标签:nic rom ipad 效果 单向链表 优化 修改 公式 条件
前言写数据库,我第一时间就想到了MySQL、Oracle、索引、存储过程、查询优化等等。
不知道大家是不是跟我想得一样,我最想写的是索引,为啥呢?
以下这个面试场景,不知道大家熟悉不熟悉:
面试官:数据库有几千万的数据,查询又很慢我们怎么办?
面试者:加索引。
面试官:那索引有哪些数据类型?索引是怎么样的一种结构?哪些字段又适合索引呢?B+的优点?聚合索引和非聚合索引的区别?为什么说索引会降低插入、删除、修改等维护任务的速度?……..
面试者:面试官怎么出我们公司门来着。
是的大家可能都知道慢了加索引,那为啥加,在什么字段上加,以及索引的数据结构特点,优点啥的都比较模糊或者甚至不知道。
那我们也不多BB了,直接开始这次的面试吧。
我看你简历上写到了熟悉MySQL数据库以及索引的相关知识,我们就从索引开始,索引有哪些数据结构?
Hash、B+
大家去设计索引的时候,会发现索引类型是可以选择的。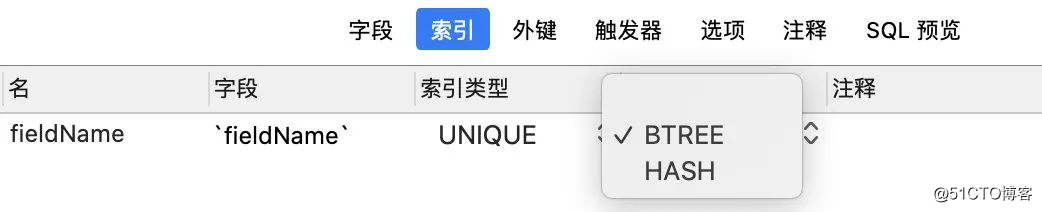
为什么哈希表、完全平衡二叉树、B树、B+树都可以优化查询,为何Mysql独独喜欢B+树?
我先聊一下Hash:
大家可以先看一下下面的动图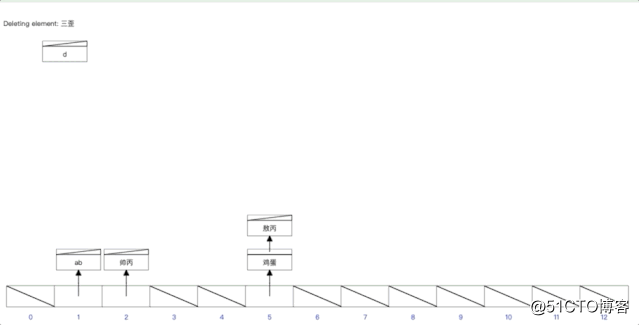
注意字段值所对应的数组下标是哈希算法随机算出来的,所以可能出现哈希冲突。
那么对于这样一个索引结构,现在来执行下面的sql语句:
select * from sanguo where name=‘鸡蛋‘
可以直接对‘鸡蛋’按哈希算法算出来一个数组下标,然后可以直接从数据中取出数据并拿到所对应那一行数据的地址,进而查询那一行数据, 那么如果现在执行下面的sql语句:
select * from sanguo where name>‘鸡蛋‘
则无能为力,因为哈希表的特点就是可以快速的精确查询,但是不支持范围查询。
如果做成了索引,那速度也是很慢的,要全部扫描。
问个题外话,那Hash表在哪些场景比较适合?
等值查询的场景,就只有KV(Key,Value)的情况,例如Redis、Memcached等这些NoSQL的中间件。
你说的是无序的Hash表,那有没有有序的数据结构?
有序数组,它就比较优秀了呀,它在等值查询的和范围查询的时候都很Nice。
那它完全没有缺点么?
不是的,有序的适合静态数据,因为如果我们新增、删除、修改数据的时候就会改变他的结构。
比如你新增一个,那在你新增的位置后面所有的节点都会后移,成本很高。
那照你这么说他根本就不优秀啊,特点也没地方放。
此言差矣,可以用来做静态存储引擎啊,用来保存静态数据,例如你2019年的支付宝账单,2019年的淘宝购物记录等等都是很合适的,都是不会变动的历史数据。
有点东西啊小伙子,那二叉树呢?
