标签:最大值 维护 return stc 图片 最大 mic size 很多
背景今天在脉脉上面看到了一个帖子,比较有意思:
这个帖子的意思是:在使用Kafka的时候,我们已经设置了多个分区,如何去提升消费能力?如果使用线程池的方式去提升如何保证重启时消息不丢。
这个题其实问了两个点,第一个是如何提升消费能力,第二个是如果选择线程池,我们如何做到消息不丢。
这里先解释一下这两个问题到底是怎么回事,在很多消息队列中都有一个概念叫partion,代表着分区,分区是我们提高消息队列消费的关键,我们的消费者消费的渠道就是从每个分区中来的,一个分区只能被一个消费者持有,如下图所示: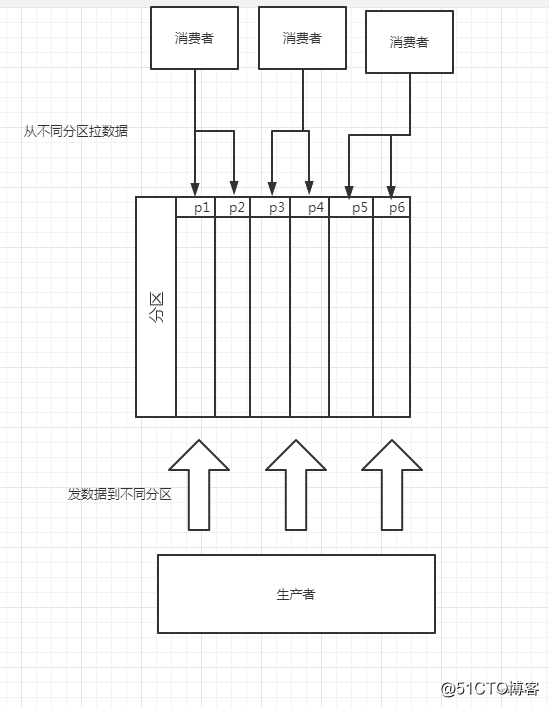
有点类似银行排队,队列的个数越多,排队的时间相对来说就会越少,当然也可以通过异步的方式去处理,比如线程池,把所有的消息都扔到线程池中去执行,这就引出了作者说的第二个问题,首先我们来看看同步消费为什么不会丢消息呢?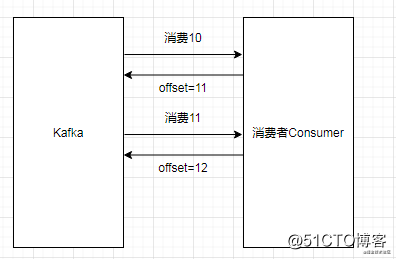
如果我们使用的是同步模型,当我们消费了之后会将offset ack回去,如果我们出现了重启,没有成功offset,那么这部分数据将会再次消费,如果是用线程池进行消费,那么我们如何进行ack呢,比如我们用线程池消费了 10,11,12 三条消息如果12先消费完,那么我们ack 13吗?如果这样做的话,这个时候重启,kafka就会认为你已经处理了10,11的消息,这个时候消息就会出现丢失,而发这个帖子的同学就是对于这一块是比较疑惑。
我们来看看网友的一些回答:
网友A:
这名网友的回答本质还是使用线程池,作者也回复了,并没有解决线程池的问题。
网友B:

这个方法类似银行排队,只要队列多,那么处理速度就会加快,的确是第一个问题的解决办法之一。
网友C:
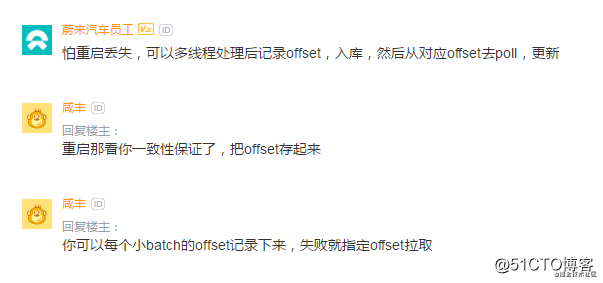
这一类主要解决了第二个问题,通过外部维护offset,比如通过offset入库的方式,我们就能找到正确的应该消费的offset,这个相对来说比较复杂,使用一个MQ还得配套一个数据库,万一我使用MQ的服务根本都没有数据库,还得单独去申请。
网友D:
还有另外一种观点就是,代码写好一点,让消费的速度提高,那消费能力自然就上去了,这个的确是一个很重要的点,通常被其他人给忽略,有时候消费比较慢,很多人可能一上来就是考虑中间件应该怎么设置,往往会忽略自己的代码。
看了这么多帖子的一个回复,感觉没有真正能让我满意的答案,下面来说说我心中的一些思路。
对于第一个问题的话,如何提升消费能力?这个问题其实可以总结为三个办法:
private final TreeMap<Long, MessageExt> msgTreeMap = new TreeMap<Long, MessageExt>();这个TreeMap的key是每个message的offset,value就是这条消息的一些信息,TreeMap的底层是使用红黑树去实现的,我们可以很快获取其中的最小值和最大值,当我们每次处理完某一条消息的时候我们会将这条消息从msgTreeMap中移除,
public long removeMessage(final List<MessageExt> msgs) {
long result = -1;
final long now = System.currentTimeMillis();
try {
this.lockTreeMap.writeLock().lockInterruptibly();
this.lastConsumeTimestamp = now;
try {
if (!msgTreeMap.isEmpty()) {
result = this.queueOffsetMax + 1;
int removedCnt = 0;
for (MessageExt msg : msgs) {
MessageExt prev = msgTreeMap.remove(msg.getQueueOffset());
if (prev != null) {
removedCnt--;
msgSize.addAndGet(0 - msg.getBody().length);
}
}
msgCount.addAndGet(removedCnt);
if (!msgTreeMap.isEmpty()) {
result = msgTreeMap.firstKey();
}
}
} finally {
this.lockTreeMap.writeLock().unlock();
}
} catch (Throwable t) {
log.error("removeMessage exception", t);
}
return result;
}removeMessage这个方法就是移除已经消费过的消息,并且返回当前最新的消费offset,这里返回的结果就是msgTreeMap.firstKey(),我们ack给消息队列server的值其实也是这个,回到我们这个问题上,如果我们发生重启,那么其实也不需要担心我们会出现消息丢失。
这里只是简单的对消息队列提升消息能力做了一些介绍,如果大家对消息队列有兴趣的,可以看我之前的一些文章:

标签:最大值 维护 return stc 图片 最大 mic size 很多
原文地址:https://blog.51cto.com/14980978/2544571