标签:numa sql语句 浮点数 写入 发送数据 postgresq 重要 pac 自己
数据库管理系统(DBMS)一直以来作为计算机的重要部分,在工业界和学术界都经过了长时间的发展,里面许多的设计技术如scalability、reliability都用到了其它的系统里。
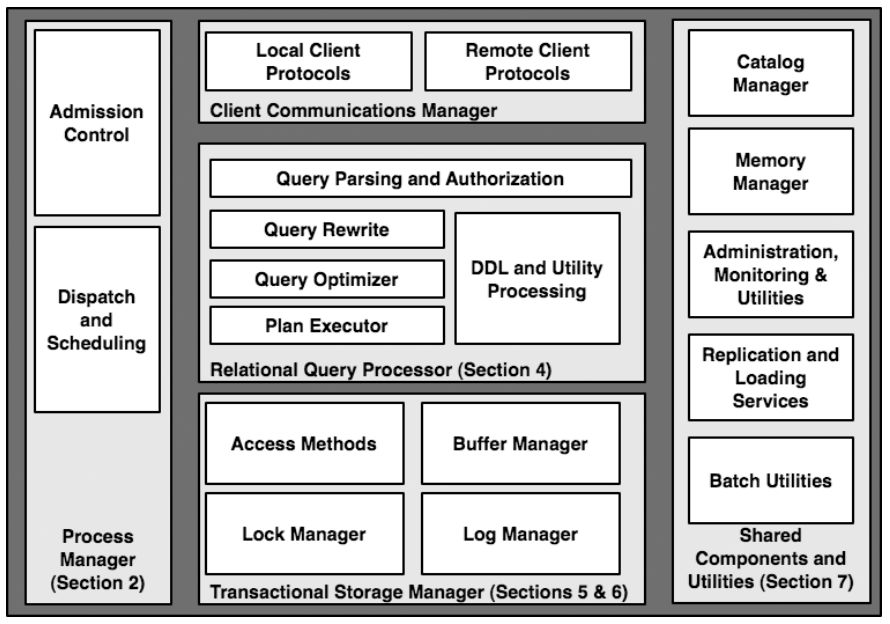
数据库管理系统,尤其是关系型数据库管理系统(RDBMS)在当前的绝大多数应用中都占据核心地位。RDBMS有5个核心组件(如上图所示)。对于一个简单查询,处理流程如下:
多用户模型一直是数据库管理系统重点之一。为简化问题,假设CPU只有一个核,一个DBMS只有一个process,但是有多个thread。
一个DBMS有三种进程模型:每个worker单线程、每个worker单进程、进程池。
单进程模型出现的很早,因为可以直接调用OS的进程接口,由OS scheduler安排每个worker的工作时间。同时进程间内存独立、锁、缓存等功能也由OS提供。
单进程模型在大规模用户缺乏扩展性,目前支持这种模型的数据库有DB2,PostgreSQL,Oracle。
worker每收到一个连接请求,就单独分配一个线程来处理这个请求任务。
单线程的问题在于内存空间不独立,难以debug,race condition等问题。
与单进程不同的是,进程池保持一定数量的进程,当线程超过这个数量时,就需要等待其它进程结束才能开始执行。
数据共享对于单线程模式非常方便,但是对于其它的模式就很麻烦。对于三种进程模型,将数据从DBMS移动到client会涉及到许多buffer。单实际上,所有的共享数据都会设计缓冲区。
Disk I/O buffer是所有的模型都会涉及到的,因为所有的模型肯定可以访问同一数据库下所有的数据。Disk buffer主要分为两类:数据库请求、日志请求。
对于数据库请求,共享数据通过所有worker都可以访问的内存地址进行交流,也即Buffer Pool。
对于日志请求,日志在transaction中会产生日志,这些日志先被存在内存中(log tail),然后周期性的被写入disk中。
在线程模型中,log tail以堆中数据结构存在。在其它进程模型中,通过共享内存来交流日志。
Lock table在所有的worker中共享。
多进程的存储模式分为三种:shared-memory,shared-nothing,shared-disk,分别对应三种不同程度的数据共享模式。
Non-Uniform Memory Access(NUMA)提供了一种cluster中带有独立内存的共享内存编程模型。Cluster内的每个system都可以快速本地内存,但是要访问其它内存速度会相对降低。
当paser得到一个SQL语句后,做的事情有:
