标签:概念 流程 snapshot 新技术 微信群 等级 格式 seq 上下文
解密未来数据库设计:MongoDB新存储引擎WiredTiger实现(事务篇)导语:计算机硬件在飞速发展,数据规模在急速膨胀,但是数据库仍然使用是十年以前的架构体系,WiredTiger 尝试打破这一切,充分利用多核与大内存时代,开发一种真正满足未来大数据管理所需的数据库。本文由袁荣喜向「高可用架构」投稿,介绍对 WiredTiger 源代码学习过程中对数据库设计的感悟。
 袁荣喜,学霸君工程师,2015年加入学霸君,负责学霸君的网络实时传输和分布式系统的架构设计和实现,专注于基础技术领域,在网络传输、数据库内核、分布式系统和并发编程方面有一定了解。
袁荣喜,学霸君工程师,2015年加入学霸君,负责学霸君的网络实时传输和分布式系统的架构设计和实现,专注于基础技术领域,在网络传输、数据库内核、分布式系统和并发编程方面有一定了解。
WiredTiger 从被 MongoDB 收购到成为 MongoDB 的默认存储引擎的一年半,得到了迅猛的发展,也逐步被外部熟知。
现代计算机近 20 年来 CPU 的计算能力和内存容量飞速发展,但磁盘的访问速度并没有得到相应的提高,WT 就是在这样的一个情况下研发出来,它设计了充分利用 CPU 并行计算的内存模型的无锁并行框架,使得 WT 引擎在多核 CPU 上的表现优于其他存储引擎。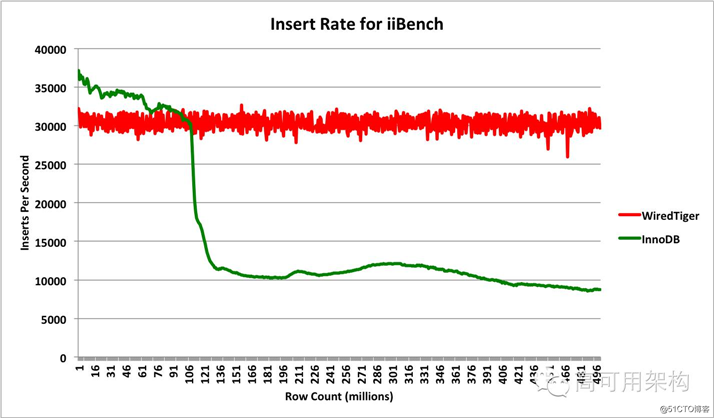
针对磁盘存储特性,WT 实现了一套基于 BLOCK/Extent 的友好的磁盘访问算法,使得 WT 在数据压缩和磁盘 I/O 访问上优势明显。实现了基于 snapshot 技术的 ACID 事务,snapshot 技术大大简化了 WT 的事务模型,摒弃了传统的事务锁隔离又同时能保证事务的 ACID。WT 根据现代内存容量特性实现了一种基于 Hazard Pointer 的 LRU cache 模型,充分利用了内存容量的同时又能拥有很高的事务读写并发。
在本文中,我们主要针对 WT 引擎的事务来展开分析,来看看它的事务是如何实现的。说到数据库事务,必然先要对事务这个概念和 ACID 简单的介绍。
什么是事务?
