标签:android style blog http io color ar os 使用
最近有同学反馈了这样一个问题:

上述语句在脚本中 load 入库的时候会 hang 住,web 前端、命令行操作则要么抛出
Incorrect string value: ‘\xF0\xA1\x8B\xBE\xE5\xA2...‘ for column ‘name‘,
要么存入MYSQL数据库的内容会被截断或者乱码,而换做其它的中文则一切正常。
嗯,看起来有点奇怪哈,按理说 utf8 编码是覆盖了所有中文的,不应该出现上述问题。
那我们先来看看插入异常的中文和正常的中文有啥区别:
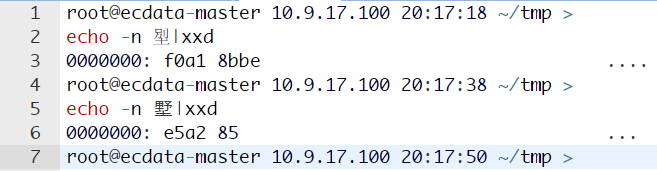
可以看到上面插入异常的文字占了 4 个字节,而我们插入正常的则只占了 3 个字节。但是 utf8 字符编码不就是可变长,支持 1-4 字节的么?会和这个有关?
嗯,看看官方文档就知道了:
10.1.10.6 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
The character set named utf8 uses a maximum of three bytes per character and contains only BMP characters. As of MySQL 5.5.3, the utf8mb4 character set uses a maximum of four bytes per character supports supplemental characters:
最初的 UTF-8 格式使用一至六个字节,最大能编码 31 位字符。最新的 UTF-8 规范只使用一到四个字节,最大能编码21位,正好能够表示所有的 17个 Unicode 平面。
utf8 是 Mysql 中的一种字符集,只支持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多文本平面。
Mysql 中的 utf8 为什么只支持持最长三个字节的 UTF-8字符呢?我想了一下,可能是因为 Mysql 刚开始开发那会,Unicode 还没有辅助平面这一说呢。那时候,Unicode 委员会还做着 “65535 个字符足够全世界用了”的美梦。Mysql 中的字符串长度算的是字符数而非字节数,对于 CHAR 数据类型来说,需要为字符串保留足够的长。当使用 utf8 字符集时,需要保留的长度就是 utf8 最长字符长度乘以字符串长度,所以这里理所当然的限制了 utf8 最大长度为 3,比如 CHAR(100) Mysql 会保留 300字节长度。至于后续的版本为什么不对 4 字节长度的 UTF-8 字符提供支持,我想一个是为了向后兼容性的考虑,还有就是基本多文种平面之外的字符确实很少用到。
要在 Mysql 中保存 4 字节长度的 UTF-8 字符,需要使用 utf8mb4 字符集,但只有 5.5.3 版本以后的才支持(查看版本: select version();)。我觉得,为了获取更好的兼容性,应该总是使用 utf8mb4 而非 utf8. 对于 CHAR 类型数据,utf8mb4 会多消耗一些空间,根据 Mysql 官方建议,使用 VARCHAR 替代 CHAR。
知道原因了,当然得谈谈有哪些方案可以解决开头的问题。
升级你的 mysql 到 5.5.3 之后即可,查看当前环境版本:
select version();
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8bp4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
所以好的技术就是,采用对当前而言最好的解决方案,然后再逐步迭代满足新的需求。
--修改数据库字符集 ALTER DATABASE test CHARACTER SET = utf8mb4; --修改表字符集 alter table test convert to character set utf8mb4; --修改字符字符集 ALTER TABLE `test` CHANGE COLUMN `name` `name` varchar(12) CHARACTER SET utf8mb4;
[client] default-character-set = utf8mb4 [mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_unicode_ci [mysql] default-character-set = utf8mb4P.S. 如果你使用的是java语言,需要将jdbc驱动包升级到 mysql-connector-java-5.1.14.jar。
从业务和技术的角度综合考虑,可以做个折中,将生僻字符串提前过滤掉,因为这类字符串本来就使用的很少,即使存进数据库了,展示、查询的时候也会多少有其它的问题,不如直接过滤掉,mysql 不支持四字节的 utf8 一方面可能是历史包袱,另一方面估计也是为了省空间。
比如,咱们可以直接先用 sed、awk、python、perl 处理下要 load 入库的脚本,将四字节的生僻字全过滤再入库:
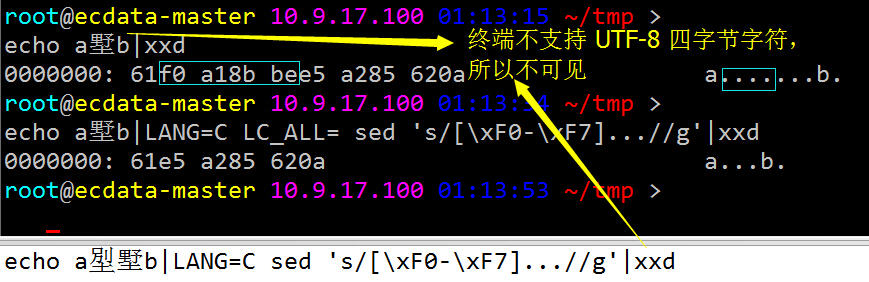
判断MySql支持Unicode字符的方法,伪码为:
for i=1->n
int c=str.codePointAt(i);
if (c<0x0000||c>0xffff) {
return false;
}
稍作修改即可。
为避免web页面或者终端本身不支持utf8四字节,可以采用二进制的方式来操作
create table t1(name varchar(20) charset utf8mb4); insert into t1 values(0xF0A09080); set charset binary; select * from t1;
最后顺便总结下4字节utf8字符的系统支持情况:
看到这里,不知道细心的你有没有发现,本文的代码为毛都是图呢?要知道我自己写文章很少把代码搞成图的,那是因为。。。
哇哈哈,真是哪壶不开提哪壶啊。。。。。。。。。

[1] 谈谈字符集与字符编码
http://my.oschina.net/leejun2005/blog/232732#OSC_h3_4
[2] sed matching any ascii code/hex byte
http://forums.gentoo.org/viewtopic-t-770576-start-0.html
[3] 10.1.10.6 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
http://dev.mysql.com/doc/refman/5.5/en/charset-unicode-utf8mb4.html
[4] Mysql 中的 utf8
[5] Mysql中4字节UTF8字符集问题
http://bbs.chinaunix.net/thread-3766853-1-1.html
[6] MySQL,UTF-8和emoji
http://shadyxu.com/mysql_utf8.html
[7] 关于MYSQL截断内容问题解决
http://www.momotime.me/2014/10/mysql-utf8mb4/
[8] MySQL储存4字节字符
http://www.web-tinker.com/article/20643.html
[9] 关于UTF-8编码的MySql抛出incorrect string value的问题
http://blog.csdn.net/tannasu/article/details/8064021
[10] 关于MYSQL截断内容问题解决
http://daiweiyang.com/mysql_data_truncated/
关于 MySQL UTF8 编码下生僻字符插入失败/假死问题的分析
标签:android style blog http io color ar os 使用
原文地址:http://my.oschina.net/leejun2005/blog/343353