标签:并且 过滤 exists max var tree insert 列表 desc

CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT(10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL,
`views` INT(10) UNSIGNED NOT NULL,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
INSERT INTO `article` (`author_id`,`category_id`,`views`,`comments`,`title`,`content`) VALUES(1, 1, 1, 1, ‘1‘, ‘1‘),
(2, 2, 2, 2, ‘2‘, ‘2‘),
(1, 1, 3, 3, ‘3‘, ‘3‘);
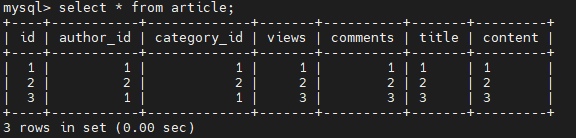
select * from article;
查询 category_id 为 1,且 comments 大于 1的情况下, views 最多的 article_id。
SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
show index from article;
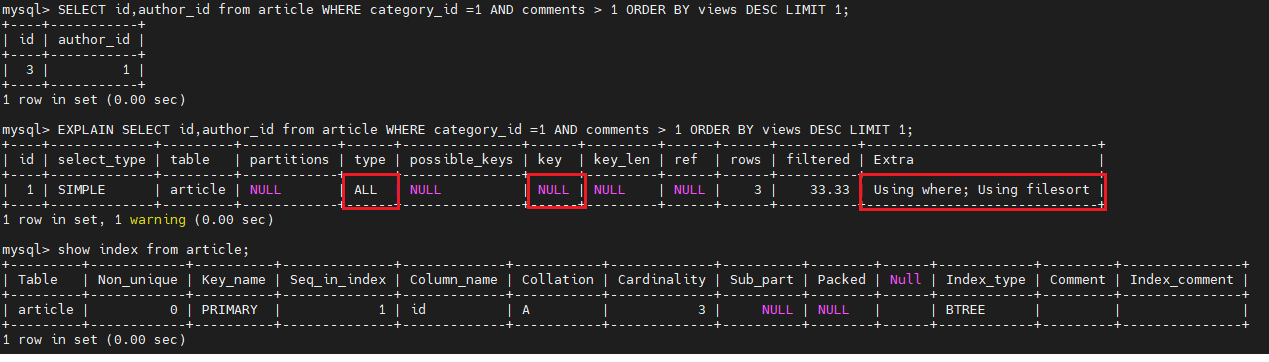
type 是 ALL,即最坏的情况。Extra中还出现了Using filesort,也是最坏的情况。优化是必须的。
# 新建索引
create index idx_article_ccv on article(category_id,comments,views);
# 或者
# ALTER TABLE ‘article‘ ADD INDEX idx_article_ccv (`category_id`,`comments`,`view`);
show index from article;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments = 1 ORDER BY views DESC LIMIT 1;
