标签:而不是 cio 模型 概念 预测 learn 不同 数据 机器学习
关于元学习,网上的很多教程不太说人话,大多是根据李宏毅教授的课进行的一个拓展,并没有去详细的讲解一些步骤性的问题;
关于原理或者说概要比较好的博客:
https://zhuanlan.zhihu.com/p/108503451
https://zhuanlan.zhihu.com/p/55643191
上面两篇可以说是大致很好的讲解了元学习的基本概念,自己本篇进行一个大致的整理;
元学习的大致思想:寻求一种方法使得可以从过去的任务中学习到如何去学习。
从本质的上来说,和传统机器学习相比较:
传统机器学习:DL包括在内,都是寻求一个boundary来进行定界操作,主要关心得到一个输入和标签的映射网络;
元学习:执着于网络参数的确定,使得每一次训练后,都可以让模型自己去尝试制定参数,而不是人为去设定参数;
所以,某种程度上训练过程可能类似,但是侧重思想是不一样的;
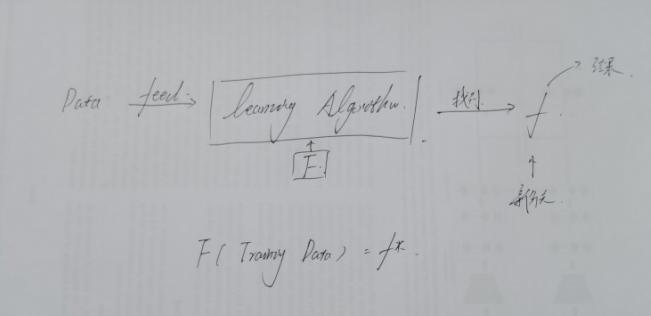
如上所示,可以基本的看出元学习的目的并不是生成预测值,而是通过feed数据集,来世的learning algorithm收敛,得到一个新的函数,为下一个任务做准备,所以,本质就是通过一个任务生成一个特定的网络,由训练过程自发的使网络来达到最佳,其实和传统学习还是有点像的;
但是比较不同的一点是,生成的网络可以在不同的task有不同的结果,而后续的MAML则是固定一类模型,算是meta-learning中的特殊情况;
所以元学习的基本步骤有以下几步:
1.进行一群F函数的选择,对于同样的一系列task来进行训练;
2.根据一定的方法评价task的好坏;
3.最后选择最好的F;
对于上述,完整的流程可以如下所示:

所以,对于不同的F,寻找出生成f效率最好的函数,总体通过loss funcion l来进行评估;
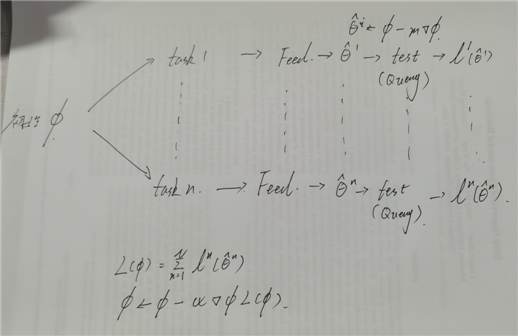
MAML是Meta-learning中的一种,但是其核心思想是初始化参数的设定;
即通过task的学习,得到一个使得每个task都最优的初始参数;
对于各个网络中的参数,直接利用初始参数进行更新;
而对于目标函数,我们要求L函数有最小值,所以可以直接借此更新初始化参数,从而达到寻找最优初始化参数的目的;
其中需要注意的是以下几点:
1.局部网络和整体初始参数更新的速率不同;
2.局部网络中往往是一次训练,但是也可以根据数据量进行更改,使得收敛更好;
标签:而不是 cio 模型 概念 预测 learn 不同 数据 机器学习
原文地址:https://www.cnblogs.com/songlinxuan/p/13859490.html