标签:abs 自己的 sanic name 选择 根据 fast package 阻塞
你是否听到人们说过,异步 Python 代码比“普通(或同步)Python 代码更快?果真是那样吗?
Web 应用程序通常要处理许多请求,这些请求在很短的时间段内来自不同的客户端。为避免处理延迟,必须考虑并行处理多个请求,这通常称为“并发”。
在本文中,我将继续使用 Web 应用程序作为例子,但是要记住还有其它类型的应用程序也从并发完成多个任务中获益,因此这个讨论并不仅仅是针对 Web 应用程序的。
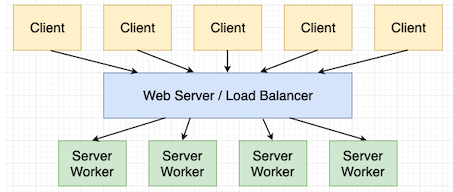
术语“同步”和“异步”指的是编写并发应用程序的两种方式。所谓的“同步”服务器使用底层操作系统支持的线程和进程来实现这种并发性。下面是同步部署的一个示意图:
![]() ?
?
在这种情况下,我们有 5 台客户端,都向应用程序发送请求。这个应用程序的访问入口是一个 Web 服务器,通过将服务分配给一个服务器 worker 池来充当负载均衡器,这些 worker 可以实现为进程、线程或者两者的结合。这些 worker 执行负载均衡器分配给他们的请求。你使用 Web 应用程序框架(例如 Flask 或 Django)编写的应用程序逻辑运行在这些 worker 中。
这种类型的方案对于有多个 CPU 的服务器比较好,因为你可以将 worker 的数量设置为 CPU 的数量,这样你就能均衡地利用你的处理器核心,而单个 Python 进程由于全局解释器锁(GIL)的限制无法实现这一点。
在缺点方面,上面的示意图也清楚展示了这种方案的主要局限。我们有 5 个客户端,却只有 4 个 worker。如果这 5 个客户端在同一时间都发送请求,那么负载均衡器会将某一个客户端之外的所有请求发送到 worker 池,而剩下的请求不得不保留在一个队列中,等待有 worker 变得可用。因此,五分之四的请求会立即响应,而剩下的五分之一需要等一会儿。服务器优化的一个关键就在于选择适当数量的 worker 来防止或最小化给定预期负载的请求阻塞。
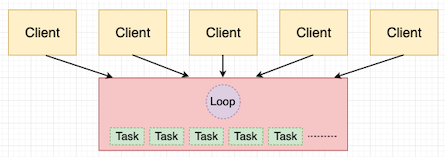
一个异步服务器的配置很难画,但是我会尽力而为:
![]() ?
?
这种类型的服务器运行在单个进程中,通过循环控制。这个循环是一个非常有效率的任务管理器和调度器,创建任务来执行由客户端发送的请求。与长期存在的服务器 worker 不同,异步任务是由循环创建,用来处理某个特定的请求,当那个请求完成时,该任务也会被销毁。任何时候,一台异步服务器都会有上百或上千个活跃的任务,它们都在循环的管理下执行自己的工作。
你可能想知道异步任务之间的并行是如何实现的。这就是有趣的部分,因为一个异步应用程序通过唯一的协同多任务处理来实现这点。这意味着什么?当一个任务需要等待一个外部事件(例如,一个数据库服务器的响应)时,不会像一个同步的 worker 那样等待,而是会告诉循环它需要等待什么,然后将控制权返回给它。循环就能够在这个任务被数据库阻塞的时候发现另外一个准备就绪的任务。最终,数据库将发送一个响应,而那时循环会认为第一个的任务已经准备好再次运行,并将尽快恢复它。
异步任务暂停和恢复执行的这种能力可能在抽象上很难理解。为了帮助你应用到你已经知道的东西,可以考虑在 Python 中使用await或yield关键字这一方法来实现,但你之后会发现这并不是唯一实现异步任务的方法。
一个异步应用程序完全运行在单个进程或线程中,这可以说是令人吃惊的。当然,这种类型的并发需要遵循一些规则,因此你不能让一个任务占用 CPU 太长时间,否则,剩余的任务会被阻塞。为了异步执行,所有的任务需要定时主动暂停并将控制权返还给循环。为了从异步方式获益,一个应用程序需要有经常被 I/O 阻塞的任务,并且没有太多 CPU 工作。Web 应用程序通常非常适合,特别是当它们需要处理大量客户端请求时。
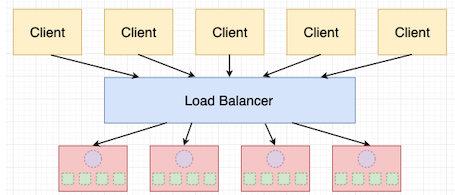
在使用一个异步服务器时,为了最大化多 CPU 的利用率,通常需要创建一个混合方案,增加一个负载均衡器并在每个 CPU 上运行一个异步服务器,如下图所示:
![]() ?