对于一个SQL语句,parser首先考虑的就是FROM子句里的表引用,它将表的名称完全展开成server.database.schema.table的格式(根据不同的DB,格式会略有不同)。
然后query processor在catalog manager中找表是否存在,catalog的信息通常会存在一个只存有catalog的cache中,避免在访问大规模数据时被数据换出。
此外,数据类型也会被用来确定一些有歧义的表达式,比如(salary * 1.15) < 7500,这个式子中根据salary属于整型还是浮点数会调用不同的乘法函数。
Rewriter要做的事情很多,但是在实际的DB中rewriter的功能要么在parser部分,要么在optimizer部分。但作为逻辑上单独的一个模块,我们关注一下它的职责即可。
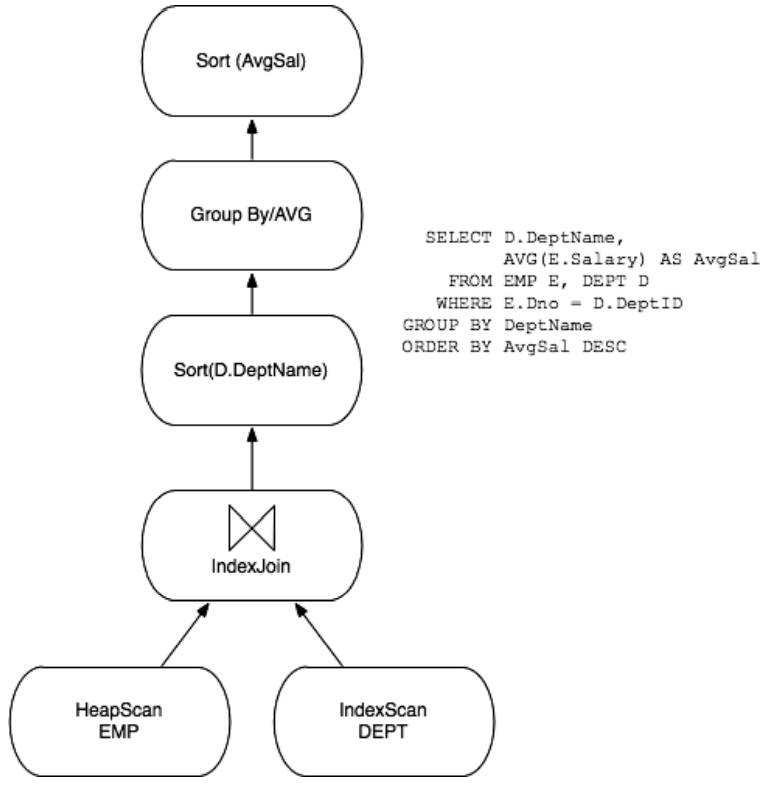
查询计划是以流程图的形式生成的,高层结点不断地从底层结点取得数据,取得数据计算完后将结果交给更上层的结点。过去的优化形式有两种,一种是优化System R生成的字节码,另一种是优化是优化生成的中间计划。历史证明后者比较符合历史发展潮流。现在的优化方向主要有以下几个:
Executor负责执行生成的计划,作用像是一个解释器,觉得大多数的executor都是以迭代器模式执行的,一个简化的迭代器如下所示:

迭代器的一个重要的特点就是数据流和控制流的合并。高层结点向低层结点发送数据请求,底层结点收到请求后计算结果,然后将结果返回给高层结点,同时低层结点的结束控制。由于worker通常是单线程的,所以executor的设计十分的简洁高效,对于多线程或者多进程的解决方案也存在,比如利用生产者消费者模型,这里就不多说了。
一般来说修改数据是比较简单的,只需要直接修改表就可以。但是存在一些情况就需要注意,比如著名的万圣节问题。万圣节问题最早是由System R小组在万圣节当天发现的,问题来自于类似“让工资低于2000的员工工资涨10%”这类修改。当executor通过B+树访问工资时,被涨过的员工工资如果还低于2000就会再次被修改,直到所有的员工工资都超过2000。
解决这种问题的方法有很多。一种简单有效的方法是让optimizer发现有索引的修改直接查找整个表,而不使用索引,但这种方法很多情况下会很低效。另一种方案是批量读写,即预先存下需要搜寻的数据,然后查找预存的数据,在实际数据上进行修改。还有一种方法是针对pipline传输数据的,就是采用多版本控制来保证不会重复修改。
Access methods负责文件访问,包括堆数据和索引访问。现在的数据存在多种不同的索引类型,包括最基本的B+树,对于很多其他格式的数据如文本文件、多重维度数据,也有专门的索引来维持。
