标签:负载均衡 一致性 范围 strong 压力 部分 存储方式 它的 顺时针
一直性Hash算法在很多场景下都有应用,尤其是在分布式缓存系统中,经常用其来进行缓存的访问的负载均衡,比如:redis等<k,v>非关系数据库作为缓存系统。我们首先来看一下采用取模方式进行缓存的问题。
一致性Hash算法的使用场景
假设我们的将10台redis部署为我们的缓存系统,存储<k,v>数据,存储方式是:hash(k)%10,用来将数据分散到各个redis存储系统中。这样做,最大的问题就在于:如果此缓存系统扩展(比如:增加或减少redis服务器的数量),节点故障宕机等将会带来很高的代价。比如:我们业务量增大了,需要扩展我们的缓存系统,再增加一台redis作为缓存服务器,那么后来的数据<k,v>的散列方式变为了:hash(k)%11。我们可以看到,如果我们要查找扩展之前的数据,利用hash(k)%11,则会找不到对应的存储服务器。所以这个时候大量的数据失效了(访问不到了)。
这时候,我们就要进行数据的重现散列,如果是将redis作为存储系统,则需要进行数据迁移,然后进行恢复,但是这个时候就意味着每次增减服务器的时候,集群就需要大量的通信,进行数据迁移,这个开销是非常大的。如果只是缓存,那么缓存就都失效了。这会形成缓存击穿,导致数据库压力巨大,可能会导致应用的崩溃。
一致性Hash算法的原理
因为对于hash(k)的范围在int范围,所以我们将0~2^32作为一个环。其步骤为:
1,求出每个服务器的hash(服务器ip)值,将其配置到一个 0~2^n 的圆环上(n通常取32)。
2,用同样的方法求出待存储对象的主键 hash值,也将其配置到这个圆环上,然后从数据映射到的位置开始顺时针查找,将数据分布到找到的第一个服务器节点上。
其分布如图:
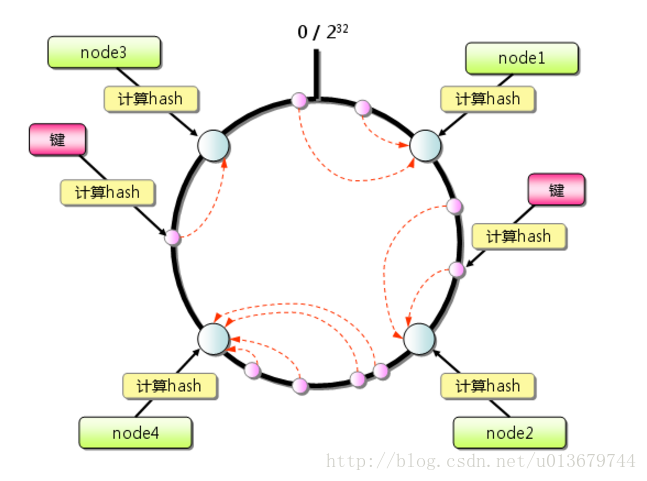
这是一致性hash算法的基本原理,接下来我们看一下,此算法是如何解决 我们上边 说的 缓存系统的扩展或者节点宕机导致的缓存失效的问题。比如:再加入一个redis节点:
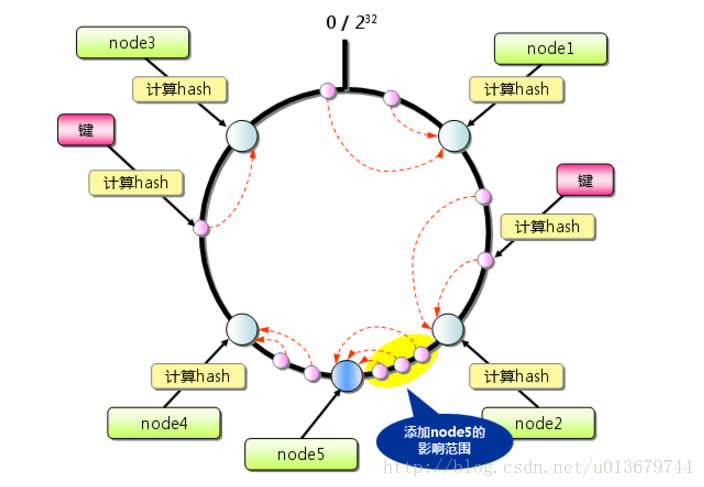