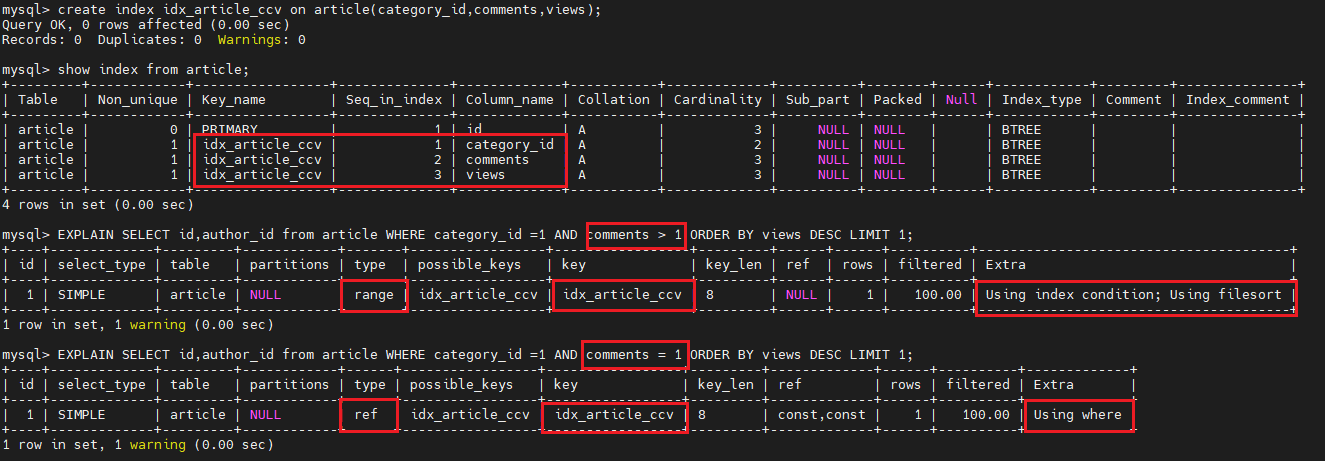
type 变成了 range,这是可以接受的。但是 extra 里使用 using filesort 还是无法接受的。
我们已经建立了索引,为什么没用呢?
按照 BTree 树索引的工作原理,先排序 category_id,再排序 comments,如果遇到相同的 comments 再排序 views。当 comments 子段在联合索引中处于中间位置时,因为 comments>1 条件是一个范围值(range),Mysql无法利用索引再对后面的 views 部分进行检索,即 range 类型查询字段后面的索引无效。
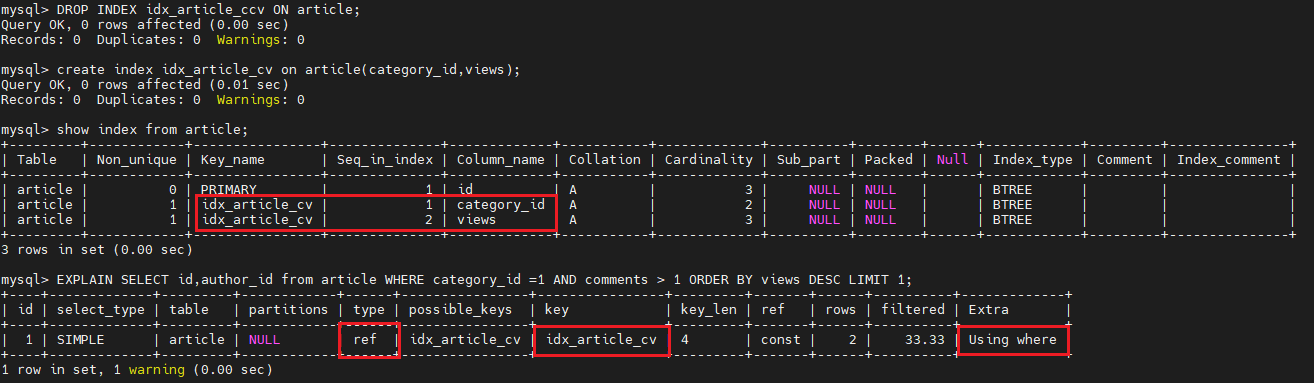
DROP INDEX idx_article_ccv ON article;
create index idx_article_cv on article(category_id,views);
show index from article;
EXPLAIN SELECT id,author_id from article WHERE category_id =1 AND comments > 1 ORDER BY views DESC LIMIT 1;
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
INSERT INTO class (card) VALUES(FLOOR(1+(RAND()*20)));
... #20 条 RAND() 随机数
INSERT INTO class (card) VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book (card) VALUES(FLOOR(1+(RAND()*20)));
... #20 条
INSERT INTO book (card) VALUES(FLOOR(1+(RAND()*20)));
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

