标签:通过 统一 新版 生成 假设 非共享 位置 iter 数据结构
经典开源代码分析——Leveldb高效存储实现导读:LevelDB是Google开源的持久化KV数据库,在其高性能的背后,将数据拆分成多层进行存储。本文作者深入分析了LevelDB存储模块的设计和源码实现,快速了解LevelDB高性能背后的原理。
作者 codedump codedump.info 博主,多年从事互联网服务器后台开发工作。可访问作者博客阅读 codedump 更多文章。
本文基于leveldb 1.9.0代码。
整体架构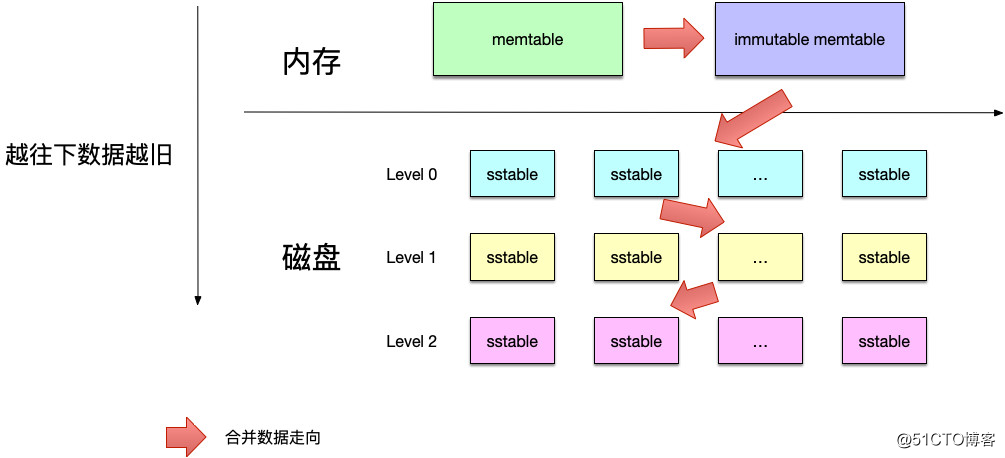
如上图,leveldb的数据存储在内存以及磁盘上,其中:
在上面这个存储层次中,越靠上的数据越新,即同一个键值如果同时存在于memtable和immutable memtable中,则以memtable中的为准。
另外,图中还使用箭头来表示了合并数据的走向,即:
以下将针对这几部分展开讨论。
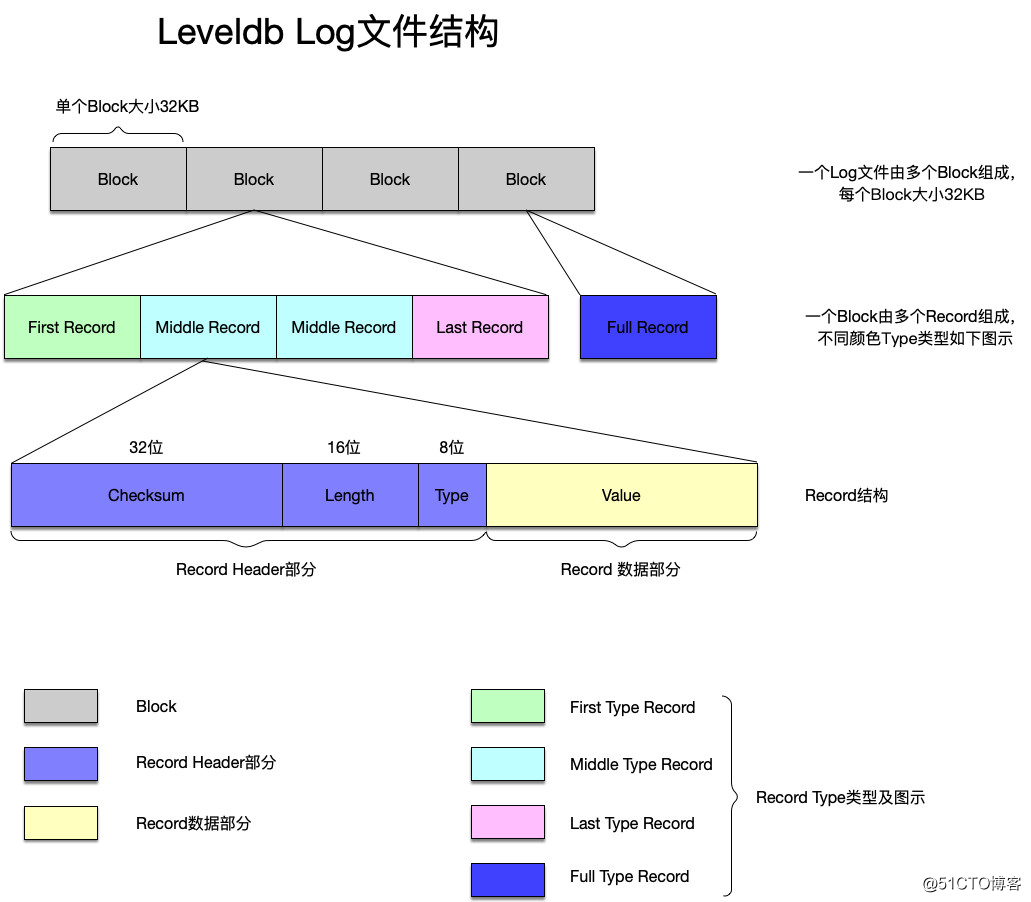
Log文件
写入数据的时候,最开始会写入到log文件中,由于是顺序写入文件,所以写入速度很快,可以马上返回。
来看Log文件的结构:
memtable
memtable用于存储在内存中还未落盘到sstable中的数据,这部分使用跳表(skiplist)做为底层的数据结构,这里先简单描述一下跳表的工作原理。
如果数据存放在一个普通的有序链表中,那么查找数据的时间复杂度就是O(n)。跳表的设计思想在于:链表中的每个元素,都有多个层次,查找某一个元素时,遍历该链表的时候,根据层次来跳过(skip)中间某些明显不满足需求的元素,以达到加快查找速度的目的,如下图所示: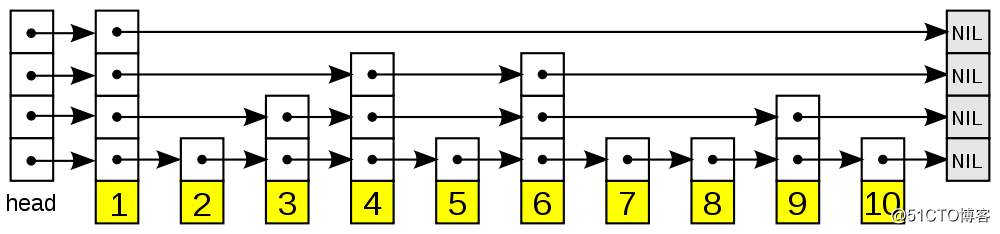
