标签:hydra 理解 rbo 作者 document 安装 噪声 复习 虚拟变量
作者|SHIPRA SAXENA
编译|Flin
来源|analyticsvidhya
了解什么是分类数据编码
了解不同的编码技术以及何时使用它们
机器学习模型的性能不仅取决于模型和超参数,还取决于我们如何处理并将不同类型的变量输入模型。由于大多数机器学习模型仅接受数值变量,因此对分类变量进行预处理成为必要的步骤。我们需要将这些分类变量转换为数字,以便该模型能够理解和提取有价值的信息。

典型的数据科学家花费70-80%的时间来清理和准备数据。转换分类数据是不可避免的活动。它不仅可以提高模型质量,而且可以帮助进行更好的特征工程。现在的问题是,我们如何进行?我们应该使用哪种分类数据编码方法?
在本文中,我将解释各种类型的分类数据编码方法以及在Python中的实现。
如果你想学习视频格式的数据科学概念,请查看我们的课程:
由于我们将在本文中处理类别变量,因此这里有一些示例,可以快速复习。分类变量通常表示为“字符串”或“类别”,并且数量有限。这里有一些例子:
在以上示例中,变量仅具有确定的可能值。此外,我们可以看到有两种分类数据:
有序数据:类别具有固有顺序
名义数据:类别没有固有顺序
在有序数据中,在进行编码时,应保留有关类别提供顺序的信息。就像上面的例子一样,一个人拥有的最高学位,给出了有关他的资格的重要信息。学位是决定一个人是否适合担任职位的重要特征。
在编码名义数据时,我们必须考虑特征的存在与否。在这种情况下,不存在顺序的概念。例如,一个人居住的城市。对于数据,保留一个人居住的位置很重要。在这里,我们没有任何顺序。如果一个人住在德里或班加罗尔,这是平等的,与顺序无关。
为了编码分类数据,我们有一个python包category_encoders。以下代码可帮助你轻松安装。
pip install category_encoders
当分类特征有序时,我们使用这种分类数据编码技术。在这种情况下,保留顺序很重要。因此编码应该反映顺序。
在标签编码中,每个标签都被转换成一个整数值。我们将创建一个变量,该变量包含代表一个人的教育资格的类别。
import category_encoders as ce
import pandas as pd
train_df=pd.DataFrame({‘Degree‘:[‘High school‘,‘Masters‘,‘Diploma‘,‘Bachelors‘,‘Bachelors‘,‘Masters‘,‘Phd‘,‘High school‘,‘High school‘]})
# 创建Ordinalencoding的对象
encoder= ce.OrdinalEncoder(cols=[‘Degree‘],return_df=True,
mapping=[{‘col‘:‘Degree‘,
‘mapping‘:{‘None‘:0,‘High school‘:1,‘Diploma‘:2,‘Bachelors‘:3,‘Masters‘:4,‘phd‘:5}}])
#原始数据
train_df
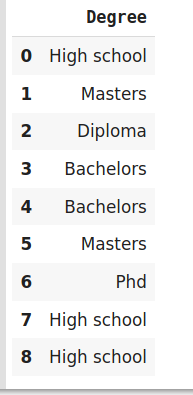