二叉树的新增和结构如图: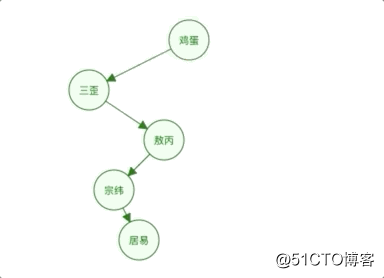
二叉树的结构我就不在这里多BB了,不了解的朋友可以去看看数据结构章节。
二叉树是有序的,所以是支持范围查询的。
但是他的时间复杂度是O(log(N)),为了维持这个时间复杂度,更新的时间复杂度也得是O(log(N)),那就得保持这棵树是完全平衡二叉树了。
怎么听你一说,平衡二叉树用来做索引还不错呢?
此言差矣,索引也不只是在内存里面存储的,还是要落盘持久化的,可以看到图中才这么一点数据,如果数据多了,树高会很高,查询的成本就会随着树高的增加而增加。
为了节约成本很多公司的磁盘还是采用的机械硬盘,这样一次千万级别的查询差不多就要10秒了,这谁顶得住啊?
如果用B树呢?
同理来看看B树的结构: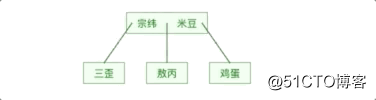
可以发现同样的元素,B树的表示要比完全平衡二叉树要“矮”,原因在于B树中的一个节点可以存储多个元素。
B树其实就已经是一个不错的数据结构,用来做索引效果还是不错的。
那为啥没用B树,而用了B+树?
一样先看一下B加的结构:
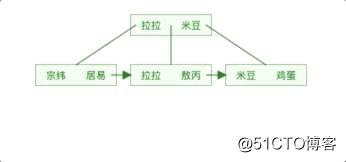
我们可以发现同样的元素,B+树的表示要比B树要“胖”,原因在于B+树中的非叶子节点会冗余一份在叶子节点中,并且叶子节点之间用指针相连。
那么B+树到底有什么优势呢?
其实很简单,我们看一下上面的数据结构,最开始的Hash不支持范围查询,二叉树树高很高,只有B树跟B+有的一比。
B树一个节点可以存储多个元素,相对于完全平衡二叉树整体的树高降低了,磁盘IO效率提高了。
而B+树是B树的升级版,只是把非叶子节点冗余一下,这么做的好处是为了提高范围查找的效率。
提高了的原因也无非是会有指针指向下一个节点的叶子节点。
小结:到这里可以总结出来,Mysql选用B+树这种数据结构作为索引,可以提高查询索引时的磁盘IO效率,并且可以提高范围查询的效率,并且B+树里的元素也是有序的。
那么,一个B+树的节点中到底存多少个元素最合适你有了解过么?
额这个这个?卧*有点懵逼呀。
过了一会还是没想出,只能老实交代:这个不是很了解咳咳。
你可以换个角度来思考B+树中一个节点到底多大合适?
B+树中一个节点为一页或页的倍数最为合适。
为啥?
因为如果一个节点的大小小于1页,那么读取这个节点的时候其实也会读出1页,造成资源的浪费。
如果一个节点的大小大于1页,比如1.2页,那么读取这个节点的时候会读出2页,也会造成资源的浪费。
所以为了不造成浪费,所以最后把一个节点的大小控制在1页、2页、3页、4页等倍数页大小最为合适。
你提到了页的概念,能跟我简单说一下么?