事务就是通过一系列操作来完成一件事情,在进行这些操作的过程中,要么这些操作完全执行,要么这些操作全不执行,不存在中间状态,事务分为事务执行阶段和事务提交阶段。一般说到事务,就会想到它的特性— ACID,那么什么是 ACID 呢?我们先用一个现实中的例子来说明:AB 两同学账号都有 1,000 块钱,A 通过银行转账向 B 转了 100,这个事务分为两个操作,即从 A 同学账号扣除 100,向 B 同学账号增加 100。
原子性(Atomicity)
组成事务的系列操作是一个整体,要么全执行,要么不执行。通过上面例子就是从 A 同学扣除钱和向 B 同学增加 100 是一起发生的,不可能出现扣除了 A 的钱,但没增加 B 的钱的情况。
一致性(Consistency):
在事务开始之前和事务结束以后,数据库的完整性和状态没有被破坏。这个怎么理解呢?就是 A、B 两人在转账钱的总和是 2,000,转账后两人的总和也必须是 2,000。不会因为这次转账事务破坏这个状态。
隔离性(Isolation):
多个事务在并发执行时,事务执行的中间状态是其他事务不可访问的。A 转出 100 但事务没有确认提交,这时候银行人员对其账号查询时,看到的应该还是 1,000,不是 900。
持久性(Durability)
事务一旦提交生效,其结果将永久保存,不受任何故障影响。A 转账一但完成,那么 A 就是 900,B 就是 1,100,这个结果将永远保存在银行的数据库中,直到他们下次交易事务的发生。
知道了基本的事务概念和 ACID 后,来看看 WT 引擎是怎么来实现事务和 ACID。要了解实现先要知道它的事务的构造和使用相关的技术,WT 在实现事务的时使用主要是使用了三个技术:
为了实现这三个技术,它还定义了一个基于这三个技术的事务对象和全局事务管理器。事务对象描述如下
wt_transaction{
transaction_id: 本次事务的全局唯一的ID,用于标示事务修改数据的版本号
snapshot_object: 当前事务开始或者操作时刻其他正在执行且并未提交的事务集合,用于事务隔离
operation_array: 本次事务中已执行的操作列表,用于事务回滚。
redo_log_buf: 操作日志缓冲区。用于事务提交后的持久化
State: 事务当前状态
}
WT 中的 MVCC 是基于 key/value 中 value 值的链表,这个链表单元中存储有当先版本操作的事务 ID 和操作修改后的值。描述如下:
wt_mvcc{
transaction_id: 本次修改事务的ID
value: 本次修改后的值
}

WT 中的数据修改都是在这个链表中进行 append 操作,每次对值做修改都是 append 到链表头上,每次读取值的时候读是从链表头根据值对应的修改事务 transaction_id 和本次读事务的 snapshot 来判断是否可读,如果不可读,向链表尾方向移动,直到找到读事务能都的数据版本。样例如下: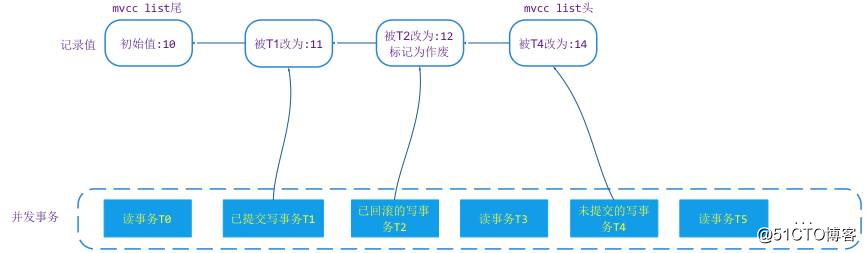
图1,点击图片可以全屏缩放
上图中,事务 T0 发生的时刻最早,T5 发生的时刻最晚。T1/T2/T4 是对记录做了修改。那么在 MVCC list 当中就会增加 3 个版本的数据,分别是 11/12/14。如果事务都是基于 snapshot 级别的隔离,T0 只能看到 T0 之前提交的值 10,读事务 T3 访问记录时它能看到的值是 11,T5 读事务在访问记录时,由于 T4 未提交,它也只能看到 11 这个版本的值。这就是 WT 的 MVCC 基本原理。