# 调整并转换数据
df_train_transformed = encoder.fit_transform(train_df)

当特征没有任何顺序时,我们使用这种分类数据编码技术。在独热编码中,对于一个分类特征的每个级别,我们创建一个新的变量。每个类别都映射有一个包含0或1的二进制变量。在这里,0代表该类别不存在,1代表该类别存在。
这些新创建的二进制特性称为虚拟变量。虚拟变量的数量取决于类别变量中的级别。这听起来可能很复杂。
让我们举个例子来更好地理解这一点。假设我们有一个动物分类数据集,有不同的动物,如狗、猫、羊、牛、狮子。现在我们必须对这些数据进行独热编码。
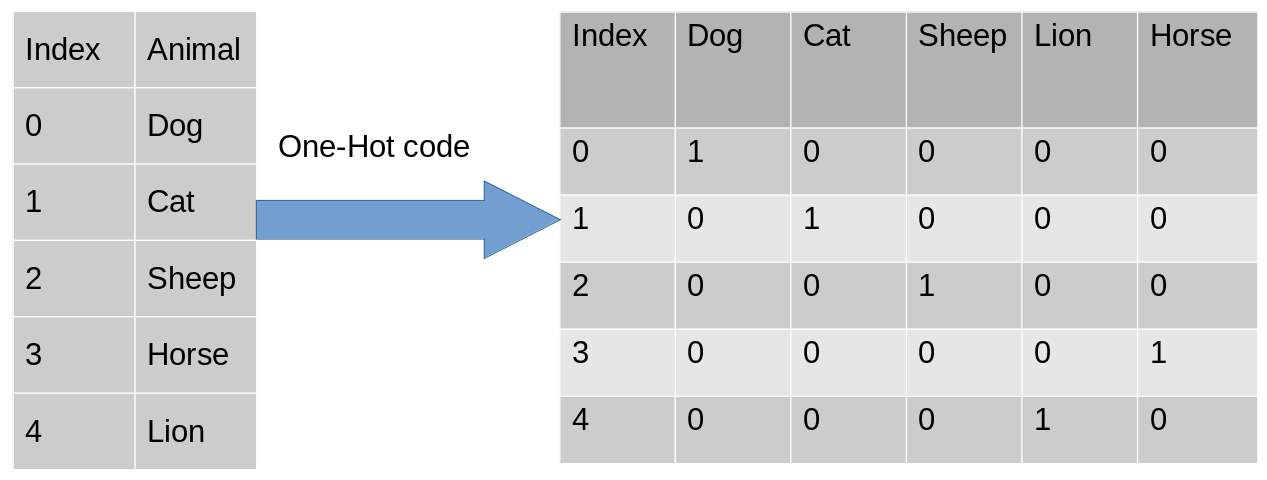
编码后,在第二个表中,我们有一个虚拟变量,每个变量代表动物的类别。现在,对于每个存在的类别,我们在该类别的列中都有1,其他列为0。让我们看看如何在python中实现独热编码。
import category_encoders as ce
import pandas as pd
data=pd.DataFrame({‘City‘:[
‘Delhi‘,‘Mumbai‘,‘Hydrabad‘,‘Chennai‘,‘Bangalore‘,‘Delhi‘,‘Hydrabad‘,‘Bangalore‘,‘Delhi‘
]})
#创建用于独热编码的对象
encoder=ce.OneHotEncoder(cols=‘City‘,handle_unknown=‘return_nan‘,return_df=True,use_cat_names=True)
# 原始数据
data

# 调整和转换数据
data_encoded = encoder.fit_transform(data)
data_encoded
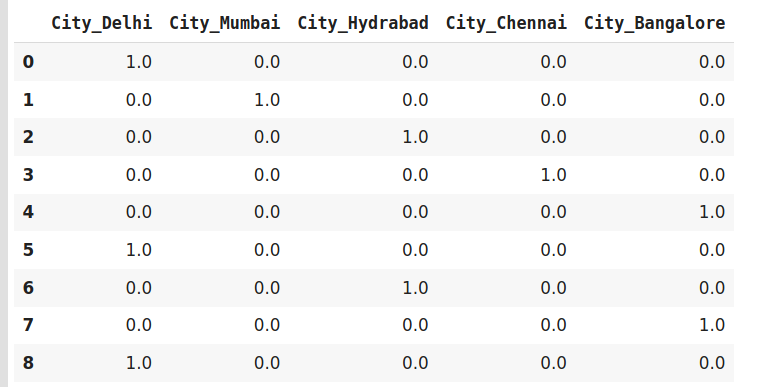
现在,让我们转到另一种非常有趣且广泛使用的编码技术,即虚拟编码。
虚拟编码方案类似于独热编码。这种分类数据编码方法将分类变量转换为一组二进制变量(也称为虚拟变量)。在独热编码的情况下,对于变量中的N个类别,它使用N个二进制变量。虚拟编码是对独热编码的一个小改进。虚拟编码使用N-1个特征来表示N个标签/类别。
为了更好地理解这一点,让我们看下面的图片。在这里,我们使用独热编码和虚拟编码技术对相同的数据进行编码。独热编码使用3个变量表示数据,而虚拟编码使用2个变量编码3个类别。
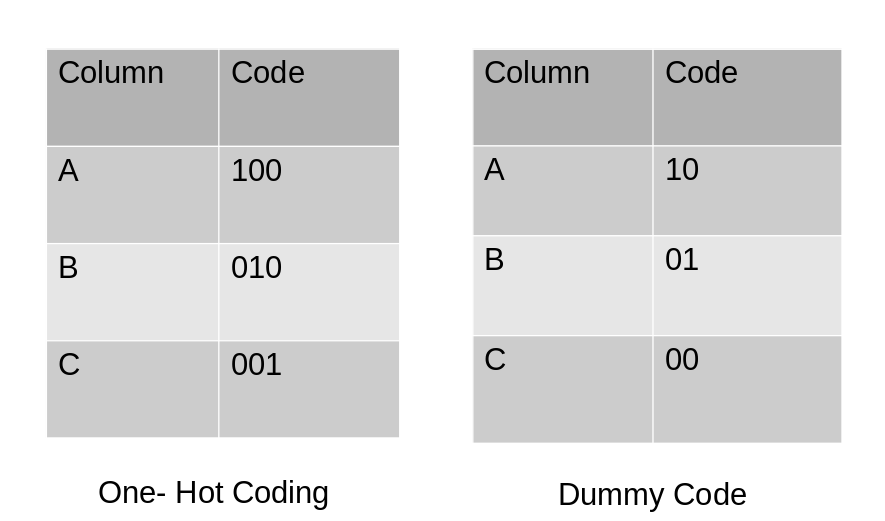
让我们在python中实现它。
import category_encoders as ce
import pandas as pd
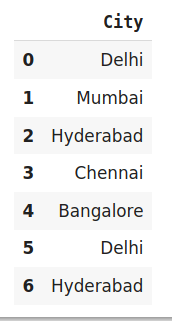
data=pd.DataFrame({‘City‘:[‘Delhi‘,‘Mumbai‘,‘Hyderabad‘,‘Chennai‘,‘Bangalore‘,‘Delhi,‘Hyderabad‘]})
# 原始数据
data
#编码数据
data_encoded=pd.get_dummies(data=data,drop_first=True)
data_encoded