在以上这个跳表中,查找元素6的流程,大体如下:
从上面的分析过程中可以看到:
大体结构
首先来看sstable文件的整体结构,如下图: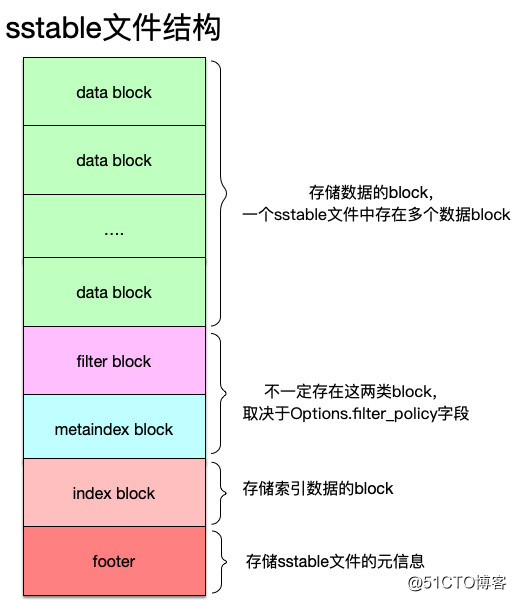
sstable文件中分为以下几个组成部分:
可以看到,上面这几部分数据,从文件的组织来看自上而下,先有了数据再有索引数据,最后才是文件自身的元信息。原因在于:索引数据是针对数据的索引信息,在数据没有写完毕之前,索引信息还会发生改变,所以索引数据要等数据写完;而元信息就是针对索引数据的索引,同样要依赖于索引信息写完毕才可以。
block
上面几部分数据中,除去footer之外,内部都是以block的形式来组织数据,接着看block的结构,如下图: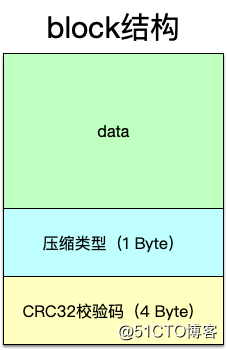
从上面看出,实际上存储数据的block大同小异:最开始的一部分存储数据,然后存储类型,最后一部分存储这个block的校验码以做合法性校验。
以上只是对block大体结构的分析,在数据部分,每一条数据记录leveldb使用前缀压缩(prefix-compressed)方式来存储。这种算法的原理是:针对一组数据,取出一个公共的前缀,而在该组中的其它字符串只保存非公共的字符串做为key即可,由于sstable保存KV数据是严格按照key的顺序来排序的,所以这样能节省出保存key数据的空间来。