上面多次提及事务的 snapshot,那到底什么是事务的 snapshot 呢?其实就是事务开始或者进行操作之前对整个 WT 引擎内部正在执行或者将要执行的事务进行一次快照,保存当时整个引擎所有事务的状态,确定哪些事务是对自己见的,哪些事务都自己是不可见。说白了就是一些列事务 ID 区间。WT 引擎整个事务并发区间示意图如下:
图2,点击图片可以全屏缩放
WT 引擎中的 snapshot_oject 是有一个最小执行事务 snap_min、一个最大事务 snap max 和一个处于 [snap_min, snap_max] 区间之中所有正在执行的写事务序列组成。如果上图在 T6 时刻对系统中的事务做一次 snapshot,那么产生的
snapshot_object = {
snap_min=T1,
snap_max=T5,
snap_array={T1, T4, T5},
};
T6 能访问的事务修改有两个区间:所有小于 T1 事务的修改 [0, T1) 和 [snap_min, snap_max] 区间已经提交的事务 T2 的修改。换句话说,凡是出现在 snap_array 中或者事务 ID 大于 snap_max 的事务的修改对事务 T6 是不可见的。如果 T1 在建立 snapshot 之后提交了,T6 也是不能访问到 T1 的修改。这个就是 snapshot 方式隔离的基本原理。
通过上面的 snapshot 的描述,我们可以知道要创建整个系统事务的快照截屏,就需要一个全局的事务管理来进行事务快照时的参考,在 WT 引擎中是如何定义这个全局事务管理器的呢?在 CPU 多核多线程下,它是如何来管理事务并发的呢?下面先来分析它的定义:
wt_txn_global{
current_id: 全局写事务ID产生种子,一直递增
oldest_id: 系统中最早产生且还在执行的写事务ID
transaction_array: 系统事务对象数组,保存系统中所有的事务对象
scan_count: 正在扫描transaction_array数组的线程事务数,用于建立snapshot过程的无锁并发
}
transaction_array 保存的是图 2 正在执行事务的区间的事务对象序列。在建立 snapshot 时,会对整个 transaction_array 做扫描,确定 snap_min/snap_max/snap_array 这三个参数和更新 oldest_id,在扫描的过程中,凡是 transaction_id 不等于 WT_TNX_NONE 都认为是在执行中且有修改操作的事务,直接加入到 snap_array 当中。整个过程是一个无锁操作过程,这个过程如下: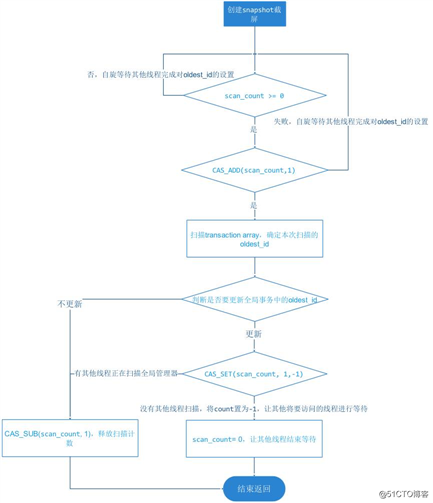
图3,点击图片可以全屏缩放
创建 snapshot 快照的过程在 WT 引擎内部是非常频繁,尤其是在大量自动提交型的短事务执行的情况下,由创建 snapshot 动作引起的 CPU 竞争是非常大的开销,所以这里 WT 并没有使用 spin lock,而是采用了上图的一个无锁并发设计,这种设计遵循了我们开始说的并发设计原则。
从 WT 引擎创建事务 snapshot 的过程中,现在可以确定,snapshot 的对象是有写操作的事务,纯读事务是不会被 snapshot 的,因为 snapshot 的目的是隔离 MVCC list 中的记录,通过 MVCC 中 value 的事务 ID 与读事务的 snapshot 进行版本读取,与读事务本身的 ID 是没有关系。