首先Mysql的基本存储结构是页(记录都存在页里边):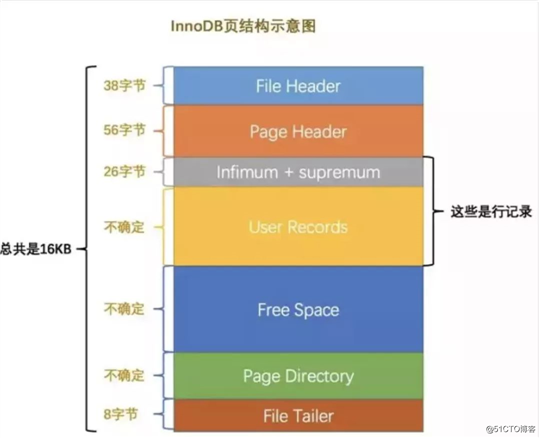
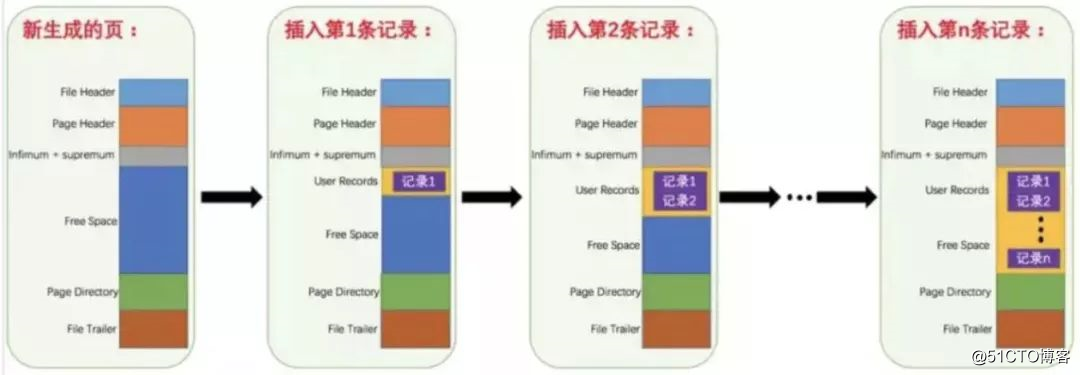
各个数据页可以组成一个双向链表
而每个数据页中的记录又可以组成一个单向链表
所以说,如果我们写 select * from user where username=‘丙丙‘这样没有进行任何优化的sql语句,默认会这样做:
定位到记录所在的页
从所在的页内中查找相应的记录
很明显,在数据量很大的情况下这样查找会很慢!看起来跟回表有点点像。
哦?回表你聊一下。
卧槽,该死,我嘴干嘛。
回表大概就是我们有个主键为ID的索引,和一个普通name字段的索引,我们在普通字段上搜索:
sql select * from table where name = ‘丙丙‘执行的流程是先查询到name索引上的“丙丙”,然后找到他的id是2,最后去主键索引,找到id为2对应的值。
回到主键索引树搜索的过程,就是回表。不过也有方法避免回表,那就是覆盖索引。
哦?那你再跟我聊一下覆盖索引呗?
!!!我这个嘴。。。
这个其实比较好理解,刚才我们是 select * ,查询所有的,我们如果只查询ID那,其实在Name字段的索引上就已经有了,那就不需要回表了。
覆盖索引可以减少树的搜索次数,提升性能,他也是我们在实际开发过程中经常用来优化查询效率的手段。
很多联合索引的建立,就是为了支持覆盖索引,特定的业务能极大的提升效率。
索引的最左匹配原则知道么?
例子:
索引在数据库中是一个非常重要的知识点!
上面谈的其实就是索引最基本的东西,N叉树,跳表、LSM我都没讲,同时要创建出好的索引要顾及到很多的方面:
《MySQL实战》
《高性能MySQL》
最后部分内容来自->java3y《索引和锁》
丁奇《MySQL实战》
之前在B站传了第一个视频:
大家反馈效果还是ok的,我后续会多多尝试的,也希望把改进的建议留言反馈给我。
我去年拍摄了第一个超级粗糙的vlog:
因为拍摄剪辑手法都很垃圾,我就删了,但是最近又想着放上去,在纠结哈哈,想看留个言我就传了哈哈,我们下期间。
今天丙丙也开始了来杭16天后的第一次上班,很开心我们公司在杭州第一批复工的名单中,我已经16天没和人这样说过话了,太开心了,不过不能开空调还得开窗户通风,真的是超级超级冷。
这熟悉的工位,这熟悉的显示器,我的眼角又……
你知道的越多,你不知道的越多,你们是不是好奇我第一版为啥删了,因为有好几处笔误,那篇太急了,嘻嘻所以删了改好了重新发了,加了不少新东西。
对了,次条我抽奖一个2019最新款的ipad送大家,记得去抽奖哟。
标签:nic rom ipad 效果 单向链表 优化 修改 公式 条件
原文地址:https://blog.51cto.com/14689292/2545831