如下图所示:一个block内部划分了多个记录组(record group),每个记录组内部又由多条记录(record)组成。在同一个记录组内部,以本组的第一条数据的键值做为公共前缀,后续的记录数据键值部分只存放与公共前缀非共享部分的数据即可。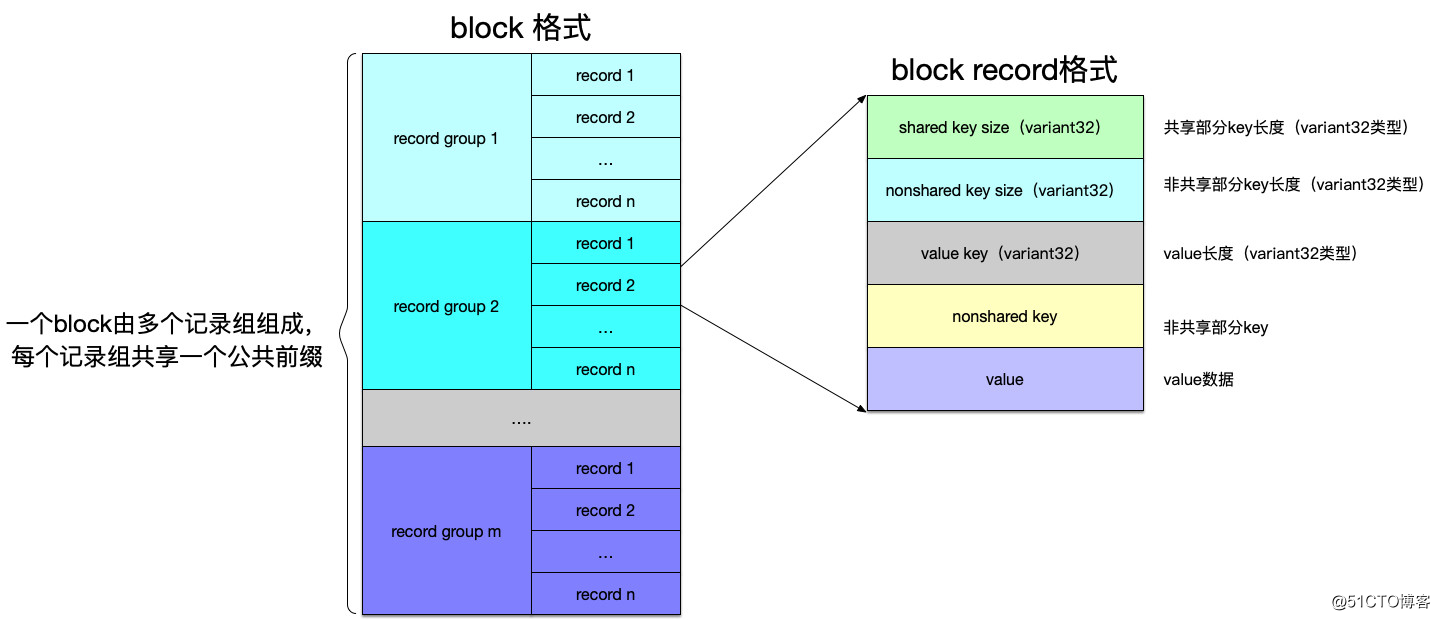
以记录的三个数据<a,test>、<ab,test2>、<c,test3>为例,假设这三个数据在同一个record group内,那么对应的record记录如下所示:
说明如下:
因为一个block内部有多个记录组,因此还需要另外的数据来记录不同记录组的位置,这部分数据被称为“重启点(restart point)”,重启点首先会以数组的形式保存下来,直到该block数据需要落盘的情况下才会写到block结尾处。
有了以上的准备,就可以来具体看添加数据的代码了,向一个block中添加数据的伪代码如下。
有了前面的这些准备,再在前面block格式的基础上展开,得到更加详细的格式如下: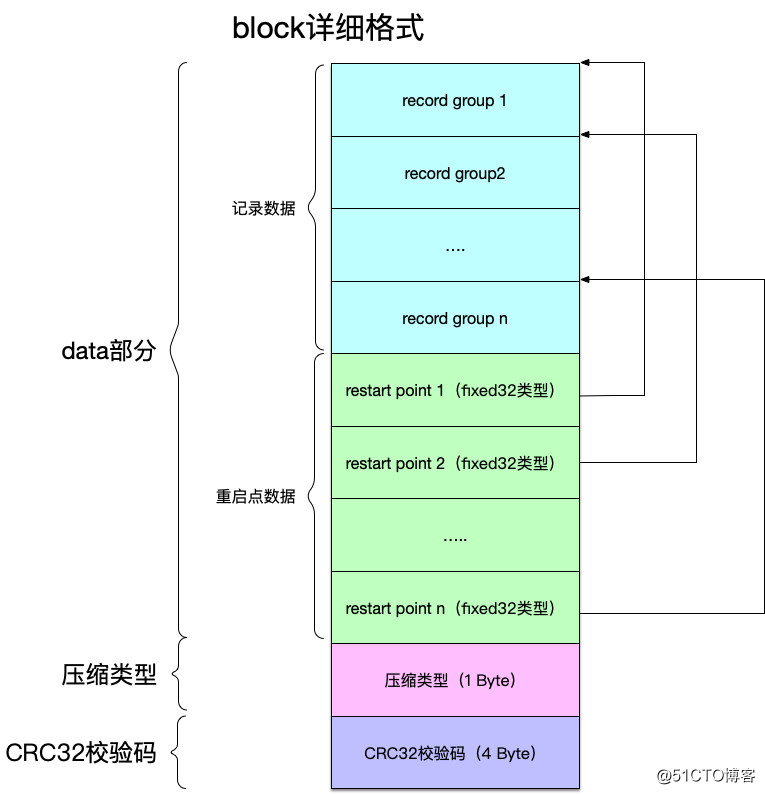
block详细格式还是划分为三大部分,其中:
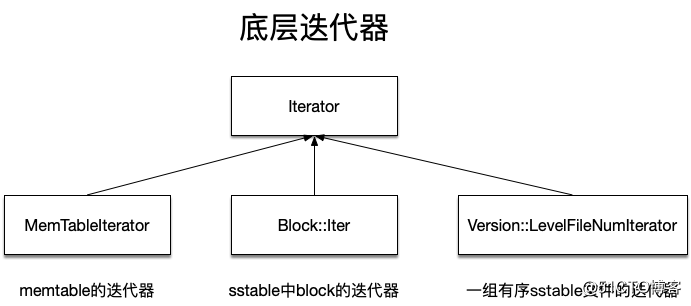
迭代器的设计是leveldb中的一大亮点,leveldb设计了一个虚拟基类Iterator,其中定义了诸如遍历、查询之类的接口,而该基类有多种实现。原因在于:leveldb中存在多种数据结构和多种使用场景,如:
逐个来看不同的iterator实现以及其使用场景。
迭代器大体分为两类:
底层迭代器:处于最底层,直接访问底层数据结构,而不依赖于其他迭代器的迭代器。
组合迭代器:组合各种迭代器(包括底层和组合迭代器)完成工作的迭代器。
