标签:限制 rate 针对 基本 硬件 方便 inf 设备 描述
转至:https://blog.csdn.net/qq_41944882/article/details/103560879
1 术语解释
1.1 高可用(HA)
什么是高可用?顾名思义我们能轻松地理解是高度可用的意思,也说是说高可用(high availability)指的是运行时间能满足预计或期望的一个系统或组件,我们常听说的247365系统,这种系统追求一种不间断提供服务的目标,任何时候都不能停止服务,否则会给用户造成比较大的影响。在信息、通讯、互联网技术发展如此快的今天,越来越多的系统都希望成为一个高可用的系统,比如银行、证券系统等。
1.2 负载均衡(LB)
负载均衡(load balance)是指将业务的负载尽可能平均、合理地分摊到集群的各个节点,每个节点都可以处理一部分负载,并且可以根据节点负载进行动态平衡,提高各个节点硬件资源的利用率以及降低单节点因为负载过高而导致的故障。
1.3 RAC集群
RAC集群,全称Real Application Clusters,译为“实时应用集群”,是Oracle提供的一种高可用、并行集群系统,RAC除了具有高可用能力还有负载均衡能力,整个RAC集群系统由Oracle Clusterware (集群软件)和 Real Application Clusters(RAC)两大部分组成。 我们平时一直经常提的RAC,它仅仅是RAC集群中的一部分,是运行在集群软件Oracle Clusterware上的一个应用,就是数据库,它和集群软件的关系类似单机环境中应用程序和操作系统的关系。
1.4 CRS
我们知道RAC集群需要集群软件,那么CRS是什么呢?在Oracle 10g版本前,RAC集群所需的集群软件依赖于硬件厂商,在不同平台上实施RAC集群都需要安装和配置厂商的集群软件,而Oracle只提供了Linux和Windows平台上的集群软件,叫Oracle Cluster Manager。但从10.1版本开始,Oracle推出了一个与平台独立的集群产品:Cluster Ready Service,简称CRS,从此RAC集群的实施不再依赖各个硬件厂商,从10.2版本开始,Oracle将这个集群产品改名为Oracle Clusterware,在11g中又被称为GI(Oracle Grid Infrastructure),但我们叫惯了CRS,所以平时很多时候也就称之为CRS,这个产品并不局限用于数据库的集群,其他应用都可以借用其API轻易实现集群功能。
2 架构
2.1 RAC环境组成
2.1.1 硬件环境
整个RAC集群的硬件环境包括主机、共享存储、互联网络设备。
这里附上一张RAC集群简单的拓扑图: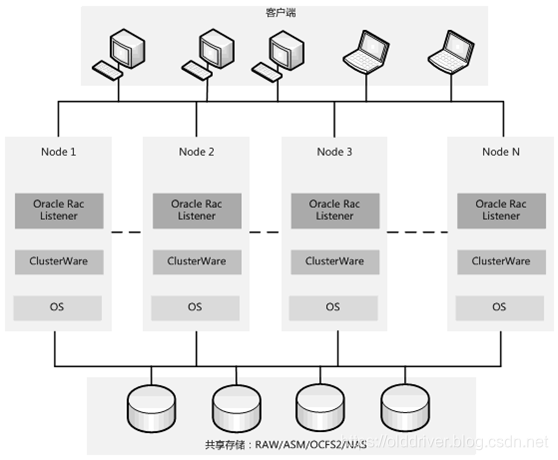
2.2 CRS组成
Oracle Clusterware,在11g中又被称为GI(Oracle Grid Infrastructure),我们这里统一直接称之为CRS好了,它由磁盘文件、后台进程、网络组件组成。
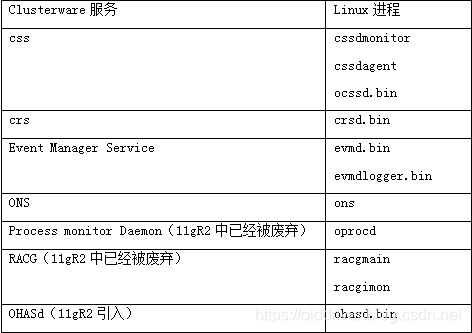
[oracle@node1 ~]$ ps -ef|grep css root 4408 1 0 04:23 ? 00:00:05 /oracle/app/grid/product/11.2.0/bin/cssdmonitor root 4427 1 0 04:23 ? 00:00:05 /oracle/app/grid/product/11.2.0/bin/cssdagent grid 4445 1 0 04:23 ? 00:00:56 /oracle/app/grid/product/11.2.0/bin/ocssd.bin [grid@node1 bin]$ ps -ef|grep crs root 4767 1 0 04:24 ? 00:00:20 /oracle/app/grid/product/11.2.0/bin/crsd.bin reboot [grid@node1 bin]$ ps -ef|grep evm grid 4623 1 0 04:24 ? 00:00:07 /oracle/app/grid/product/11.2.0/bin/evmd.bin grid 4861 4623 0 04:24 ? 00:00:00 /oracle/app/grid/product/11.2.0/bin/evmlogger.bin -o /oracle/app/grid/product/11.2.0/evm/log/evmlogger.info -l /oracle/app/grid/product/11.2.0/evm/log/evmlogger.log
