标签:rod 分布式消息 吞吐量 领域 set hand 关注 了解 route
在上一章中SpringBoot整合RabbitMQ,已经详细介绍了消息队列的作用,这一种我们直接来学习SpringBoot如何整合kafka发送消息。
kafka是用Scala和Java语言开发的,高吞吐量的分布式消息中间件。高吞吐量使它在大数据领域具有天然的优势,被广泛用来记录日志。
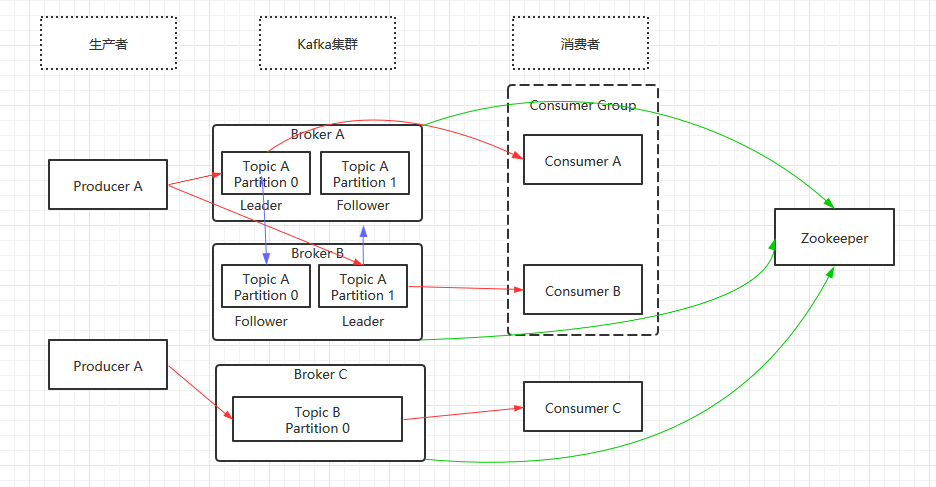
注1:图中的红色箭头表示消息的流动过程,蓝色表示分区备份,绿色表示kafka集群注册到zookeeper。
注2:在kafka0.9版本之前,消费者消费消息的位置记录在zookeeper中,在0.9版本之后,消费消息的位置记录在kafka的一个topic上。
kafka名词简介:
采用ack确认机制来保证消息的可靠性。
kafka在发送消息后会同步到其他分区副本,等所有副本都接收到消息后,kafka才会发送ack进行确认。采用这种模式的劣势就是当其中一个副本宕机后,则消息生产者就不会收到kafka的ack。
kafka采用ISR来解决这个问题。
ISR:Leader维护的一个和leader保持同步的follower集合。
当ISR中的folower完成数据同步之后,leader就会向follower发送ack,如果follower长时间未向leader同步数据,则该follower就会被踢出ISR,该时间阀值的设置参数为replica.lag.time.max.ms,默认时间为10s,leader发生故障后,就会从ISR中选举新的leader。
注:本文所讲的kafka版本为0.11,在0.9版本以前成为ISR还有一个条件,就是同步消息的条数。
ack参数配置
0:生产者不等待broker的ack。
1:leader分区接收到消息向生产者发送ack。
-1(all):ISR中的leader和follower同步成功后,向生产者发送ack。
假如leader中有10条消息,向两个follower同步数据,follower A同步了8条,follower B同步了9条。这时候leader宕机了,follower A和follower B中的消息是不一致的,剩下两个follower就会重新选举出一个leader。
LEO(log end offset):每个副本的最后一个offset
HW(high watermark):所有副本中最小的offset
为了保证数据的一致性,所有的follower会将各自的log文件高出HW的部分截掉,然后再从新的leader中同步数据。
在kafka0.11版本中引入了一个新特性:幂等性。启用幂等性后,ack默认为-1。将生产者中的enable.idompotence设置为true,即启用了幂等性。
开启幂等性的Producer在初始化的时候会被分配一个PID,发往同一Partition的消息会附带Sequence Number。Broker端会对<PID,Partition,SeqNumber>做缓存,当具有相同主键的消息提交时,Broker只会缓存一条。但是每次重启PID就会发生变化,因此只能保证一次会话同一分区的消息不重复。
kafka有两种分配策略,一种是RoundRobin,另一种是Range
RoundRobin是按照消费者组以轮询的方式去给消费者分配分区的方式,前提条件是消费者组中的消费者需要订阅同一个topic。
Range是kafka默认的分配策略,它是通过当前的topic按照一定范围来分配的,假如有3个分区,消费者组有两个消费者,则消费者A去消费1和2分区,消费者B去消费3分区。
Kafka 0.9 版本之前,consumer默认将offset保存在zookeeper中,0.9 版本开始,offset保存在kafka的一个内置topic中,该topic为_consumer_offsets。
为了实现跨分区会话的事务,需要引入一个全局唯一的Tracscation ID,并将Producer 获得的PID与之绑定。这样当Producer重启后就可以通过正在进行的Transaction ID获得原来的PID。
为了管理Transcation ID,kafka引入了一个新的组件Transcation Coordinator。Producer就是通过和Transcation Coordinator交互获得Transction ID对应的任务状态。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
spring:
kafka:
# kafka服务地址
bootstrap-servers: 47.104.155.182:9092
producer:
# 生产者消息key序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 生产者消息value序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
# 消费者组
group-id: test-consumer-group
# 消费者消息value反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 消费者消息value反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
@Component
@Slf4j
@KafkaListener(topics = {"first-topic"},groupId = "test-consumer-group")
public class Consumer {
@KafkaHandler
public void receive(String message){
log.info("我是消费者,我接收到的消息是:"+message);
}
}
@RestController
public class Producer {
@Autowired
private KafkaTemplate kafkaTemplate;
@GetMapping("send")
public void send(){
String message = "你好,我是Java旅途";
// 第一个参数 topic
// 第二个参数 消息
kafkaTemplate.send("first-topic",message);
}
}
此是spring-boot-route系列的第十四篇文章,这个系列的文章都比较简单,主要目的就是为了帮助初次接触Spring Boot 的同学有一个系统的认识。本文已收录至我的github,欢迎各位小伙伴star!
github:https://github.com/binzh303/spring-boot-route
如果觉得文章不错,欢迎关注、点赞、收藏,你们的支持是我创作的动力,感谢大家。
如果文章写的有问题,请不要吝啬,欢迎留言指出,我会及时核查修改。
如果你还想更加深入的了解我,可以微信搜索「Java旅途」进行关注。回复「1024」即可获得学习视频及精美电子书。每天7:30准时推送技术文章,让你的上班路不在孤独,而且每月还有送书活动,助你提升硬实力!
标签:rod 分布式消息 吞吐量 领域 set hand 关注 了解 route
原文地址:https://www.cnblogs.com/zhixie/p/13807179.html