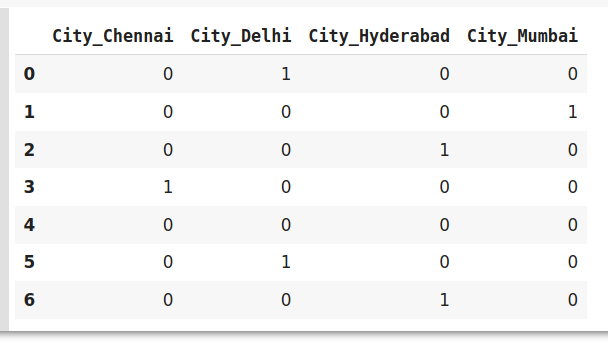
在这里,使用drop_first参数,我们使用0表示第一个标签Bangalore。
独热编码器和虚拟编码器是两种功能强大且有效的编码方案。它们在数据科学家中也很受欢迎,但在以下这些情况下可能不那么有效:
数据中存在大量级别。在这种情况下,如果一个特征变量中有多个类别,则我们需要相似数量的虚拟变量来对数据进行编码。例如,具有30个不同值的列将需要30个新变量进行编码。
如果我们在数据集中具有多个分类特征,则将发生类似的情况,并且我们最终会有几个二进制特征,每一个都代表分类特征和它们的多个类别,例如一个包含10个或更多分类列的数据集。
在以上两种情况下,这两种编码方案都会在数据集中引入稀疏性,即几列为0,而另几列为1。换句话说,它在数据集中创建了多个虚拟特征而无需添加太多信息。
此外,它们可能会导致虚拟变量陷阱。这是特征高度相关的现象。这意味着使用其他变量,我们可以轻松预测变量的值。
由于数据集的大量增加,编码使模型的学习变慢,并且整体性能下降,最终使模型的计算昂贵。此外,在使用基于树的模型时,这些编码不是最佳选择。
这种编码技术也称为偏差编码(Deviation Encoding)或求和编码(Sum Encoding)。效果编码几乎与虚拟编码类似,只是有一点点差异。在虚拟编码中,我们使用0和1表示数据,但在效果编码中,我们使用三个值,即1,0和-1。
在虚拟编码中仅包含0的行在效果编码中被编码为-1。在虚拟编码示例中,索引为4的班加罗尔城市被编码为0000。而在效果编码中,它是由-1-1-1-1表示的。
让我们看看我们如何在python中实现它
import category_encoders as ce
import pandas as pd
data=pd.DataFrame({‘City‘:[‘Delhi‘,‘Mumbai‘,‘Hyderabad‘,‘Chennai‘,‘Bangalore‘,‘Delhi,‘Hyderabad‘]}) encoder=ce.sum_coding.SumEncoder(cols=‘City‘,verbose=False,)
# 原始数据
data
encoder.fit_transform(data)
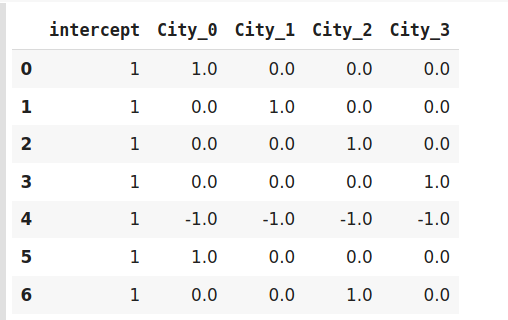
效果编码是一种先进的技术。如果你有兴趣了解更多关于效果编码的信息,请参阅这篇有趣的文章。
要理解哈希编码,就必须了解哈希。哈希是以固定大小值的形式对任意大小的输入进行的转换。我们使用哈希算法来执行哈希操作,即生成输入的哈希值。
此外,哈希是一个单向过程,换句话说,不能从哈希表示生成原始输入。
散列有几个应用,如数据检索、检查数据损坏以及数据加密。我们有多个哈希函数可用,例如消息摘要(MD、MD2、MD5)、安全哈希函数(SHA0、SHA1、SHA2)等等。
就像独热编码一样,哈希编码器使用新的维度来表示分类特性。在这里,用户可以使用n_component参数来确定转换后的维度数量。这就是我的意思——一个有5个类别的特征可以用N个新特征来表示。同样,一个有100个类别的特征也可以用N个新特征来转换。听起来不错吧?