我们来看一下各个进程的作用:
OCSSD
进程是Clusterware最关键的进程,如果出现异常会导致系统重启,这个进程提供CSS(Cluster Synchronization Service)服务,它通过多种心跳机制实时监控集群的健康状态,提供集群的基础服务功能。
CRSD
是实现高可用的主要进程,它提供了CRS(Cluster Ready Service)服务。这些服务包括Clusterware上集群资源的关闭、重启、转移、监控等。集群资源分为两类:一类是Nodeapps型的,就是说每个节点只需要一个就行,这类有GSD(Global Service Daemon)、ONS(Oracle Notification Service Daemon)、VIP、Listener;另一类是Database-Related,就是和数据库相关,不受节点限制,这类有Database、Instance、Service等。
EVMD
该进程负责发布CRS产生的各种事件,同时也是CRSD和CSSD两个进程之间的桥梁。
RACGIMON
该进程负责检查数据库健康状态,负责Service的启动、停止、故障转移等。
OPROCD
在非Linux平台,且没有使用第三方集群软件时才有该进程,用来检测节点的CPU挂起,起过1.5秒会重启节点。
OHASd
Oracle在11gR2引入了OHASd(Oracle High Availability Services Daemon,Oracle高可用服务后台进程),再由它来启动其他的集群件守护进程。
2.3 单实例与RAC环境
1、 单实例与RAC环境对比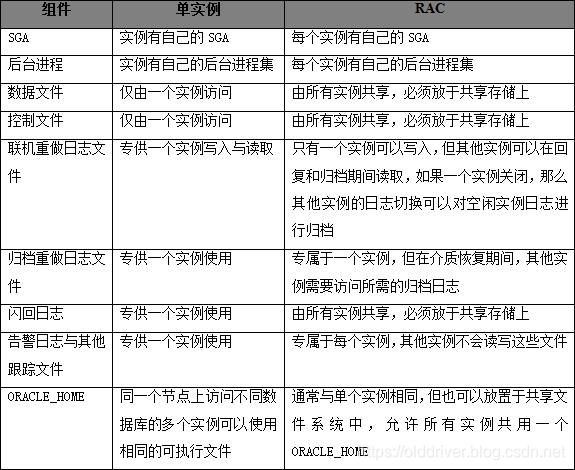
2、 RAC新增的组件和后台进程
RAC的环境中虽然每个实例都有自己的buffer cache与shared pool,但它们现在已经变成全局的,需要特殊处理才能做到没有冲突、无损坏地管理资源,所以也新增了一些单实例环境中没有的组件,最主要的有以下两部分:
3 Oracle 11g RAC集群搭建
该部分详细内容参考我写的RAC的搭建文档
4 维护
4.1 集群维护
CRS有一整套的工具集,它们都出现在$GRID_HOME/bin目录下,在 $ ORACLE_HOME中也有部分CRS工具可用,但Oracle推荐只使用$GRID_HOME/bin目录下的工具集。常用的有crsctl、crs_stat、diagcollection.pl、oifcfg等,下面介绍一些简单的应用。
4.1.1 启动和停止CRS
通常,RAC环境中的CRS都配置成了随机自动启动,但有时候需要调试CRS,或者OS需要维护,或者需要为GI软件打补丁时,需要手工启停CRS,手工启停CRS的命令很简单,与以前版本也是一致的,开启CRS:crsctl start crs,关闭CRS:crsctl stop crs,依旧需要特权用户root来完成CRS的启停。
11g还引入了一个命令集来启停所有节点上运行的全部集群资源,包括数据库实例、ASM、VIP等等资源,非常方便:
Usage: crsctl start cluster [[-all]|[-n <server>[...]]] Start CRS stack where Default Start local server -all Start all servers -n Start named servers server [...] One or more blank-separated server names
例如:
停止所有节点上的css及资源:
crsctl stop cluster -all
启动所有节点上的css及资源:
crsctl start cluster -all
4.1.2 验证CRS
面这些命令用来验证集群及其相关进程的状态(以grid、root用户执行皆可)。
检查一个集群的当前运行状态:
/opt/11.2.0/grid/bin/crsctl check cluster
例如:
[root@node1 bin]# ./crsctl check cluster CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