如上图,当我们加入redis node5之后,影响的范围只有黄色标出的那部分,不会造成全局的变动。
除了上边的优点,其实还有一个优点:对于热点数据,如果发现node1访问量明显很大,负载高于其他节点,这就说明node1存储的数据是热点数据。这时候,为了减少node1的负载,我们可以在热点数据位置再加入一个node,用来分担热点数据的压力。
雪崩效应
接下来我们来看一下,当有节点宕机时会有什么问题。如下图:
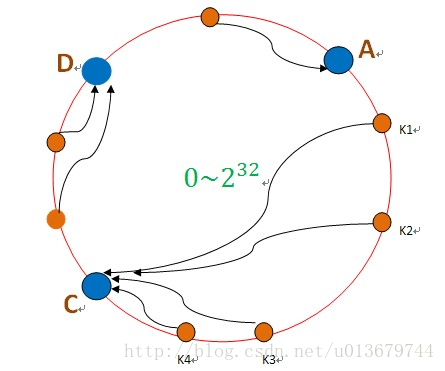
如上图,当B节点宕机后,原本存储在B节点的k1,k2将会迁移到节点C上,这可能会导致很大的问题。如果B上存储的是热点数据,将数据迁移到C节点上,然后C需要承受B+C的数据,也承受不住,也挂了。。。。然后继续CD都挂了。这就造成了雪崩效应。
上面会造成雪崩效应的原因分析:
如果不存在热点数据的时候,每台机器的承受的压力是M/2(假设每台机器的最高负载能力为M),原本是不会有问题的,但是,这个时候A服务器由于有热点数据挂了,然后A的数据迁移至B,导致B所需要承受的压力变为M(还不考虑热点数据访问的压力),所以这个失败B是必挂的,然后C至少需要承受1.5M的压力。。。。然后大家一起挂。。。
所以我们通过上面可以看到,之所以会大家一起挂,原因在于如果一台机器挂了,那么它的压力全部被分配到一台机器上,导致雪崩。
怎么解决雪崩问题呢,这时候需要引入虚拟节点来进行解决。
虚拟节点
虚拟节点,我们可以针对每个实际的节点,虚拟出多个虚拟节点,用来映射到圈上的位置,进行存储对应的数据。如下图:
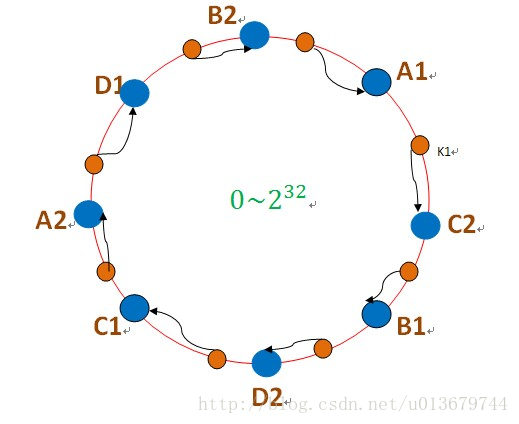
如上图:A节点对应A1,A2,BCD节点同理。这时候,如果A节点挂了,A节点的数据迁移情况是:A1数据会迁移到C2,A2数据迁移到D1。这就相当于A的数据被C和D分担了,这就避免了雪崩效应的发送,而且虚拟节点我们可以自定义设置,使其适用于我们的应用。
标签:负载均衡 一致性 范围 strong 压力 部分 存储方式 它的 顺时针
原文地址:https://www.cnblogs.com/ExMan/p/13907078.html