底层迭代器
底层迭代器有以下三种:
组合迭代器
组合迭代器内部都包含至少一个迭代器,组合起来完成迭代工作,有如下几类。
TwoLevelIterator
顾名思义,TwoLevelIterator表示两层迭代器,创建TwoLevelIterator的函数原型为:
参数说明如下:
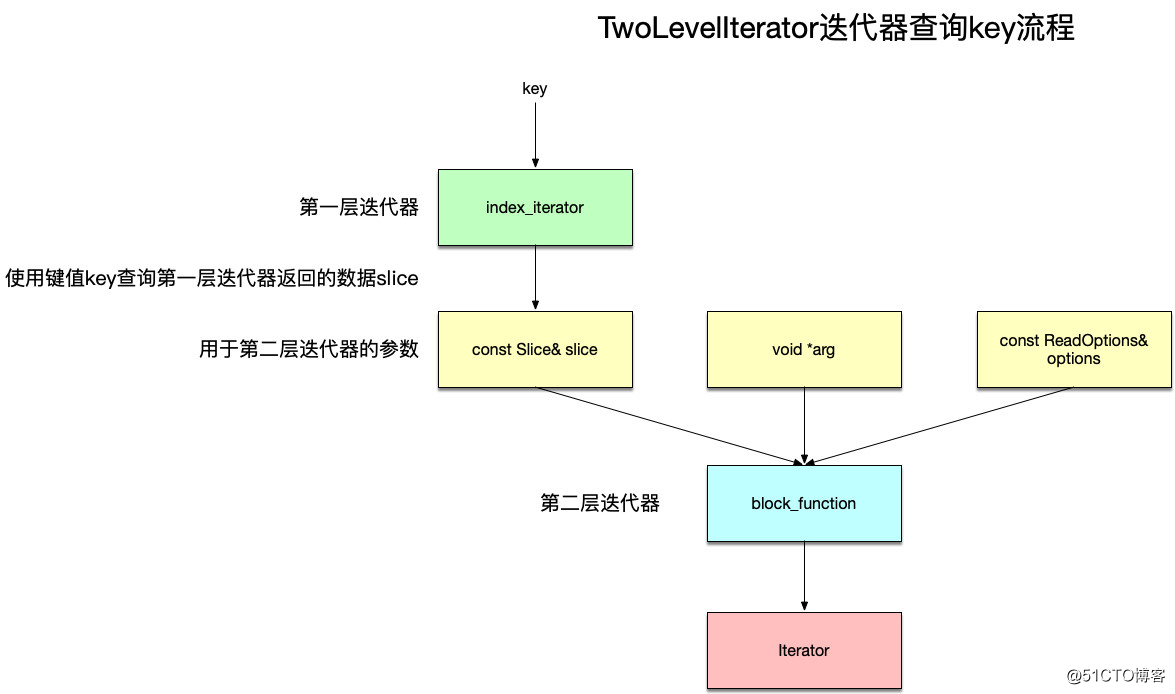
TwoLevelIterator有如下两类:
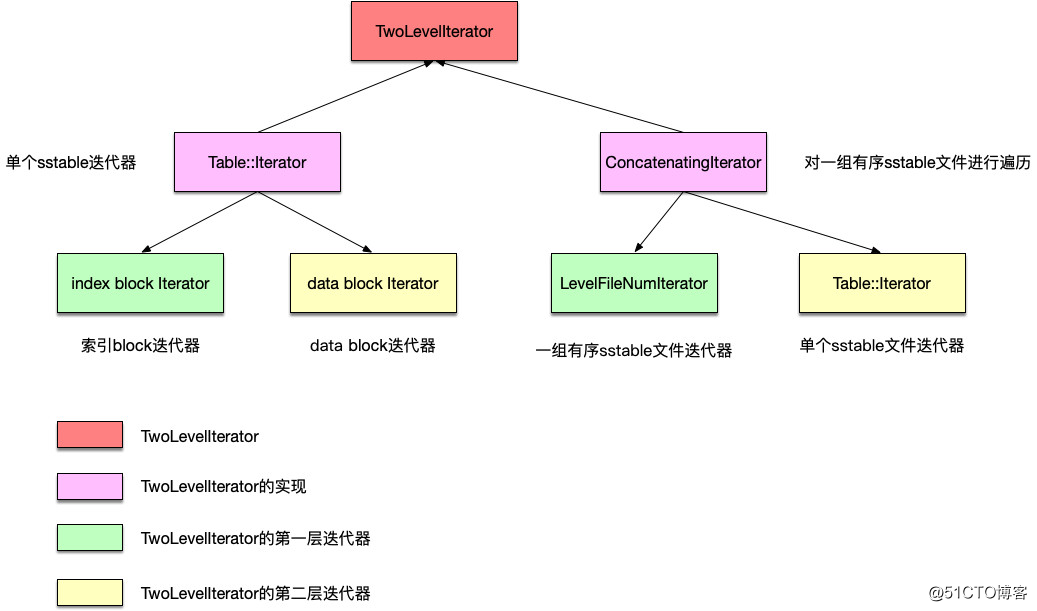
MergingIterator
用于合并流程的迭代器。在合并过程中,需要操作memtable、immutable memtable、level 0 sstable以及非level 0的sstable,该迭代器将这些存储数据结构体的迭代器,统一进行归并排序:
level 1层级及以上的sstable:使用前面介绍过的ConcatenatingIterator,即可以针对一组有序sstable文件进行遍历的iterator。
可以看到,current_以及direction_两个成员是用于保存当前查找状态的成员。
构建MergingIterator迭代器传入的Comparator是InternalKeyComparator,其比较逻辑是:
Seek(target)函数的伪代码:
而FindSmallest函数的实现,是遍历children_找到最小的child保存到current_指针中。前面分析InternalKeyComparator提到过,相同键值的数据,根据sequence值进行降序排列,即数据越新的数据其sequence值越大,在这个排序中查找的结果就越在上面。因此,FindSmallest函数如果在memtable、level 0中都找到了相同键值,将优先选择memtable中的数据。