检查CRS的当前状态:
/opt/11.2.0/grid/bin/crsctl check crs
例如:
[grid@node1 ~]$ crsctl check crs CRS-4638: Oracle High Availability Services is online CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online
检查ohasd进程的状态:
/opt/11.2.0/grid/bin/crsctl check has
例如:
[grid@node1 ~]$ crsctl check has CRS-4638: Oracle High Availability Services is online
检查ctssd进程的状态:
/opt/11.2.0/grid/bin/crsctl check ctss
例如:
[grid@node1 ~]$ crsctl check ctss CRS-4700: The Cluster Time Synchronization Service is in Observer mode.
备注:如果RAC时间的同步是采用第三方软件,比中ntp方式,那么ctss会处于observer状态
4.1.3 禁用与启用CRS
若是不想让CRS随机启动,那么可以disable它:
/opt/11.2.0/grid/bin/crsctl disable crs
如果又改变了注意,可以enable:
/opt/11.2.0/grid/bin/crsctl enable crs
4.1.4 显示集群资源状态
这个功能是11gR2中crsctl新具有的,显示集群资源的状态:
/opt/11.2.0/grid/bin/crsctl stat res -t
该命令与以前的crs_stat -t基本类似
4.1.5 使用oifcfg配置集群网络
该命令包含了获取、删除与设置三部分,分别为oifcfg getif、oifcfg delif、oifcfg setif,更加具体的语法可以通过oifcfg -h来获取到
例如:
[grid@node1 ~]$ oifcfg getif eth0 192.168.100.0 global public eth1 10.10.17.0 global cluster_interconnect
4.1.6 使用diagcollection诊断集群
该工具可以帮助DBA们一次性收集有关所有必需组件的诊断信息,如主机、操作系统、集群等等,这个工具位于$GRID_HOME/bin目录下,默认情况下,该工具将收集完整的诊断信息,但也可以使用正确的选项只收集想要的信息,如下命令只收集CRS的诊断信息:
/oracle/app/grid/product/11.2.0/bin/diagcollection.pl --collect --crs
4.2 管理OCR
OCR用来存储集群数据库的配置信息,对它的管理操作包括备份、恢复、添加、删除以及迁移等等
4.2.1 备份
OCR有自动备份,默认情况下,在集群运行的过程中,每4个小时就会对OCR进行一次备份,并保留最后的3个备份,每天和每周结束时,也会保留相应的一个备份。有几个命令被用来执行OCR备份相关的各种操作,比如查看OCR当前的一些信息并检查OCR是否损坏(用root用户执行):
/opt/11.2.0/grid/bin/ocrcheck
例如:
[root@node1 bin]# ./ocrcheck Status of Oracle Cluster Registry is as follows : Version : 3 Total space (kbytes) : 262120 Used space (kbytes) : 2792 Available space (kbytes) : 259328 ID : 465396144 Device/File Name : +DATA Device/File integrity check succeeded Device/File not configured Device/File not configured Device/File not configured Device/File not configured Cluster registry integrity check succeeded Logical corruption check succeeded
