标签:表格 标识符 ica 命令 姓名 web asp usr options
Web抓取的使用正在积极增加,特别是在大型电子商务公司中,Web抓取是一种收集数据以竞争,分析竞争对手和研究新产品的方式。Web抓取是一种从网站提取信息的方法。在本篇文章中,学习如何创建基于Python的刮板。深入研究代码,看看它是如何工作的。
在当今的大数据世界中,很难跟踪正在发生的一切。对于需要大量信息才能取得成功的企业来说,情况变得更加复杂。但是首先,他们需要以某种方式收集此数据,这意味着他们必须处理数千个资源。
有两种收集数据的方法。您可以使用API媒体网站提供的服务,这是获取所有新闻的最佳方法。而且,API非常易于使用。不幸的是,并非每个网站都提供此服务。然后剩下第二种方法-网页抓取。
这是一种从网站提取信息的方法。HTML页面不过是嵌套标记的集合。标签形成某种树,其根在<html>标签中,并将页面分成不同的逻辑部分。每个标签可以有其自己的后代(子级)和父级。
例如,HTML页面树可以如下所示:
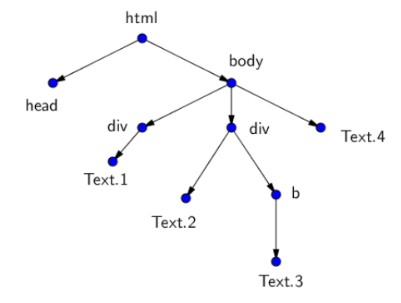
要处理此HTML,您可以使用文本或树。绕过这棵树是网页抓取。我们只会在所有这些多样性中找到我们需要的节点,并从中获取信息!这种方法主要集中在将非结构化的HTML数据转换成易于使用的结构化信息到数据库或工作表中。数据抓取需要一个机器人来收集信息,并通过HTTP或Web浏览器连接到Internet。在本指南中,我们将使用Python创建刮板。
我们需要做什么:
获取我们要从中抓取数据的页面的URL
复制或下载此页面的HTML内容
此序列使我们可以弹出所需的URL,获取HTML数据,然后对其进行处理以接收所需的数据。但是有时我们需要先进入网站,然后再转到特定的网址以接收数据。然后,我们必须再增加一个步骤-登录该网站。
我们将使用Beautiful Soup库来分析HTML内容并获取所有必需的数据。这是抓取HTML和XML文档的绝佳Python包。
Selenium库将帮助我们在一个会话中使抓取器进入网站并转到所需的URL地址。Selenium Python 可以帮助您执行诸如单击按钮,输入内容等操作。
首先,让我们导入将要使用的库。
# 导入库
from selenium import webdriver
from bs4 import BeautifulSoup然后,我们需要向浏览器的驱动程序展示Selenium启动网络浏览器的方式(我们将在这里使用Google Chrome)。如果我们不希望机器人显示Web浏览器的图形界面,则将在Selenium中添加“ headless”选项。
没有图形界面(无头)的Web浏览器可以在与所有流行的Web浏览器非常相似的环境中自动管理网页。但是在这种情况下,所有活动都通过命令行界面或使用网络通信进行。
# chrome驱动程序的路径
chromedriver = ‘/usr/local/bin/chromedriver‘
options = webdriver.ChromeOptions()
options.add_argument(‘headless‘) #open a headless browser
browser = webdriver.Chrome(executable_path=chromedriver,
chrome_options=options)设置浏览器,安装库并创建环境之后,我们便开始使用HTML。让我们进入输入页面,找到用户必须在其中输入电子邮件地址和密码的标识符,类别或字段名称。
# 进入登录页面
browser.get(‘http://playsports365.com/default.aspx‘)
# 按姓名搜索标签
email =
browser.find_element_by_name(‘ctl00$MainContent$ctlLogin$_UserName‘)
password =
browser.find_element_by_name(‘ctl00$MainContent$ctlLogin$_Password‘)
login =
browser.find_element_by_name(‘ctl00$MainContent$ctlLogin$BtnSubmit‘)然后,我们会将登录数据发送到这些HTML标签中。为此,我们需要按下操作按钮以将数据发送到服务器。
# 添加登录凭证
email.send_keys(‘********‘)
password.send_keys(‘*******‘)
# 点击提交按钮
login.click()
email.send_keys(‘********‘)
password.send_keys(‘*******‘)
login.click()成功进入系统后,我们将转到所需的页面并收集HTML内容。
# 成功登录后,转到“ OpenBets”页面
browser.get(‘http://playsports365.com/wager/OpenBets.aspx‘)
# 获取HTML内容
requiredHtml = browser.page_source现在,当我们有了HTML内容时,剩下的唯一事情就是处理这些数据。我们将在Beautiful Soup和html5lib库的帮助下做到这一点。
html5lib是一个Python软件包,实现了受现代Web浏览器影响的HTML5抓取算法。一旦获得了内容的标准化结构,就可以在HTML标记的任何子元素中搜索数据。我们正在寻找的信息在表格标签中,因此我们正在寻找它。
soup = BeautifulSoup(requiredHtml, ‘html5lib‘)
table = soup.findChildren(‘table‘)
my_table = table[0]我们将找到父标记一次,然后递归地遍历子标记并打印出值。
# 接收标签和打印值
rows = my_table.findChildren([‘th‘, ‘tr‘])
for row in rows:
cells = row.findChildren(‘td‘)
for cell in cells:
value = cell.text
print (value)要执行此程序,您将需要使用pip安装Selenium,Beautiful Soup和html5lib。安装库之后,命令如下:
# python <程序名称>将把这些值打印到控制台中,这就是您抓取任何网站的方式。
如果我们抓取经常更新内容的网站(例如,运动成绩表),则应创建cron任务以在特定时间间隔启动该程序。
非常好,一切正常,内容被抓取,数据被填充,除了这之外,其他一切都很好,这就是我们要获取数据的请求数。

有时,服务器会厌倦同一个人发出一堆请求,而服务器禁止它。不幸的是,人们的耐心有限。
在这种情况下,您必须掩饰自己。禁止的最常见原因是403错误,以及在IP被阻止时向服务器发送的频繁请求。服务器可用并能够处理请求时,服务器会抛出403错误,但出于某些个人原因,拒绝这样做。第一个问题已经解决了–我们可以通过使用html5lib生成伪造的用户代理来伪装成人类,并将操作系统,规范和浏览器的随机组合传递给我们的请求。在大多数情况下,这样可以很好地准确地收集您感兴趣的信息。
但是有时仅将time.sleep()放在正确的位置并填写请求标头是不够的。因此,您需要寻找功能强大的方法来更改此IP。要抓取大量数据,您可以:
– 开发自己的IP地址基础架构;
– 使用Tor –该主题可以专门讨论几篇大型文章,而实际上已经完成了;
– 使用商业代理网络;
对于网络抓取的初学者来说,最好的选择是与代理提供商联系,例如Infatica等,他们可以帮助您设置代理并解决代理服务器管理中的所有困难。收集大量数据需要大量资源,因此无需通过开发自己的内部基础结构来进行代理来“重新发明轮子”。甚至许多最大的电子商务公司都使用代理网络服务将代理管理外包,因为大多数公司的第一要务是数据,而不是代理管理。
标签:表格 标识符 ica 命令 姓名 web asp usr options
原文地址:https://blog.51cto.com/mageedu/2541099