MergingIterator迭代器的其它实现不再做解释,简单理解:针对一组iterator的查询结果进行归并排序。对于同样一个键值,只取位置在存储位置上最靠上面的数据。
这么做的原因在于:一个键值的数据可能被写入多次,而需要以最后一次写入的数据为准,合并时将丢弃掉不在存储最上面的数据。
以下面的例子来说明MergingIterator迭代器的合并结果。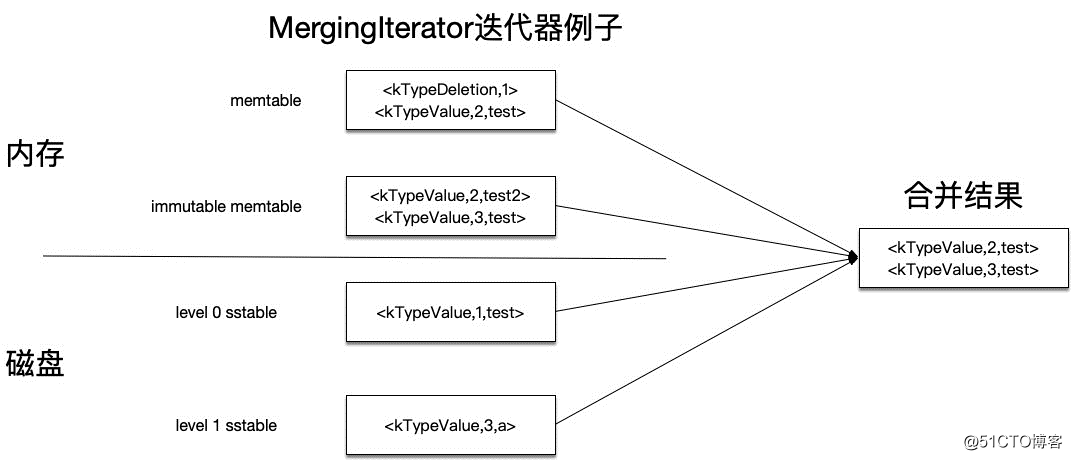
在上图的左半边,是合并前的数据分布情况,依次为:
合并的结果如上图的右边所示:
有了前面几种核心数据结构的了解,下面谈leveldb中的几个核心流程。
修改流程
修改数据,分为两类:正常的写入数据操作以及删除数据操作。
先看正常的写入数据操作:
完成以上两步之后,就可以认为完成了更新数据的操作。实际上只有一次文件末尾的顺序写操作,以及一次写内存操作,如果不考虑会被合并操作阻塞的情况,实际上还是很快的。
再来看删除数据操作。leveldb中,删除一个数据,其实也是添加一条新的记录,只不过记录类型是删除类型,代码中通过枚举变量定义了这两种操作类型:
这样看起来,leveldb删除数据时,并不会真的去删除一条数据,而是打上了一个标记,那么问题就来了:如果写入数据操作与删除数据操作,只是类型不同,在查询数据的时候又如何知道数据是否存在?看下面的读数据流程。
读流程
向leveldb中查询一个数据,也是从上而下,先查内存然后到磁盘上的sstable文件查询,如下图所示: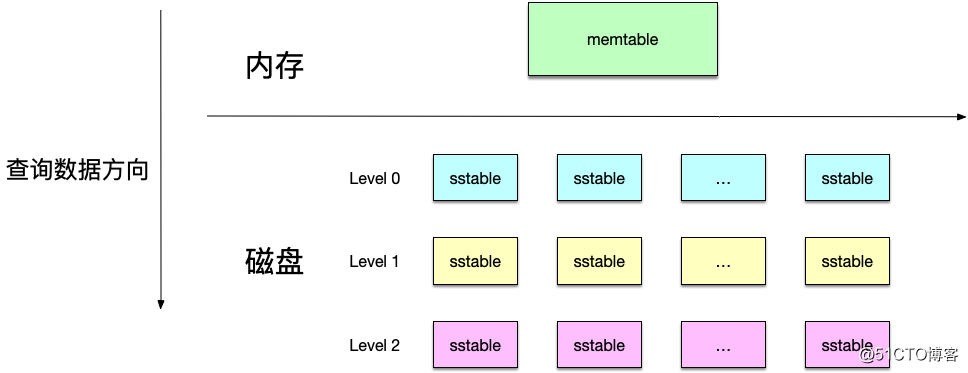