最基本的access method提供的接口就是iterator接口,如上图所示。其中init()方法可以接受“search argument”(System R称之为SARG)。如果SARG为NULL,那么就扫描全表。传递SARG的原因有两个。一是一些索引需要SARG传递需要的参数,二是为了性能考虑。比如SARG不传递给下层函数,那么每次下层函数返回结果时,要么将结果放在buff page里(pin值加一),要么放在堆里。如果返回的结果不是期望得到的,那么buff page的pin值会被减一,或者把堆中结果销毁,然后再次调用下层函数。显然,这些步骤十分的耗时。
过去数据库存储的数据格式受到严重限制缺乏扩展性,这种情况现在改善了很多,这里点名表扬PostgreSQL。
抽象数据类型的支持需要在runtime扩展,为了能够实现扩展性,DBMS在parser阶段就需要借助system catalog来实现数据类型的扩展,这种方法中DBMS没有不需要interpret类型,只要调用对应的需要的函数就可以。
DBMS的存储管理有两种,一种是直接控制硬盘,所有的写入读出等操作都是由数据库完成,另一种是利用OS提供的硬盘抽象来管理存储。
硬盘需要管理的原因有很多。硬盘顺序读取速度是随机读取的7到100倍。硬盘的速度增长速度相对CPU、内存来说要慢得多:存储量每18个月翻一倍,访问速度每年增长7%。DBMS通常也比底层的OS更加了解自己的工作模式。因此DBMS对硬盘的控制是很必要的。
但是,直接控制硬盘虽然可以达到极限性能,但也存在一些缺点。首先,需要DBA将一块raw磁盘直接划给DBMS,这样就导致了磁盘的这块不能被OS使用,里面的数据也不能被其它软件复用。同时,磁盘访问接口也要随着OS的不同而变化,导致DB迁移性很差。最后一些新性的存储结构,如RAID、SAN等变得更加流行。这样看来,随着以后发展,对硬盘进行直接控制越来越没有必要。
一种可行的控制裸磁盘的替代方案是向OS申请一个超大的文件,DBMS在内件内划分空间用来存储,这种方法的缺点下一节讨论。
在TPC-C的测试中,大文件方案仅仅比裸磁盘方案慢6%,因此大文件方案更加的受欢迎。
DBMS除了控制磁盘数据存储空间外,还控制数据写入磁盘时间。数据写入时机交给OS处理也是不合理的,OS并不知道合适的写入时机,所以会造成问题。比如ACID保证的失效后的需要保证原子恢复。另一个问题是OS只关注性能,而不在乎数据的正确性。最后就是就是双缓存问题。就直观上来说,何时写入内存本身就是一件值得商榷的事。
还没写完,先发出来吧
红书推荐系列(二):Architecture of a Database System
标签:numa sql语句 浮点数 写入 发送数据 postgresq 重要 pac 自己
原文地址:https://www.cnblogs.com/arch/p/13897727.html