?
我敢肯定,你知道要在 Python 中写一个异步应用程序,你可以使用 asyncio package,这个包是在协程的基础上实现了所有异步应用程序都需要的暂停和恢复特性。其中yield关键字,以及更新的async和await都是asyncio构建异步能力的基础。
Python 生态系统中还有其它基于协程的异步方案,例如 Trio 和 Curio。还有 Twisted,它是所有协程框架中最古老的,甚至出现得比asyncio都要早。
如果你对编写异步 Web 应用程序感兴趣,有许多基于协程的异步框架可以选择,包括 aiohttp、sanic、FastAPI 和 Tornado。
很多人不知道的是,协程只是 Python 中编写异步代码的两种方法之一。第二种方法是基于一个叫做 greenlet 的库,你可以用 pip 安装它。Greenlets 和协程类似,它们也允许一个 Python 函数暂停执行并稍后恢复,但是它们实现这点的方式完全不同,这意味着 Python 中的异步生态系统分成两大类。
协程与 greenlets 之间针对异步开发最有意思的区别是,前者需要 Python 语言特定的关键字和特性才能工作,而后者并不需要。我的意思是,基于协程的应用程序需要使用一种特定的语法来书写,而基于 greenlet 的应用程序看起来几乎和普通 Python 代码一样。这非常酷,因为在某些情况下,这让同步代码可以被异步执行,这是诸如asyncio之类的基于协程的方案做不到的。
那么在 greenlet 方面,跟asyncio对等的库有哪些?我知道 3 个基于 greenlet 的异步包:Gevent、Eventlet 和 Meinheld,尽管最后一个更像是一个 Web 服务器而不是一个通用的异步库。它们都有自己的异步循环实现,而且它们都提供了一个有趣的“monkey-patching”功能,取代了 Python 标准库中的阻塞函数,例如那些执行网络和线程的函数,并基于 greenlets 实现了等效的非阻塞版本。如果你有一些同步代码想要异步运行,这些包会对你有所帮助。
据我所知,唯一明确支持 greenlet 的 Web 框架只有 Flask。这个框架会自动监测,当你想要运行在一个 greenlet Web 服务器上时,它会自我进行相应调整,而无需进行任何配置。这么做时,你需要注意不要调用阻塞函数,或者,如果你要调用阻塞函数,最好用猴子补丁来“修复”那些阻塞函数。
但是,Flask 并不是唯一受益于 greenlets 的框架。其它 Web 框架,例如 Django 和 Bottle,虽然没有 greenlets,但也可以通过结合一个 greenlet Web 服务器并使用 monkey-patching 修复阻塞函数的方式来异步运行。
对于同步和异步应用程序的性能,存在着一个广泛的误解——异步应用程序比同步应用程序快得多。
对此,我需要澄清一下。无论是用同步方式写,还是用异步方式写,Python 代码运行速度是几乎相同的。除了代码,有两个因素能够影响一个并发应用程序的性能:上下文切换和可扩展性。
3.1 上下文切换
在所有运行的任务间公平地共享 CPU 所需的工作,称为上下文切换,能够影响应用程序的性能。对同步应用程序来说,这项工作是由操作系统完成的,而且基本上是一个黑箱,不需要配置或微调选项。对异步应用程序来说,上下文切换是由循环完成的。
默认的循环实现由asyncio提供,是用 Python 编写的,效率不是很高。而 uvloop 包提供了一个备选的循环方案,其中部分代码是用 C 编写的来实现更好的性能。Gevent 和 Meinheld 所使用的事件循环也是用 C 编写的。Eventlet 用的是 Python 编写的循环。
