标签:enc 存在 访问 销售额 关系 不用 http 编程错误 特殊







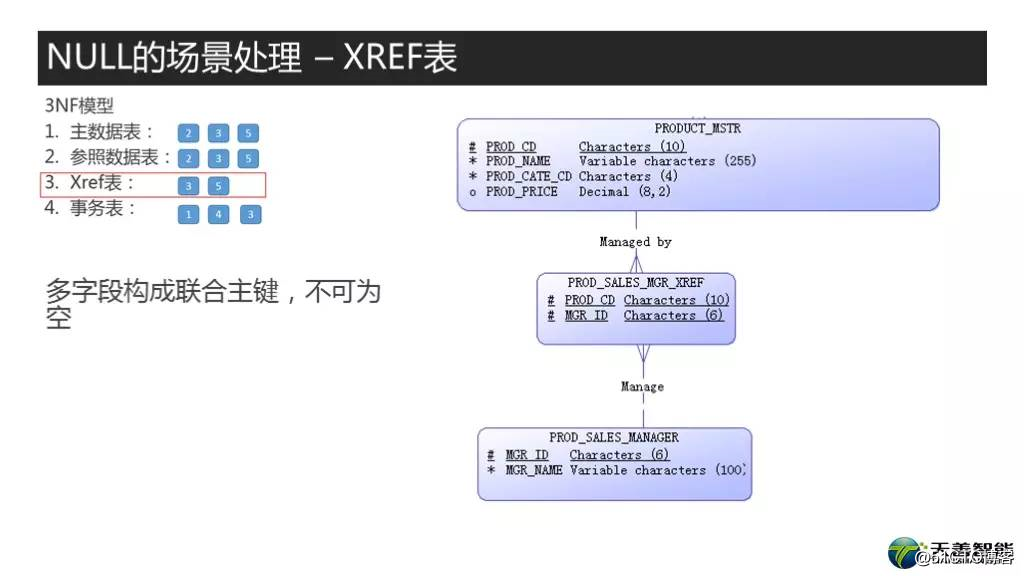
下面的这个场景就很简单了,这里是三张表,一张PROD MASTER表,还有下面这个新加的产品销售经理表,但因为产品表和销售经理表是多对多的关系,因此建一个XREF表,这张表主要用于表之间的JOIN。这张表是PROD_CD以及MANAGER_ID从逻辑上来讲是作为联合主键的,因此显然不可为空。因为在数据仓库设计中,有很多人不喜欢给这种表建主键,因此我这里单独说明一下。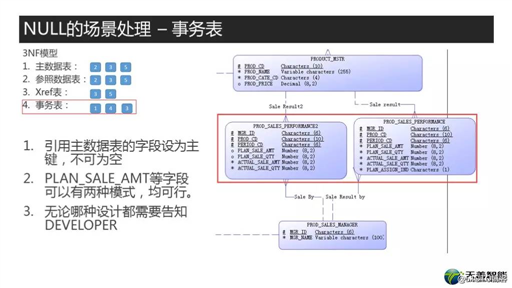
下一个场景,事务表。这张表很简单,就是销售经理在某月的销售情况与销售计划的对比表。
首先我们看表中的字段,前三个是联合主键,因此显然必须不可为空。然后看PLAN_SALE_AMT, ACTUAL_SALE_AMT以及Quantity。我们按照步骤来,首先看需求,需求就是每个产品的销售经理会有销售配额,也就是PLAN_SALE_AMT,然后还有一个实际的销售情况,就是ACTUAL_SALE_AMT。很显然,需要经常去求完成比以及计划与实际的差额,因此这几个字段就需要经常做数学计算。然后还有这种需求,就是求每个经理的平均每个月的销售配额以及实际销售情况,也就是说还会用到聚合函数。这里我说的需求是非常重要的,就是还有一些特殊的场景我们要考虑到,就是有可能某个经理,其中某个产品他没有配额,但他也销售出去了,这样这个经理会有实际销售额,但没有对应的配额。这个时候呢,如果遵从数据的本质,那么就给PLAN_SALE_AMT置为NULL。也就是按照表PROD_SALES_PERFORMANCE2来设计,但如果担心NULL带来的数据计算的隐患,也就是说计划为NULL减去实际,而实际销售额是有值的,出现NULL的现象。也可以设计成右边的表的模式PROD_SALES_PERFORMANCE,这些项目均不可为空,然后增加一个PLAN_ASSIGN_IND用于标识,是不是这个经理有配额。但无论这两种那种情况,都需要告诉开发者,编程时需要注意的地方。这也是我前面提到的设计一致性的重要性,你有一个地方这么设计的,给开发者讲明白了,后面类似的设计他们就很容易理解了。
那么,有关NULL值的相关设计呢,我们就先讲到这,这个话题很大,应该还有很多场景没有覆盖到,并且星型表的NULL值设定我也没有讲。未来在讲维度建模的时候,还会提到。下节课我会讲第三范式的概念,我看了一下天善的课程,其实有人已经讲过了,不过实在对不起,我希望我的课程能够比较完整,因此还是会把这部分按我自己的理解重新讲一遍。谢谢大家!
延伸阅读:
高质量数据库建模系列课程<10> PPT & 讲义 -- NULL之别传
标签:enc 存在 访问 销售额 关系 不用 http 编程错误 特殊
原文地址:https://blog.51cto.com/15009253/2552764