在 WT 引擎中,开启事务时,引擎会将一个 WT_TNX_NONE(= 0) 的事务 ID 设置给开启的事务,当它第一次对事务进行写时,会在数据修改前通过全局事务管理器中的 current_id 来分配一个全局唯一的事务 ID。这个过程也是通过 CPU 的 CAS_ADD 原子操作完成的无锁过程。
一般事务是两个阶段:事务执行和事务提交。在事务执行前,我们需要先创建事务对象并开启它,然后才开始执行,如果执行遇到冲突和或者执行失败,我们需要回滚事务(rollback)。如果执行都正常完成,最后只需要提交(commit)它即可。
从上面的描述可以知道事务过程有:创建开启、执行、提交和回滚。从这几个过程中来分析 WT 是怎么实现这几个过程的。
WT 事务开启过程中,首先会为事务创建一个事务对象并把这个对象加入到全局事务管理器当中,然后通过事务配置信息确定事务的隔离级别和 redo log 的刷盘方式并将事务状态设为执行状态,最后判断如果隔离级别是 ISOLATION_SNAPSHOT(snapshot 级的隔离),在本次事务执行前创建一个系统并发事务的 snapshot。至于为什么要在事务执行前创建一个 snapshot,在后面 WT 事务隔离章节详细介绍。
事务在执行阶段,如果是读操作,不做任何记录,因为读操作不需要回滚和提交。如果是写操作,WT 会对每个写操作做详细的记录。在上面介绍的事务对象(wt_transaction)中有两个成员,一个是操作 operation_array,一个是 redo_log_buf。这两个成员是来记录修改操作的详细信息,在 operation_array 的数组单元中,包含了一个指向 MVCC list 对应修改版本值的指针。详细的更新操作流程如下:
示意图如下: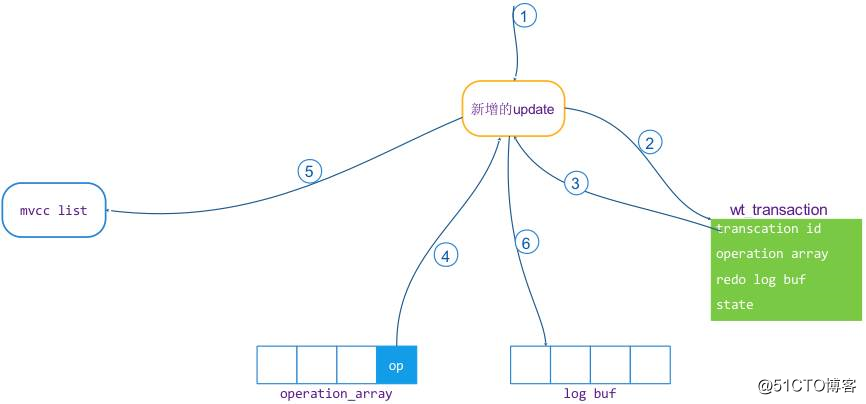
图4,点击图片可以全屏缩放
WT 引擎对事务的提交过程比较简单,先将要提交的事务对象中的 redo_log_buf 中的数据写入到 redo log file(重做日志文件)中,并将 redo log file 持久化到磁盘上。清除提交事务对象的 snapshot object,再将提交的事务对象中的 transaction_id 设置为 WT_TNX_NONE,保证其他事务在创建系统事务 snapshot 时本次事务的状态是已提交的状态。
WT 引擎对事务的回滚过程也比较简单,先遍历整个operation_array,对每个数组单元对应 update 的事务 id 设置以为一个 WT_TXN_ABORTED(= uint64_max),标示 MVCC 对应的修改单元值被回滚,在其他读事务进行 MVCC 读操作的时候,跳过这个放弃的值即可。整个过程是一个无锁操作,高效、简洁。
传统的数据库事务隔离分为:
WT 引擎并没有按照传统的事务隔离实现这四个等级,而是基于 snapshot 的特点实现了自己的 Read-Uncommited、Read-Commited 和一种叫做 snapshot-Isolation(快照隔离)的事务隔离方式。
在 WT 中不管是选用的是那种事务隔离方式,它都是基于系统中执行事务的快照来实现的。那来看看 WT 是怎么实现上面三种方式?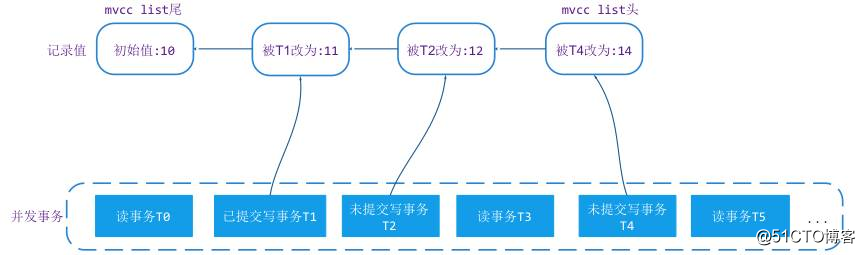