默认情况下,哈希编码器使用md5哈希算法,但用户可以传递他选择的任何算法。如果你想探索md5算法,我建议你阅读这篇文章。
import category_encoders as ce
import pandas as pd
#Create the dataframe
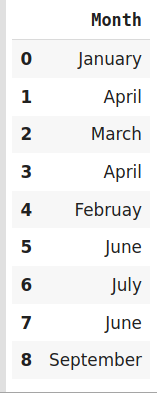
data=pd.DataFrame({‘Month‘:[‘January‘,‘April‘,‘March‘,‘April‘,‘Februay‘,‘June‘,‘July‘,‘June‘,‘September‘]})
#Create object for hash encoder
encoder=ce.HashingEncoder(cols=‘Month‘,n_components=6)
# 调整和转换数据
encoder.fit_transform(data)
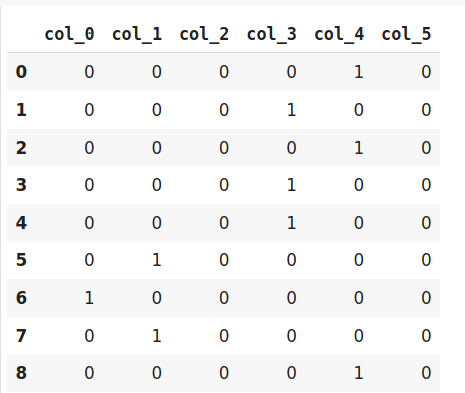
由于哈希将数据转换为较小的维度,因此可能导致信息丢失。哈希编码器面临的另一个问题是冲突。由于此处将大量特征描绘成较小的尺寸,因此可以用相同的哈希值表示多个值,这称为冲突。
此外,哈希编码器在某些Kaggle比赛中非常成功。最好尝试一下数据集是否具有高基数特征。
二进制编码是哈希编码和独热编码的组合。在这种编码方案中,首先使用有序编码器将分类特征转换为数值。然后将数字转换为二进制数。之后,该二进制值将拆分为不同的列。
当类别很多时,二进制编码的效果很好。例如,公司提供产品的国家/地区的城市。
#Import the libraries
import category_encoders as ce
import pandas as pd
#Create the Dataframe
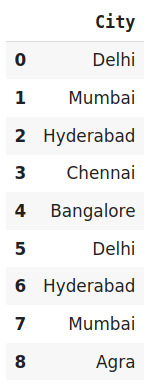
data=pd.DataFrame({‘City‘:[‘Delhi‘,‘Mumbai‘,‘Hyderabad‘,‘Chennai‘,‘Bangalore‘,‘Delhi‘,‘Hyderabad‘,‘Mumbai‘,‘Agra‘]})
#Create object for binary encoding
encoder= ce.BinaryEncoder(cols=[‘city‘],return_df=True)
# 原始数据
data
# 调整和转换数据
data_encoded=encoder.fit_transform(data)
data_encoded
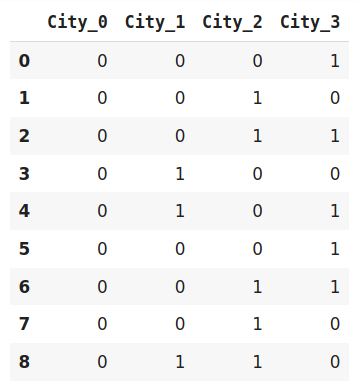
二进制编码是一种节省内存的编码方案,因为它比独热编码使用更少的特性。此外,它还减少了高基数数据的维数灾难。
在开始使用BaseN编码之前,我们首先尝试了解什么是Base。
在数字系统中,“底数”或“基数”是数字的数目或用于表示数字的数字和字母的组合。我们一生中最常用的基数是10或十进制,因为在这里我们使用10个唯一数字,即0到9来代表所有数字。另一个广泛使用的系统是二进制,即基数为2。它使用0和1,即2位数字来表示所有数字。
对于二进制编码,基数为2,这意味着它将类别的数值转换为其各自的二进制形式。如果要更改基本编码方案,则可以使用BaseN编码器。如果类别更多,而二进制编码无法处理维数,则可以使用更大的底数,例如4或8。
#Import the libraries
import category_encoders as ce
import pandas as pd