高度优化的异步循环比操作系统在进行上下文切换方面更有效率,但根据我的经验,要想看到实际的效率提升,你运行的并发量必须非常大。对于大部分应用程序,我不认为同步和异步上下文切换之间的性能差距有多明显。
3.2 扩展性
我认为异步更快这个神话的来源是,异步应用程序通常会更有效地使用 CPU、能更好地进行扩展并且扩展方式比同步更灵活。
如果上面示意图中的同步服务器同时收到 100 个请求,想一下会发生什么。这个服务器同时最多只能处理 4 个请求,因此大部分请求会停留在一个队列中等待,直到它们被分配一个 worker。
与之形成对比的是,异步服务器会立即创建 100 个任务(或者使用混合模式的话,在 4 个异步 worker 上每个创建 25 个任务)。使用异步服务器,所有请求都会立即开始处理而不用等待(尽管公平地说,这种方案也还会有其它瓶颈会减慢速度,例如对活跃的数据库连接的限制)。
如果这 100 个任务主要使用 CPU,那么同步和异步方案会有相似的性能,因为每个 CPU 运行的速度是固定的,Python 执行代码的速度总是相同的,应用程序要完成的工作也是相同的。但是,如果这些任务需要做很多 I/O 操作,那么同步服务器只能处理 4 个并发请求而不能实现 CPU 的高利用率。而另一方面,异步服务器会更好地保持 CPU 繁忙,因为它是并行地运行所有这 100 个请求。
你可能会想,为什么你不能运行 100 个同步 worker,那样,这两个服务器就会有相同的并发能力。要注意,每个 worker 需要自己的 Python 解释器以及与之相关联的所有资源,再加上一份单独的应用程序拷贝及其资源。你的服务器和应用程序的大小将决定你可以运行多少个 worker 实例,但通常这个数字不会很大。另一方面,异步任务非常轻量,都运行在单个 worker 进程的上下文中,因此具有明显优势。
综上所述,只有如下场景时,我们可以说异步可能比同步快:
存在高负载(没有高负载,访问的高并发性就没有优势)
任务是 I/O 绑定的(如果任务是 CPU 绑定的,那么超过 CPU 数目的并发并没有帮助)
你查看单位时间内的平均请求处理数。如果你查看单个请求的处理时间,你不会看到有很大差别,甚至异步可能更慢,因为异步有更多并发的任务在争夺 CPU。
希望本文能解答异步代码的一些困惑和误解。我希望你能记住以下两个关键点:
异步应用程序只有在高负载下才会比同步应用程序做得更好
多亏了 greenlets,即使你用一般方式写代码并使用 Flask 或 Django 之类的传统框架,也能从异步中受益。
注意:如果你是打算找python高薪工作的话。我建议你多写点真实的企业项目积累经验。不然工作都找不到,当然很多人没进过企业,怎么会存在项目经验呢? 所以你得多找找企业项目实战多练习下撒。如果你很懒不想找,也可以进我的Python交流圈:1156465813。群文件里面有我之前在做开发写过的一些真实企业项目案例。你可以拿去学习,不懂都可以在裙里找我,有空会耐心给你解答下。
以下内容无用,为本篇博客被搜索引擎抓取使用
(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)
python 是干什么的 零基础学 python 要多久 python 为什么叫爬虫
python 爬虫菜鸟教程 python 爬虫万能代码 python 爬虫怎么挣钱
python 基础教程 网络爬虫 python python 爬虫经典例子
python 爬虫
(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)(* ̄︶ ̄)
以上内容无用,为本篇博客被搜索引擎抓取使用
标签:abs 自己的 sanic name 选择 根据 fast package 阻塞
原文地址:https://www.cnblogs.com/shuchongzeishuai/p/14014756.html