这样自上而下的原因就在于leveldb的设计:越是在上层的数据越新,距离当前时间越短。
举例而言,对于键值key而言,首先写入kv对<key,data>,然后再删除键值key数据。第一次写入的数据,可能因为合并的原因以及到了sstable文件上,而再次删除键值key的数据时,根据上面的解释,其实也是写入数据,只不过标记为删除。于是,越后写入的数据,越在上面这个层次的上面,这样从上往下查询时就能先查找到后写入的数据,此时看到了数据已经被标记为删除,就可以认为数据不存在了。
那么,前面写入的数据实际上已经没有用了,但是又占用了空间,这部分数据就等待着后面的合并流程来合并数据最后删除掉。
合并流程
核心数据结构
首先来看与合并相关的核心数据结构。
每一次合并过程以及将memtable中的数据落盘到sstable的过程,都涉及到sstable文件的增删,而这每一次操作,都对应到一个版本。
在leveldb中,使用Version类来存储一个版本的元信息,主要包括:
可以看到,Version保存的主要是两类数据:当前sstable文件的信息,以及下一次合并时的信息。
所有的级别,也就是Version类,使用双向链表串联起来,保存到VersionSet中,而VersionSet中有一个current指针,用于指向当前的Version。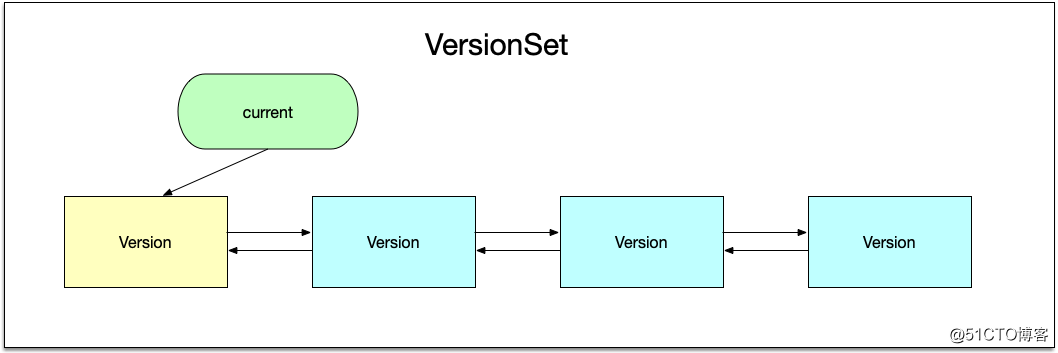