因为OCR的重要,备份OCR是项非常重要的工作,以下命令查看OCR的备份信息:
/opt/11.2.0/grid/bin/ocrconfig -showbackup
切换至root,使用如下命令可以用来手工备份OCR文件(root用户执行):
/opt/11.2.0/grid/bin/ocrconfig -manualbackup
OCR的备份文件是一个二进制文件,但是可以使用ocrdump命令来查看它的内容(同样需要使用root用户):
cd /opt/11.2.0/grid/bin/ ./ocrdump -backupfile /opt/11.2.0/grid/cdata/racdb-cluster/backup00.ocr
为了让word中的显示不太混乱,先cd到了ocrdump命令所在的目录,这个命令会在命令执行的工作目录下生成一个名为OCRDUMPFILE的文本文件
4.2.2 恢复
备份是为了在OCR损坏的关键时刻能够对其进行恢复,下面是一个简单的模拟恢复测试(使用root用户来执行下面这些命令):
在所有节点上执行如下命令来停止crs:
/opt/11.2.0/grid/bin/crsctl stop crs
如果OCR文件已经损坏,那么上述命令可能会报错,在命令中使用“-f”选项强制关停crs,然后在其中一个节点上将crs启动到独占模式:
/opt/11.2.0/grid/bin/crsctl start crs -excl
使用ps命令来观察,如果crsd进程存在,使用如下命令先行关闭该进程:
crsctl stop resource ora.crsd -init
然后再使用ocrconfig命令查看备份文件所在的位置,并找合适的备份来恢复OCR:
/opt/11.2.0/grid/bin/ocrconfig -restore /opt/11.2.0/grid/cdata/racdb-cluster/backup00.ocr
再度使用ocrcheck来检查OCR的状况,如正常,先将当前节点的crs关闭:
/opt/11.2.0/grid/bin/crsctl stop crs -f
crs可以正常启动了。
4.2.3 镜像维护
当前的OCR所在的位置可以通过两个途径得到:一是ocrcheck命令,二是/etc/oracle/ocr.loc文件,既然OCR这么重要,如果使用前面的几个方法得知只有一份OCR的话,那么应该考虑为其创建镜像,OCR只能有一个镜像,也就是说OCR磁盘最多有两个,一个primary ocr,一个mirror ocr,以下操作都可以在crs运行时进行,依旧使用root用户来执行ocrconfig命令:
/opt/11.2.0/grid/bin/ocrconfig -add +ASM_TEST
这里需要注意一点,在11.2版本具是用ASM来存放OCR,用来做OCR的diskgroup,也就是这里的+ASM_TEST,需要满足以下条件:
1) 冗余配置为External时,至少需要300M;冗余配置为Normal的至少需要600M;冗余配置为High的至少需要900M;
2) 该磁盘必须在所有节点上挂载;
3) Compatible.asm参数必须设置至少为11.2(alter diskgroup +ASM_TEST set ATTRIBUTE ‘compatible.asm’=‘11.2’;);
4) 所有节点上,GRID_HOME的权限为“6751”或“-rwsr-s—x”。
下面的命令用来删除多余的OCR:
/opt/11.2.0/grid/bin/ocrconfig -delete +ASM_TEST
4.2.4 移动OCR
有时在维护时可能会更改OCR的磁盘,也就是说将OCR从一个磁盘移动到另一个磁盘,那么也是可以的,只是在移动前必须先给OCR添加镜像OCR,然后再移动,步骤如下:
当前的OCR是DATA,创建镜像DATA1,然后移动到DATA2
opt/11.2.0/grid/bin/ocrconfig -add +DATA1 /opt/11.2.0/grid/bin/ocrconfig -replace +DATA -replacement +DATA2
值得一提的是,ocrconfig还有-export和-import选项可以用来替代上面的备份与恢复过程。
4.2.5 管理OLR
OLR是11gR2引入的,它只存储与当前节点有关的配置信息,可以用ocrconfig命令来查看其信息:
/opt/11.2.0/grid/bin/ocrcheck -local
很多管理ocr的ocrconfig命令可以在添加-local的选项下来对olr进行管理,如前面的-showbackup、-manualbackup等。
4.3 管理Voting Disk
从11gR2开始,无需对Voting Disk进行手工的备份,只要对集群的结构做了任何更改,Voting Disk会被自动备份到OCR中,如果添加了新的Voting Disk,那么Oracle会自动将以前备份的Voting Disk数据恢复到新添加的Voting Disk中。与OCR不同的是,Voting Disk的管理需要使用crsctl命令,下面的命令用来查询Voting Disk的有关信息:
/opt/11.2.0/grid/bin/crsctl query css votedisk
例如:
[grid@node1 ~]$ crsctl query css votedisk ## STATE File Universal Id File Name Disk group -- ----- ----------------- --------- --------- 1. ONLINE 1ed6e4e28dc94fb2bf991a1ff18b818f (ORCL:DATAVG) [DATA] Located 1 voting disk(s).
当Voting Disk在ASM上的时候,不可以使用crsctl add/delete css votedisk命令,唯一可做的操作是可以将Voting Disk搬迁到其他的磁盘组上,不过这样的操作看来也没太多的用武之地,除非想要将其搬迁到冗余度更高的磁盘组上:
/opt/11.2.0/grid/bin/crsctl replace css votedisk +asm_test
4.4 ASM维护
从11gR2开始,Oracle不再支持在dbca建库的时候选择裸设备,因此共享存储部分主要的选择就剩下了ASM,这里也只对ASM的管理进行简单的说明。
在Oracle 11g RAC中,Oracle将ASM集成于GI软件中,现在的Voting Disk与OCR可以放置于ASM上了,这省去了为他们单独创建并管理一些裸设备的麻烦,在GI安装好后ASM实例就创建好并已经启来了,因为CRS要用到OCR和Voting Disk,如果ASM没有启来,CRS就无法读取它们的信息,当然ASM实例创建和ASM磁盘组管理都可以使用图形界面asmca来完成,因此下面这两部分主要以命令为主。
4.4.1 ASM实例创建
要想使用ASM,首要的工作就是创建ASM实例,既然是与数据库实例类似的实例,那么首先就需要有一个参数文件,只不过,ASM实例只需要关注少量的参数,与数据库的实例相比,比较特别的参数如下表所示:
srvctl工具可以用来操作ASM实例,这与以往版本是一样的:srvctl status asm、srvctl start asm与srvctl stop asm,当然具体语法可以使用类似srvctl status asm –h来得到。
4.4.2 磁盘组的创建与删除
我们想要使用ASM,就必须先创建ASM DG(Disk Group),创建磁盘组的时候可以指定冗余策略,分别为:External外部冗余(依靠磁盘RAID),Normal为镜像冗余,而最高级的High则包含了总共三份冗余。创建DG的方法很简单,切换至grid用户,使用sqlplus命令来登录ASM实例:sqlplus ‘/as sysasm’,然后输入如下创建DG的语句:
以grid用户sqlplus / as sysasm登录asm实例,然后执行语句:
create diskgroup data_bak external redundancy disk ‘ORCL:TESTVG’,‘ORCL:TESTVG2’;
很像创建表空间的语法,注意ASM DISK的书写,可以查询v$asm_disk.path字段来得到这些ASM DISK的正确路径。在create diskgroup语句完成后,DG将在当前操作的ASM实例中自动挂载,且添加到ASM实例的asm_diskgroups参数中。其他实例需要手工mount一下:
sqlplus / sysasm alter diskgroup data_bak mount;
删除DG的语句更加简单:
drop diskgroup asm_test;