图5,点击图片可以全屏缩放
Read-Uncommited(未提交读)隔离方式的事务在读取数据时总是读取到系统中最新的修改,哪怕是这个修改事务还没有提交一样读取,这其实就是一种脏读。WT 引擎在实现这个隔方式时,就是将事务对象中的 snap_object.snap_array 置为空即可,在读取 MVCC list 中的版本值时,总是读取到 MVCC list 链表头上的第一个版本数据。
举例说明,在图 5 中,如果 T0/T3/T5 的事务隔离级别设置成 Read-uncommited 的话,T1/T3/T5 在 T5 时刻之后读取系统的值时,读取到的都是 14。一般数据库不会设置成这种隔离方式,它违反了事务的 ACID 特性。可能在一些注重性能且对脏读不敏感的场景会采用,例如网页 cache。
Read-Commited(提交读)隔离方式的事务在读取数据时总是读取到系统中最新提交的数据修改,这个修改事务一定是提交状态。这种隔离级别可能在一个长事务多次读取一个值的时候前后读到的值可能不一样,这就是经常提到的“幻象读”。在 WT 引擎实现 read-commited 隔离方式就是事务在执行每个操作前都对系统中的事务做一次快照,然后在这个快照上做读写。
还是来看图 5,T5 事务在 T4 事务提交之前它进行读取前做事务
snapshot={
snap_min=T2,
snap_max=T4,
snap_array={T2,T4},
};
在读取 MVCC list 时,12 和 14 修改对应的事务 T2/T4 都出现在 snap_array 中,只能再向前读取 11,11 是 T1 的修改,而且 T1 没有出现在 snap_array,说明 T1 已经提交,那么就返回 11 这个值给 T5。
之后事务 T2 提交,T5 在它提交之后再次读取这个值,会再做一次
snapshot={
snap_min=T4,
snap_max=T4,
snap_array={T4},
},
这时在读取 MVCC list 中的版本时,就会读取到最新的提交修改 12。
Snapshot-Isolation(快照隔离)隔离方式是读事务开始时看到的最后提交的值版本修改,这个值在整个读事务执行过程只会看到这个版本,不管这个值在这个读事务执行过程被其他事务修改了几次,这种隔离方式不会出现“幻象读”。WT 在实现这个隔离方式很简单,在事务开始时对系统中正在执行的事务做一个 snapshot,这个 snapshot 一直沿用到事务提交或者回滚。还是来看图 5, T5 事务在开始时,对系统中的执行的写事务做
snapshot={
snap_min=T2,
snap_max=T4,
snap_array={T2,T4}
},
在他读取值时读取到的是 11。即使是 T2 完成了提交,但 T5 的 snapshot 执行过程不会更新,T5 读取到的依然是 11。
这种隔离方式的写比较特殊,就是如果有对事务看不见的数据修改,事务尝试修改这个数据时会失败回滚,这样做的目的是防止忽略不可见的数据修改。
通过上面对三种事务隔离方式的分析,WT 并没有使用传统的事务独占锁和共享访问锁来保证事务隔离,而是通过对系统中写事务的 snapshot 来实现。这样做的目的是在保证事务隔离的情况下又能提高系统事务并发的能力。
通过上面的分析可以知道 WT 在事务的修改都是在内存中完成的,事务提交时也不会将修改的 MVCC list 当中的数据刷入磁盘,WT 是怎么保证事务提交的结果永久保存呢?