当进行合并时,首先需要挑选出需要进行合并的文件,这个操作的入口函数是VersionSet::PickCompaction,该函数的返回值是一个Compaction结构体,该结构体内部保存合并相关的信息,Compaction结构体中最重要的成员是VersionEdit类成员,这个成员用于保存合并过程中有删减的sstable文件:
newfiles:合并后新增的sstable文件。
可以认为:version N + version N edit = version N + 1,即:第N版本的sstable信息,在经过该版本合并的VersionEdit之后,形成了Version N+1版本。
另外还有一个VersionSet::Builder,用于保存合并中间过程的数据,其本质是将所有VersoinEdit内容存储到VersionSet::Builder中,最后一次产生新版本的Version。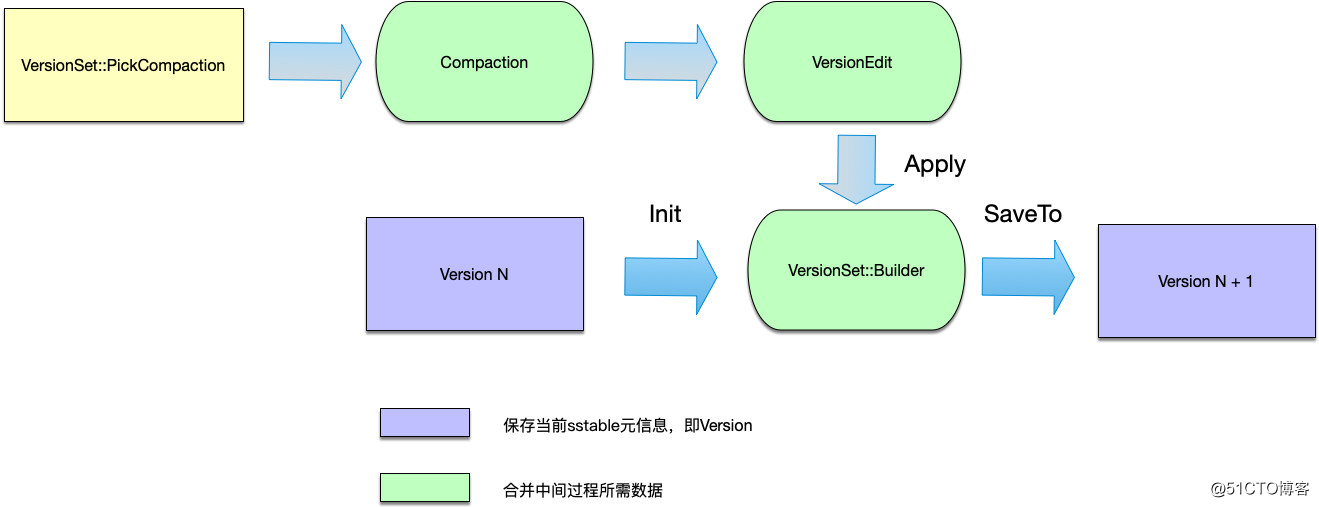
合并条件及原理
leveldb会不断产生新的sstable文件,这时候需要对这些文件进行合并,否则磁盘会一直增大,查询速度也会下降。
这部分讲解合并触发的条件以及进行合并的原理。
leveldb大致在以下两种条件下会触发合并操作:
以上两种情况,对应到leveldb代码中就是以下几个地方:
另外还需要提一下合并的两种类型:
选择进行合并的文件
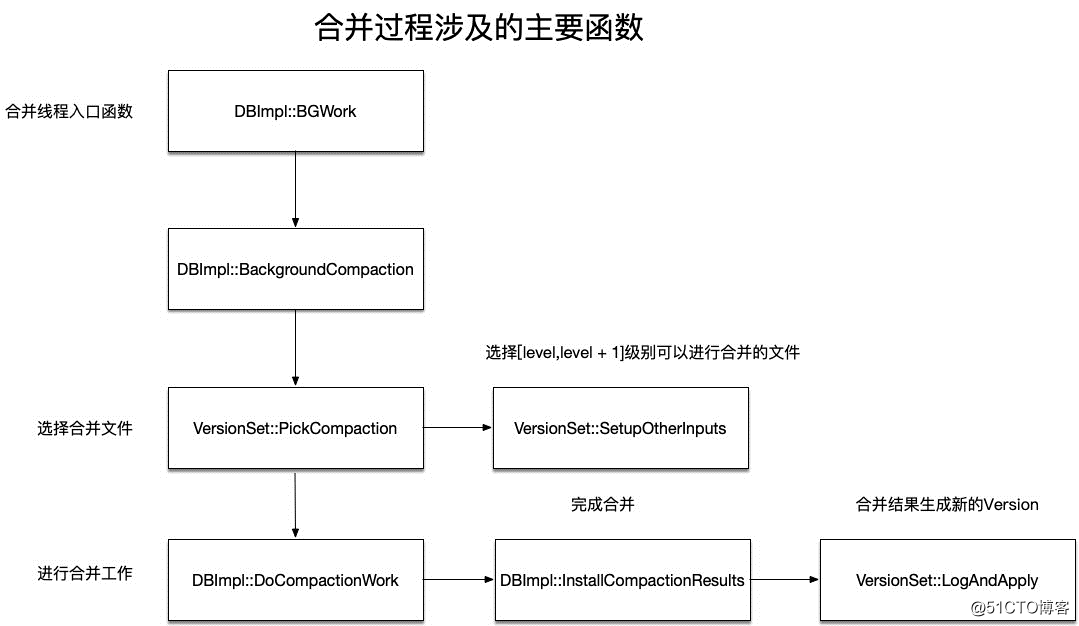
函数VersionSet::PickCompaction用于构建出一次合并对应的Compaction结构体。来看这个函数主要的流程。
在挑选哪些文件需要合并时,依赖于两个原则:
文件的allowed_seeks在VersionSet::Builder::Apply函数中进行计算:
如果是第一种情况,即compactionscore >= 1的情况来选择合并文件,还涉及到一个合并点的问题(compact point),即leveldb会保存上一次进行合并的键值,这一次会从这个键值以后开始寻找需要进行合并的文件。
而如果合并层次是0级,因为0级文件中的键值有重叠的情况,因此还需要遍历0级文件中键值范围与这次合并文件由重叠的一起加入进来。
在这之后,调用VersionSet::SetupOtherInputs函数,用于获取同级别以及更上一层也就是level + 1级别中满足合并范围条件的文件,这就构成了待合并的文件集合。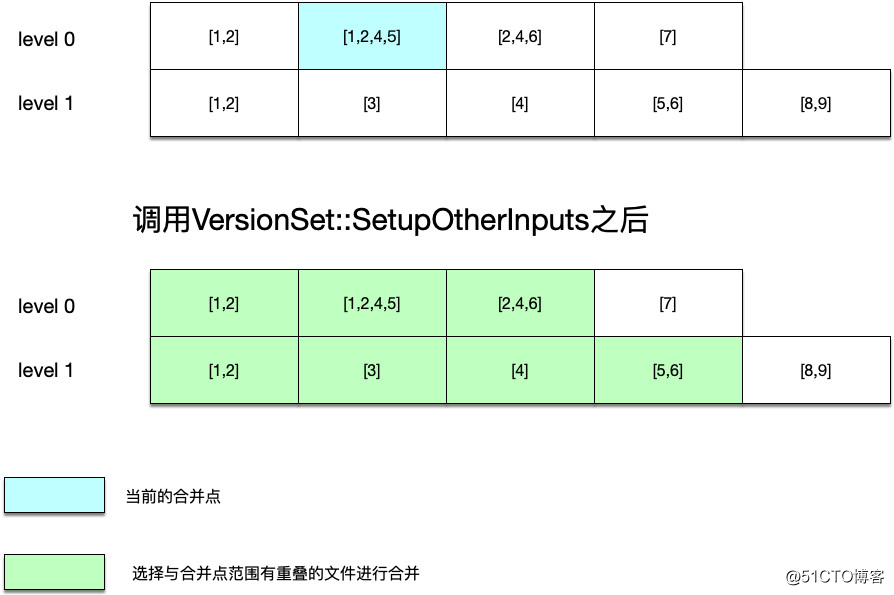
如上图所示:
合并流程
以上调用VersionSet::PickCompaction函数选择完毕了待合并的文件及层次之后,就来到DBImpl::DoCompactionWork函数中进行实际的合并工作。
该函数的原理不算复杂,就是遍历文件集合进行合并:
合并操作对读写流程的影响
leveldb将用户的读写操作,与合并工作放在不同的线程中处理。当用户需要写入数据进行分配空间时,会首先调用DBImpl::MakeRoomForWrite函数进行空间的分配,该函数有可能因为合并流程被阻塞,有以下几种可能性:
参考资料
相关阅读
Go存储怎么写?深度解析etcd存储设计
深入浅出 Redis 持久化机制
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。

标签:通过 统一 新版 生成 假设 非共享 位置 iter 数据结构
原文地址:https://blog.51cto.com/14977574/2546662