前提是DG中没有任何内容,否则需要使用如下语句来删除:
drop diskgroup asm_test including contents;
通过以下语句可以查看asm中是否存在该diskgroup:
SQL> select name from v$asm_diskgroup; NAME ------------------------------ DATA DATA_BAK
4.4.3 磁盘组的挂载与卸载
DG只有在当前节点的ASM实例上挂载,才能被该节点的数据库实例访问:
alter diskgroup asm_test mount;
想要dismount一个DG也很简单:
alter diskgroup asm_test dismount;
如果该磁盘组正在被使用,那么可以在语句最后面添加force子句,强制卸载。
可以通过以下语句来查询diskgroup的状态:
SQL> select name,STATE from v$asm_diskgroup; NAME STATE ------------------------------ ----------- DATA MOUNTED DATA_BAK MOUNTED
4.4.4 磁盘的添加与删除
从DG中删除磁盘的操作:
ALTER DISKGROUP dgroupA drop DISK ‘/devices/Disk1’;
添加磁盘:
ALTER DISKGROUP dgroupA ADD DISK ‘/devices/D*‘;
无论是添加磁盘还是删除磁盘,都会触发磁盘组的重平衡,为了减少重平衡的影响,应将删除或者添加磁盘操作一次性完成。还有值得一提的是:在删除磁盘的时候因为需要将删除磁盘上的内容重平衡至其他磁盘,因此删除操作要比较长的时间,在期间可以用如下命令取消删除磁盘的操作:
alter diskgroup asm_test undrop disks;
但如果删除时加上了force关键字,那么这个删除操作就不可逆了。
可以通过以下语句来查看某磁盘是否还存在,以及它们的状态:
SQL> select GROUP_NUMBER,DISK_NUMBER,MOUNT_STATUS,NAME,PATH from v$asm_disk; GROUP_NUMBER DISK_NUMBER MOUNT_S NAME PATH ------------ ----------- ------- -------------------- -------------------- 1 0 CACHED DATAVG ORCL:DATAVG 2 0 CACHED TESTVG ORCL:TESTVG
4.4.5 磁盘组信息的查询
比较常用的几个V视 图 : v 视图:v视图:vasm_diskgroup、va s m d i s k 、 v asm_disk、vasmd?isk、vasm_client,还有两个查询性能统计信息的视图:va s m d i s k s t a t 、 v asm_disk_stat、vasmd?isks?tat、vasm_diskgroup_stat。
4.4.6 磁盘组的重平衡
除了通过ASM的初始化参数asm_power_limit参数来调节重平衡外,也可以使用如下语句来触发重平衡:
alter diskgroup asm_test rebalance power 11 wait;
其中power子句后的数字指定了重平衡的力度,与参数一样,取值范围0~11,但如果这里的值大于asm_power_limit参数,那么这里的指定不起任何作用;最后面的wait子句代表这个命令等待重平衡结束后再返回,如果没有wait,那么该命令立刻返回,当然重平衡操作会在后台继续。
4.4.7 ASM工具
下面两个工具,asmcmd在10g就出现了,asmca是11g才新加入ASM家族的实用工具。
4.5 数据库维护
4.5.1 参数维护
在RAC环境中,Oracle建议使用共享的spfile,在默认的安装下就是如此,而在每个节点oracle用户的$ORACLE_HOME/dbs目录下有一个pfile:init ${ORACLE_SID}.ora,里面有一行参数指定了spfile的所在,比如:
SPFILE=’+ASM_DATA/racdb/spfileracdb.ora’
在这个二进制spfile中,包含了数据库的非默认初始化参数,参数的格式为:
<instance_name>.<parameter_name>=<parameter_value>
