两份日志记录,一份在主库的BINLOG日志上,另一份在至少一个从库的中继日志Relay Log上,从而更进一步保证了数据的完整性。
半同步复制模式下,假如在传送BINLOG日志到从库时,从库宕机或者网络延迟,导致BINLOG并没有即使地传送到从库上,此时主库上的事务会等待一段时间(时间长短由参数rpl_semi_sync_master_timeout设置的毫秒数决定),如果BINLOG在这段时间内都无法成功发送到从库上,则MySQL自动调整复制为异步模式,事务正常返回提交结果给客户端。
半同步复制很大程度上取决于主从库之间的网络情况,往返时延RTT越小决定了从库的实时性越好。通俗地说,主从库之间的网络越快,从库约实时。
3、完全同步复制(pxc):
由于半同步的这种弊端,在生产环境里一般用到的很少,但是为了保证节点之间的数据一致性。可以采用完全同步的方式-----PXC架构。
3.1、概念:
PXC在数据commit的时候需向其他主机进行确认,当有多个主机成员返回ACK时才可以commit数据。一般主机数量与返回ACK的数量如下:
5个节点,有三个节点回复。
3个节点,有一个节点回复。
3.2、特点:
对于数据库的数据一致性很高的场景。
PXC解决的是数据强一致性的问题,而不是存储结构的问题。
几个节点可以跑同一个业务结构。同时下面也可以挂在slave端。
有些类似于oracle的rac功能,实现并发负载。只是没有共享存储,一般oracle转mysql用途比较多些。
3.3、工作原理:
a、在PXC集群中第一个节点会以mysql --wsrep_cluster_address=gcomm://192.168.100.200这种方式启动。其他节点会以/etc/init.d/mysql start的方式启动。
b、当第二个节点加入PXC集群后,会连接到node1上去请求数据,并查看GTID的节点。如果所有GTID的节点与新加入的节点不一致,就会通过全量(SST)的方式去同步所有节点的数据。此时提供node1数据提供住就被称为donor。
c、donor角色在同步数据前的时候会做一次SST的备份,此时备份过程中donor节点性能会变得非常差。因此,在跑PXC的服务器不要使用多实例。如果集群是能够在控制范围内的化,可以指定一个donor的主机进行数据同步,当节点传输完后直接删除参数即可。
参数如下:
vi /etc/my.cnf
wsrep_sst_donor=节点名
https://www.cnblogs.com/abobo/p/4239220.html
1、MGR介绍
MGR也就是MySQL Group Replication的简称,这是MySQL在5.7.17版本推出全新的高可用与高扩展的解决方案,MySQL组复制提供了高可用、高扩展、高可靠的MySQL集群服务。高一致性,基于原生复制及paxos协议的组复制技术,并以插件的方式提供,提供一致数据安全保证;高容错性,只要不是大多数节点坏掉就可以继续工作,有自动检测机制,当不同节点产生资源争用冲突时,不会出现错误,按照先到者优先原则进行处理,并且内置了自动化脑裂防护机制;高扩展性,节点的新增和移除都是自动的,新节点加入后,会自动从其他节点上同步状态,直到新节点和其他节点保持一致,如果某节点被移除了,其他节点自动更新组信息,自动维护新的组信息;高灵活性,有单主模式和多主模式,单主模式下,会自动选主,所有更新操作都在主上进行;多主模式下,所有server都可以同时处理更新操作。
组复制是一种可以用来部署容错系统的技术,复制组中的服务器通过massage passing来进行交互,通信层通过atomic message 和 total order message delivery来保证组内成员数据的一致性,所有的读-写(RW)操作需要组内所有成员都通过才可提交,只读(RO)事务不需要这个过程
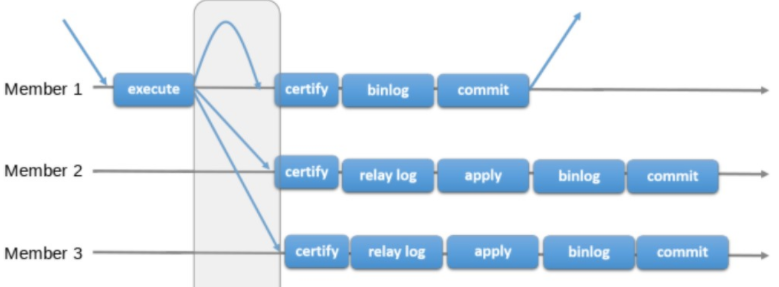
组复制中的复制组是一个通过消息传递相互交互的server集群。复制组由多个server成员组成,如上图的master1,master2,master3,所有成员独立完成各自的事务。当客户端先发起一个更新事务,该事务先在本地执行,执行完成之后就要发起对事务的提交操作了。在还没有真正提交之前需要将产生的复制写集广播出去,复制到其他成员。如果冲突检测成功,组内决定该事务可以提交,其他成员可以应用,否则就回滚。最终,这意味着所有组内成员以相同的顺序接收同一组事务。因此组内成员以相同的顺序应用相同的修改,保证组内数据强一致性。
2、MGR复制的背景
MySQL5.17的版本中,MySQL提出了一种新的同步机制,称为statemachine复制,这种复制是一种分布式的基于server之间的复制,并且组中的server成员会自动根据当前的协调。