type为 ALL,需要优化。
ALTER TABLE `book` ADD INDEX Y (`card`);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

DROP INDEX Y ON book;
ALTER TABLE `class` ADD INDEX Y (`card`);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

第一次优化中 type 变为 ref,rows 变成了 2,优化比较明显。但是第二轮优化中并没有提升。
这是由左连接特性决定了, LEFT JOIN 条件用于确定如何从右表搜索行,左表一定都有。所以右表建索引才有效。
同理,右连接一样。RIGHT JOIN 条件用于确定如何从左表搜索行,右表一定都有。所以左表建索引才有效。
CREATE TABLE IF NOT EXISTS `phone`(
`phoneid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`phoneid`)
);
INSERT INTO phone (card) VALUES(FLOOR(1+(RAND()*20)));
... #20 条 RAND() 随机数
INSERT INTO phone (card) VALUES(FLOOR(1+(RAND()*20)));
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone on book.card = phone.card;

ALTER TABLE `book` ADD INDEX Y (`card`);
ALTER TABLE `phone` ADD INDEX Z (`card`);
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone on book.card = phone.card;

后两行的type 都是 ref,并且 rows 优化效果也很好。因此索引最好设置在需要经常查询的字段中。
select * from A where id in (select id from B)
等价于
for select id from B
for select * from A where A.id=B.id
当 B 表的数据集小于 A 表的数据集时,用 in 优于 exists
select * from A where exists (select id from B where B.id = A.id)
等价于
for select * from A
for select * from B where A.id=B.id
当 A 表的数据集小于 B 表的数据集时,用 exists 优于 in
CREATE TABLE tblA(
age INT,
birth TIMESTAMP NOT NULL
);
INSERT INTO tblA(age,birth) VALUES(22,NOW());
INSERT INTO tblA(age,birth) VALUES(22,NOW());
INSERT INTO tblA(age,birth) VALUES(22,NOW());
CREATE INDEX idx_A_ageBirth on tblA(age,birth);
SELECT * FROM tblA;
EXPLAIN SELECT * FROM tblA WHERE age>20 order by age;
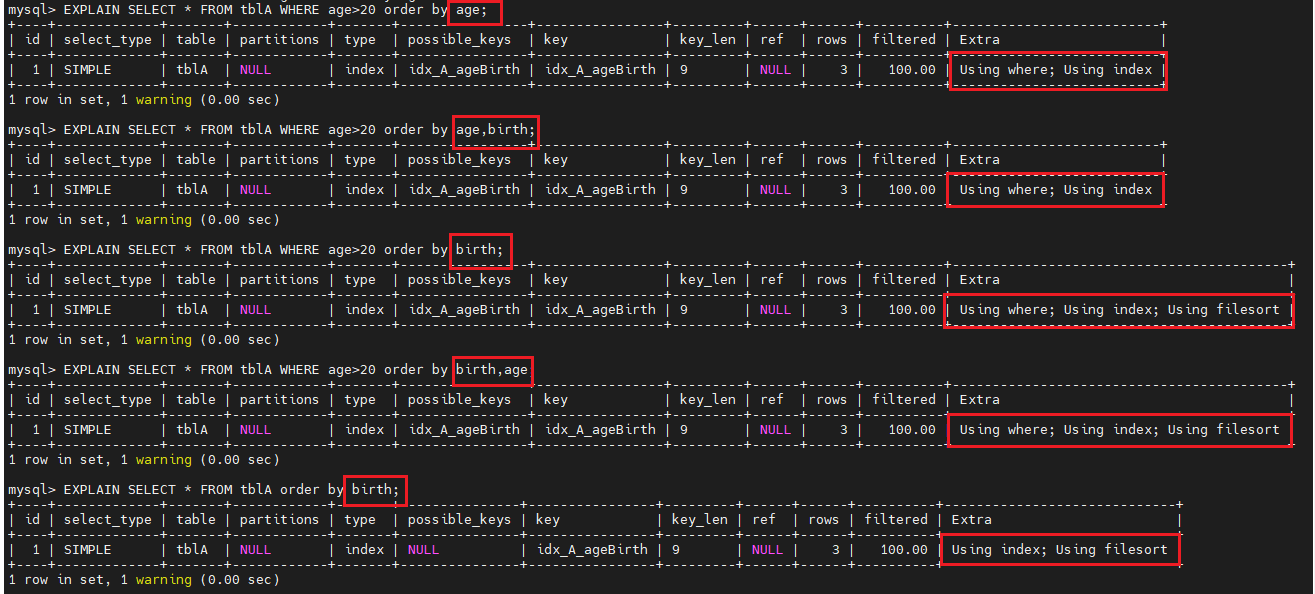
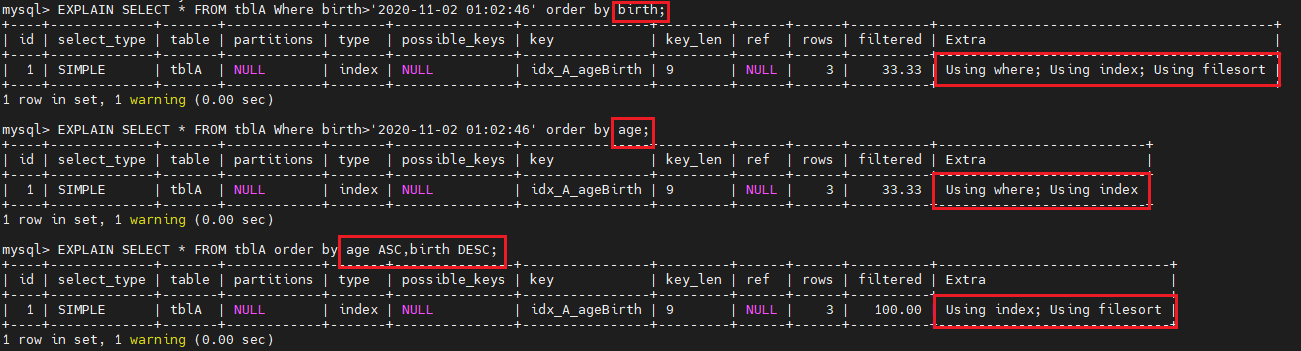
SQL 支持两种方式的排序,FileSort 和 Index,Index 效率高。
ORDER BY 满足两种情况会使用 Index 排序:
所以尽可能在索引列上完成排序,遵照索引的最佳左前缀。
如果不在索引列上,filesort 有两种算法:
优化策略:
当查询字段大小总和小于max_length_for_sort_data而且排序字段不是 TEXT | BLOB 类型时,会使用单路排序,否则使用双路排序。
标签:并且 过滤 exists max var tree insert 列表 desc
原文地址:https://www.cnblogs.com/zzu-general/p/13968139.html