标签:爬虫 alt 文本 向量 信息 结构 ref 分词 内容
?一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值,内容一般分为两部分,非结构化的文本,或结构化的文本。
JSON、XML、HTML
HTML文本(包含JavaScript代码)是最常见的数据格式,理应属于结构化的文本组织,但因为一般我们需要的关键信息并非直接可以得到
需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。
常见解析方式如下:XPath、CSS选择器、正则表达式
HTML DOM 定义了访问和操作 HTML 文档的标准方法。
DOM 以树结构表达 HTML 文档。
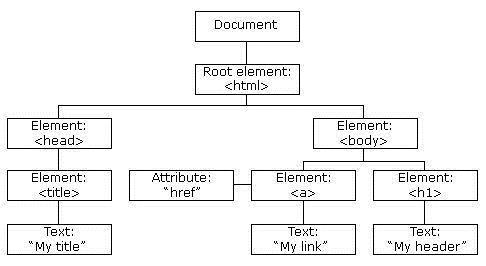
例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
分词根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
NLP自然语言处理,进行语义分析,用结果表示,例如正负面等。

IT入门 感谢关注 | 练习地址:www.520mg.com/it
标签:爬虫 alt 文本 向量 信息 结构 ref 分词 内容
原文地址:https://www.cnblogs.com/bigzql/p/13799574.html