MGR复制可以分为两种,分别是单主模式复制和多主复制模式。
单主模式,组复制具有自主选主的功能,并且只有主节点可以进行DDL和DML的操作,其他节点全部是只读状态。
多主模式,所有节点都可以进行DDL和DML操作。
对于这两种模式,MySQL都有专门的监控视图,并且有防脑裂的措施和算法,这些全靠MySQL官方推出的Paxos算法来实现。
3、组复制的过程
当事务在原始服务器上要求提交后,服务器会自动广播写值(row changed)以及相应的写集( unique identifiers of the rows),然后一个全局的总的顺序(global total order )为该事务建立了,这意味着所有的服务器按照顺序接受到了该事务,然后所有服务器按照相同的顺序应用该事务。
MGR提供一种叫做certification的步骤来解决冲突的问题,当不同服务器同时更新一行,此时则会发生冲突,这时MGR会承认第一个提交的事务,剩下的会被回滚,这也叫做distributed first commit wins 规则
4、新成员加入组的简单流程
1)当有新的成员加入组中,组内原有的成员会在二进制日志中插入一个视图切换的事件。
2)在组成员内找到一个donor捐赠之前缺失的数据,如果这个donor突然下线了,新成员会从新的donor获取缺失的数据,这时候组还在不断更新,新成员会将新的事件写到内存的一个临时空间
3)当获取到视图切换事件的时候,新成员将开始执行保存到内存临时空间的事件
5、组复制模式
组复制可以在两种模式下运行。
1)在单主模式下,组复制具有自动选主功能,每次只有一个 server成员接受更新。
2)在多主模式下,所有的 server 成员都可以同时接受更新.
6、组复制的详细信息
主复制的详细信息大致包含3个方面的内容,分别是主复制的传输故障检测机制、组成员关系和容错机
1.组复制的传输故障检测
组复制的传输还是采用了mysql的binlog作为日志,但是因为有排队的机制所以必须采用GTID的模式,也就是说GTID必须打开。那么当在整个MGR集群运行工作中,提交了一个读写事务,如果有某个server未响应,那么就会在集群内的所有成员进行仲裁投票,将这个未响应的活着已经死掉的server踢出集群。
2.组复制间成员关系
MGR通过专门的插件来维护组内的关系,这个插件定义了哪些server在线状态并且是在组内的,我们可以通过相关的视图进行查询,在组内的所有的server不仅对事务的提交是达成一致的,而且所能查询到的这张维护组复制的视图的内容也是一致的,如果有新的server加入到集群组内或者有现有的server要从组内移除,那么整个视图都会进行动态的调整。
在这里需要特别注意,如果有server自愿离开组内时,首先整个组会动态重新配置,此时会触发一个投票的过程,在组内的除了离开的server开始投票,如果投票达成一致,那么组内踢出离开的server并且自动开始维护视图,如果组内无法达成一致,那么系统将不会动态变更视图,此时系统会锁定整个组防止脑裂的发生,这时就需要人工介入。
3.容错机制
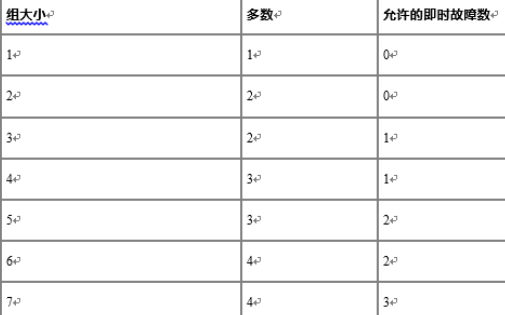
MGR是根据Paxos算法来实现的,所以他具有一定的容错的数量,根据官方文档给出的公式,容忍f个故障所需的server数量(n)为n = 2×f + 1。也就是说容忍一个故障必须有3个server,也就说如果要实现仲裁和容错的效果,必须有3个server构成一个集群,以下是官方给出的数据
7、组复制使用场景
MGR可以让你在组内不是全部或者大多数服务器失效时都可以保证数据库服务的可用,MGR利用一个依赖分布式失败检测器(distributed failure detector)的组成员关系服务(group membership service)来跟踪组内成员的离开(资源的离开或者是意外的离开)
MGR有个分布式恢复程序(distributed recovery procedure)来确保每当有服务器加入组后数据库保持最新,从而使得我们不需要做fail-over,多主架构还可以保证主库宕机时不会阻塞更新,MGR保证数据库服务持续可用。
最后需要理解的是虽然MGR可以保证数据库服务器的可用性,但是客户端的连接还是需要重新定向到另外的服务器的。想要达到这个目的,可以考虑MySQL Router。
如下为一些可能需要MGR的场景
https://mp.weixin.qq.com/s/ZsdryjQwDqjW6l8JBRBmfg 参考文章
标签:更新 引入 延迟 str 事务 效果 内容 ott otto
原文地址:https://www.cnblogs.com/zjz20/p/13756829.html