如果在instance_name部分使用了“*”或者没有取值,那么意味着这个参数对于所有的实例都是有效的。
与单实例数据库一样,还是可以使用alter system set … 命令来修改参数的值,但是语法却有所不同,这个命令的完整语法为:
alter system set <parameter_name> = <parameter_value> scope = <memory|spfile|both> comment = <’comments’> deferred sid = <sid|*>
其中:
Scope=memory 表明这些改变会在实例重启后丢失,如果某参数只能针对本地实例进行修改,那么这个选项就将使命令报错;
Scope=spfile 表明只在spfile中进行参数的修改,实例重启后生效,如果实例不是使用spfile,而是pfile启动的,那么这个选项也会使得命令报错;
Scope=both 表明所做的参数改动在当前环境有效,且在实例启动后依然有效;
Comment 没什么好说的,注释而已;
Deferred 表明所做的参数修改仅对发出该命令后生成的会话有效;
Sid 使用sid子句允许指定实例名称,使得指定的实例受参数修改的影响,如果使用“*”,那么就针对所有实例进行修改,这是默认取值。
4.5.2 启动和停止实例
Srvctl工具非常强大,在后面将介绍其更多的功能,其中一个简单的应用就是启停RAC数据库。我们可以使用下面两条简单的命令分别来启动、关闭数据库:
srvctl start database -d racdb
srvctl stop database -d racdb -o immediate
这两条命令将对RAC数据库中的所有实例生效,其中stop database时的immediate,与sqlplus中shutdown命令的immediate含义一样,且srvctl命令也支持其他几个诸如normal、transactional、abort等参数,下面的stop instance命令中-o选项所跟的参数也是一样的道理——与10g的时候一样,也可以使用srvctl命令来启停RAC中的单个实例:
srvctl start instance -d racdb -n racdb1
srvctl stop instance -d racdb -n racdb1 -o immedaite
单实例数据库一样,也可以使用sqlplus中的starup与shutdown命令来启停数据库,确切地讲,是启停当前登录的实例,它们的用法与单实例数据库是相同的。
4.5.3 管理UNDO
在RAC数据库中,表空间的管理基本与单实例数据库是一样的,也有但有一个例外:UNDO表空间,在RAC中,每个实例都需要一个自己的UNDO表空间,可以查看初始化参数UNDO_TABLESPACE来了解当前实例所使用的UNDO表空间。
说到UNDO,还是提下单实例数据库中就存在的一个管理操作,就是替换实例的当前UNDO表空间,先创建一个UNDO表空间:
create undo tablespace undo_test datafile size 10m;
再来使用参数切换UNDO表空间:
alter system set undo_tablespace=‘UNDO_TEST‘;
测试了下这个参数的更改有点特别,不能指定sid,且只在当前实例生效。
4.5.4 管理redo log
与单实例数据库不同的是,RAC数据库中,每个实例都有自己的online redo log,自然也有单独的log buffer、单独的归档日志文件。每个数据库实例的redo log称为一个线程,这在v$log、v $archived_log等重要视图中都可得到。
4.5.5 在线日志
日常做的最多的与online redo log相关的管理操作就是添加删除日志了,其实大多时候还是与单实例是一样的,简单的使用如下命令就为当前实例添加一组在线日志:
alter database add logfile group 5 size 10m;
如果想为其他的实例添加日志文件,那么就需要制定实例名:
alter database add logfile instance ‘racdb2‘ group 6 size 10m;
或者
alter database add logfile thread 1 group 6 size 10m;
而删除与单实例相同,只要指定group#即可,无需指定实例名。
4.5.6 归档日志