WT 引擎在保证事务的持久可靠问题上是通过 redo log(重做操作日志)的方式来实现的,在本文的事务执行和事务提交阶段都有提到写操作日志。WT 的操作日志是一种基于 K/V 操作的逻辑日志,它的日志不是基于 btree page 的物理日志。说的通俗点就是将修改数据的动作记录下来,例如:插入一个 key = 10, value = 20 的动作记录在成:
{
Operation = insert,(动作)
Key = 10,
Value = 20
};
将动作记录的数据以 append 追加的方式写入到 wt_transaction 对象中 redo_log_buf 中,等到事务提交时将这个 redo_log_buf 中的数据已同步写入的方式写入到 WT 的重做日志的磁盘文件中。如果数据库程序发生异常或者崩溃,可以通过上一个 checkpoint(检查点)位置重演磁盘上这个磁盘文件来恢复已经提交的事务来保证事务的持久性。
根据上面的描述,有几个问题需要搞清楚:
1、操作日志格式怎么设计?
2、在事务并发提交时,各个事务的日志是怎么写入磁盘的?
3、日志是怎么重演的?它和 checkpoint 的关系是怎样的?
在分析这三个问题前先来看 WT 是怎么管理重做日志文件的,在 WT 引擎中定义一个叫做 LSN 序号结构,操作日志对象是通过 LSN 来确定存储的位置的,LSN 就是 Log Sequence Number(日志序列号),它在 WT 的定义是文件序号加文件偏移,
wt_lsn{
file: 文件序号,指定是在哪个日志文件中
offset: 文件内偏移位置,指定日志对象文件内的存储文开始位置
}
WT 就是通过这个 LSN 来管理重做日志文件的。
WT 引擎的操作日志对象(以下简称为 logrec)对应的是提交的事务,事务的每个操作被记录成一个 logop 对象,一个 logrec 包含多个 logop,logrec 是一个通过精密序列化事务操作动作和参数得到的一个二进制 buffer,这个 buffer的数据是通过事务和操作类型来确定其格式的。
WT 中的日志分为 4 类,分别是:
这里介绍和执行事务密切先关的 LOGREC_COMMIT,这类日志里面由根据 K/V 的操作方式分为:
这几种操作都会记录操作时的 key,根据操作方式填写不同的其他参数,例如:update 更新操作,就需要将 value 填上。除此之外,日志对象还会携带 btree 的索引文件 ID、提交事务的 ID 等,整个 logrec 和 logop 的关系结构图如下:
图6,点击图片可以全屏缩放
对于上图中的 logrec header 中的为什么会出现两个长度字段:logrec 磁盘上的空间长度和在内存中的长度,因为 logrec 在刷入磁盘之前会进行空间压缩,磁盘上的长度和内存中的长度就不一样。压缩是根据系统配置可选的。
WT 引擎在采用 WAL(Write-Ahead Log)方式写入日志,WAL 通俗点说就是说在事务所有修改提交前需要将其对应的操作日志写入磁盘文件。在事务执行的介绍小节中我们介绍是在什么时候写日志的,这里我们来分析事务日志是怎么写入到磁盘上的,整个写入过程大致分为下面几个阶段:
1、事务在执行第一个写操作时,先会在事务对象(wt_transaction)中的 redo_log_buf 的缓冲区上创建一个 logrec 对象,并将 logrec 中的事务类型设置成 LOGREC_COMMIT。
2、然后在事务执行的每个写操作前生成一个 logop 对象,并加入到事务对应的 logrec 中。
3、在事务提交时,把 logrec 对应的内容整体写入到一个全局 log 对象的 slot buffer 中并等待写完成信号。
4、Slot buffer 会根据并发情况合并同时发生的提交事务的 logrec,然后将合并的日志内容同步刷入磁盘(sync file),最后告诉这个 slot buffer 对应所有的事务提交刷盘完成。
5、提交事务的日志完成,事务的执行结果也完成了持久化。
整个过程的示意图如下:
图7,点击图片可以全屏缩放
WT 为了减少日志刷盘造成写 IO,对日志刷盘操作做了大量的优化,实现一种类似 MySQL 组提交的刷盘方式。
这种刷盘方式会将同时发生提交的事务日志合并到一个 slot buffer 中,先完成合并的事务线程会同步等待一个完成刷盘信号,最后完成日志数据合并的事务线程将 slot buffer 中的所有日志数据 sync 到磁盘上并通知在这个 slot buffer 中等待其他事务线程刷盘完成。
并发事务的 logrec 合并到 slot buffer 中的过程是一个完全无锁的过程,这减少了必要的 CPU 竞争和操作系统上下文切换。为了这个无锁设计 WT 在全局的 log 管理中定义了一个 acitve_ready_slot 和一个 slot_pool 数组结构,大致如下定义:
wt_log{
. . .