#Create the dataframe
data=pd.DataFrame({‘City‘:[‘Delhi‘,‘Mumbai‘,‘Hyderabad‘,‘Chennai‘,‘Bangalore‘,‘Delhi‘,‘Hyderabad‘,‘Mumbai‘,‘Agra‘]})
#Create an object for Base N Encoding
encoder= ce.BaseNEncoder(cols=[‘city‘],return_df=True,base=5)
# 原始数据
data
# 调整和转换数据
data_encoded=encoder.fit_transform(data)
data_encoded
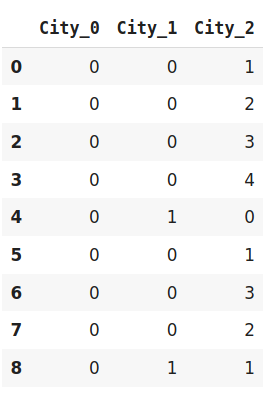
在上面的例子中,我使用了base5,也就是所谓的五元体系。它类似于二进制编码的例子。二进制编码用4个新特性表示相同的数据,而BaseN编码只使用3个新变量。
因此,BaseN编码技术进一步减少了有效表示数据和提高内存使用率所需的特征数量。基数N的默认基数是2,这相当于二进制编码。
目标编码是一种贝叶斯编码技术。
贝叶斯编码器使用来自相关/目标变量的信息对分类数据进行编码。
在目标编码中,我们计算每个类别的目标变量的平均值,并用平均值替换类别变量。在分类目标变量的情况下,目标的后验概率代替每个类别。
#import the libraries
import pandas as pd
import category_encoders as ce
#创建数据框
data=pd.DataFrame({‘class‘:[‘A,‘,‘B‘,‘C‘,‘B‘,‘C‘,‘A‘,‘A‘,‘A‘],‘Marks‘:[50,30,70,80,45,97,80,68]})
#创建目标编码对象
encoder=ce.TargetEncoder(cols=‘class‘)
# 原始数据
Data
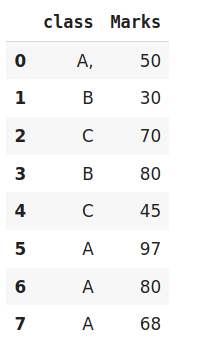
# 调整并转换数据
encoder.fit_transform(data[‘class‘],data[‘Marks‘])
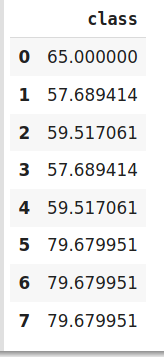
我们仅对训练数据执行目标编码,并使用从训练数据集中获得的结果对测试数据进行编码。尽管这是一种非常高效的编码系统,但它具有以下问题,这些问题会导致模型性能下降
它可能导致目标泄漏( target leakage)或过拟合。为了解决过拟合问题,我们可以使用不同的技术。
我们可能面临的第二个问题是训练和测试数据中类别的不正确分配。在这种情况下,类别可能采用极端值。因此,类别的目标平均值与目标的边际平均值混合在一起。
总而言之,对分类数据进行编码是特征工程中不可避免的部分。知道我们应该使用哪种编码方案更为重要。考虑到我们正在使用的数据集和将要使用的模型。在本文中,我们已经看到了各种编码技术以及它们的问题和合适的用例。
如果你想了解有关处理分类变量的更多信息,请参阅本文
原文链接:https://www.analyticsvidhya.com/blog/2020/08/types-of-categorical-data-encoding/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
标签:hydra 理解 rbo 作者 document 安装 噪声 复习 虚拟变量
原文地址:https://www.cnblogs.com/panchuangai/p/13835164.html