修改RAC数据库为归档模式或者关闭归档模式的方法也很简单:关闭所有实例,将其中一个实例打开到mount状态,执行如下语句:
alter database archivelog;
语句是与单实例时代是一样的,之后打开所有实例即可。
归档日志的存放可以各实例分离,但是要注意的是,数据库的备份与恢复是在一个实例完成的,因此必须实现归档在各个实例间的共享问题,online redo log也一样,平常正常工作时各个实例对自己的online redo log进行写入,但是在实例恢复时,可能需要读取其他实例的online redo log,因此也需要实现共享。
值得一提的单实例不同的切换日志的命令在RAC中也与单实例有所不同,alter system switch logfile; 命令只能在当前实例进行日志切换,想要在所有实例进行日志切换就需要变通地执行命令:
alter system archive log current;
当然单实例数据库也有这个命令。使用这个命令还可以对指定实例进行日志切换:
alter system archive log instance ‘racdb2‘ current;
最后提一下与日志相关的发出检查点操作的命令,在RAC数据库中也有所不同,以前的alter system checkpoint与alter system checkpoint global; 命令是等价的,将在所有数据库实例中触发检查点操作,若是想要在当前实例触发检查点,那么需要对命令稍作修改:
alter system checkpoint local;
4.5.7 管理服务
服务用来在Oracle RAC环境中来管理工作量,它提供了一种对工作量进行分组的逻辑方法,将采用相同数据集、相同功能以及相同服务级需求的用户分组在一起,因此服务也经常被用来将不同的用户分组的连接“引导”到不同的RAC实例上,从而减少RAC数据库环境中集群方面的相关等待。
早期的版本中可以使用dbca来管理服务,那也是最方便快捷的添加服务的方法,但是在11gR2中,dbca关于服务的这个选项已经被去除了,还可以通过em来进行配置,但Oracle推荐使用上面介绍的srvctl命令来对服务进行管理。
用oracle用户登录,使用如下命令来为racdb数据库创建一个服务ssfxdw,将racdb1定义为首选实例,将racdb2定义为次选实例,且创建basic TAF策略,将服务配置为自动启动:
srvctl add service -d racdb -s ssfxdw -P BASIC -y AUTOMATIC -r racdb1 -a racdb2
动上面创建的服务:
srvctl start service -d racdb -s ssfxdw
关闭服务:
srvctl stop service -d racdb -s ssfxdw
4.5.8 备份与恢复
RAC数据库的实例恢复与崩溃恢复是不一样的概念,虽然两者都只需要读取online redo log,但是实例恢复是指正常实例利用异常终止实例的online redo log,对该实例中被修改但未写入数据文件的数据块进行恢复,所以,RAC数据库的哦你online redo log必须共享;而崩溃恢复是指RAC数据库中的所有实例都出现故障,需要使用online redo log进行恢复;
RAC数据库的介质恢复与单实例基本相同,但是在RAC数据库恢复过程中,需要读取所有实例的归档日志,所以它们的归档日志也必须是共享的。
查看附录中备份与恢复的实例进一步地了解。
4.5.9 查看监听
查看监听状态:
lsnrctl status
启动监听:
lsnrctl start
关闭监听:
lsnrctl stop
4.6 告警日志查看
一般系统出现问题,在我们查看过操作系的CPU、内存、磁盘IO后,往往只了解这些信息是不够的,我们还得从集群软件、ASM、数据库层去查找问题的所在,首先肯定要查看的各个层面的告警日志,那么这日志文件是放在哪里的呢?
/oracle/app/oracle/diag/asm/+asm/+ASM1/trace/alert_+ASM1.log
/oracle/app/oracle/diag/rdbms/orcl/orcl1/trace/alert_orcl1.log
标签:限制 rate 针对 基本 硬件 方便 inf 设备 描述
原文地址:https://www.cnblogs.com/my-first-blog-lgz/p/13896157.html