active_slot:准备就绪且可以作为合并logrec的slot buffer对象
slot_pool:系统所有slot buffer对象数组,包括:正在合并的、准备合并和闲置的slot buffer。
}
slot buffer 对象是一个动态二进制数组,可以根据需要进行扩大。定义如下:
wt_log_slot{
. . .
state: 当前 slot 的状态,ready/done/written/free 这几个状态
buf: 缓存合并 logrec 的临时缓冲区
group_size: 需要提交的数据长度
slot_start_offset: 合并的logrec存入log file中的偏移位置
. . .
}
通过一个例子来说明这个无锁过程,假如在系统中 slot_pool 中的 slot 个数为16,设置的 slot buffer 大小为 4KB,当前 log 管理器中的 active_slot 的 slot_start_offset=0,有 4 个事务(T1、T2、T3、T4)同时发生提交,他们对应的日志对象分别是 logrec1、logrec2、logrec3 和 logrec4。
Logrec1 size = 1KB, logrec2 szie = 2KB, logrec3 size = 2KB, logrec4 size = 5KB。他们合并和写入的过程如下:
1、T1事 务在提交时,先会从全局的 log 对象中的 active_slot 发起一次 JOIN 操作,join 过程就是向 active_slot 申请自己的合并位置和空间,logrec1_size + slot_start_offset < slot_size 并且 slot 处于 ready 状态,那 T1 事务的合并位置就是 active_slot[0, 1KB],slot_group_size = 1KB
2、这是 T2 同时发生提交也要合并 logrec,也重复第 1 部 JOIN 操作,它申请到的位置就是 active_slot [1KB, 3KB], slot_group_size = 3KB。
3、在T1事务 JOIN 完成后,它会判断自己是第一个 JOIN 这个 active_slot 的事务,判断条件就是返回的写入位置 slot_offset=0。如果是第一个它立即会将 active_slot 的状态从 ready 状态置为 done 状态,并未后续的事务从 slot_pool 中获取一个空闲的 active_slot_new 来顶替自己合并数据的工作。
4、与此同时 T2 事务 JOIN 完成之后,它也是进行这个过程的判断,T2 发现自己不是第一个,它将会等待 T1 将 active_slot 置为 done.
5、T1 和 T2 都获取到了自己在 active_slot 中的写入位置,active_slot 的状态置为 done 时,T1 和 T2 分别将自己的 logrec 写入到对应 buffer 位置。假如在这里 T1 比 T2 先将数据写入完成,T1 就会等待一个 slot_buffer 完全刷入磁盘的信号,而 T2 写入完成后会将 slot_buffer 中的数据写入 log 文件,并对 log 文件做 sync 刷入磁盘的操作,最高发送信号告诉 T1 同步刷盘完成,T1 和 T2 各自返回,事务提交过程的日志刷盘操作完成。
那这里有几种其他的情况,假如在第 2 步运行的完成后,T3 也进行 JOIN 操作,这个时候 slot_size(4KB) < slot_group_size(3KB)+ logrec_size(2KB),T3 不 JOIN 当时的 active_slot,而是自旋等待 active_slot_new 顶替 active_slot 后再 JOIN 到 active_slot_new。
如果在第 2 步时,T4 也提交,因为 logrec4(5KB) > slot_size(4KB),T4 就不会进行 JOIN 操作,而是直接将自己的 logrec 数据写入 log 文件,并做 sync 刷盘返回。在返回前因为发现有 logrec4 大小的日志数据无法合并,全局 log 对象会试图将 slot buffer 的大小放大两倍,这样做的目的是尽量让下面的事务提交日志能进行 slot 合并写。
WT 引擎之所以引入 slot 日志合并写的原因就是为了减少磁盘的 I/O 访问,通过无锁的操作,减少全局日志缓冲区的竞争。
从上面关于事务日志和 MVCC list 相关描述我们知道,事务的 redo log 主要是防止内存中已经提交的事务修改丢失,但如果所有的修改都存在内存中,随着时间和写入的数据越来越多,内存就会不够用,这个时候就需要将内存中的修改数据写入到磁盘上。
一般在 WT 中是将整个 BTREE 上的 page 做一次 checkpoint 并写入磁盘。WT 中的 checkpoint 是 append 方式管理,也就是说 WT 会保存多个 checkpoint 版本。不管从哪个版本的 checkpoint 开始都可以通过重演 redo log 来恢复内存中已提交的事务修改。整个重演过程就是就是简单的对 logrec 中各个操作的执行。
这里值得提一下的是因为 WT 保存多个版本的 checkpoint,那么它会将 checkpoint 做为一种元数据写入到元数据表中,元数据表也会有自己的 checkpoint 和 redo log,但是保存元数据表的 checkpoint 是保存在 WiredTiger.wt 文件中,系统重演普通表的提交事务之前,先会重演元数据事务提交修改。后文会单独用一个篇幅来说明 btree、checkpoint 和元数据表的关系和实现。
WT 的 redo log 是通过配置开启或者关闭的,MongoDB 并没有使用 WT 的 redo log 来保证事务修改不丢,而是采用了 WT 的 checkpoint 和 MongoDB 复制集的功能结合来保证数据的完整性。
大致的细节是如果某个 MongoDB 实例宕机了,重启后通过 MongoDB 的复制协议将自己最新 checkpoint 后面的修改从其他的 MongoDB 实例复制过来。
虽然 WT 实现了多操作事务模型,然而 MongoDB 并没有提供事务,这或许和 MongoDB 本身的架构和产品定位有关系。但是 MongoDB 利用了 WT 的短事务的隔离性实现了文档级行锁,对 MongoDB 来说这是大大的进步。
可以说 WT 在事务的实现上另辟蹊径,整个事务系统的实现没有用繁杂的事务锁,而是使用 snapshot 和 MVCC 这两个技术轻松的而实现了事务的 ACID,这种实现也大大提高了事务执行的并发性。
除此之外,WT 在各个事务模块的实现多采用无锁并发,充分利用 CPU 的多核能力来减少资源竞争和 I/O 操作,可以说 WT 在实现上是有很大创新的。通过对 WiredTiger 的源码分析和测试,也让我获益良多,不仅仅了解了数据库存储引擎的最新技术,也对 CPU 和内存相关的并发编程有了新的理解,很多的设计模式和并发程序架构可以直接借鉴到现实中的项目和产品中。
后续的工作是继续对 Wiredtiger 做更深入的分析、研究和测试,并把这些工作的心得体会分享出来,让更多的工程师和开发者了解这个优秀的存储引擎。(小编:请留意高可用架构后续 WiredTiger 文章)

MongoDB 2015回顾:全新里程碑式的WiredTiger存储引擎
对 WiredTiger 及 MongoDB 新版设计及使用感兴趣的同学,欢迎在本文留言,介绍对 WiredTiger/MongoDB 的使用及了解,我们将邀请评论中有意向的同学与本文作者及业内相关专家在 『高可用架构—WiredTiger/MongoDB』 微信群进行交流。
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。

长按二维码 关注「高可用架构」公众号
解密未来数据库设计:MongoDB新存储引擎WiredTiger实现(事务篇)
标签:概念 流程 snapshot 新技术 微信群 等级 格式 seq 上下文
原文地址:https://blog.51cto.com/14977574/2547548