标签:cookies detail web 详情 auth 多个 参数 java 规律
Scrapy是一个Python编写的开源网络爬虫框架。它是一个被设计用于爬取网络数据、提取结构性数据的框架。
Scrapy 使用了Twisted[‘tw?st?d]异步网络框架,可以加快我们的下载速度。
少量的代码,就能够快速的抓取
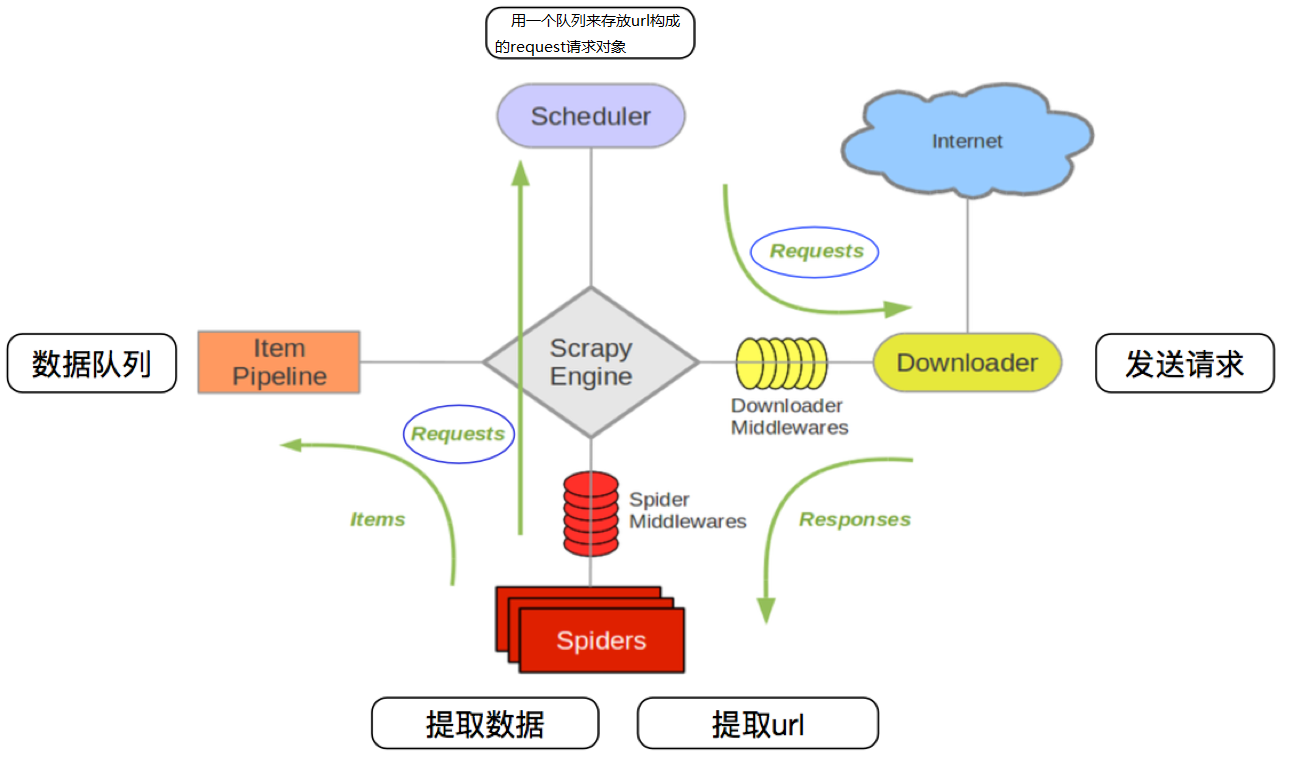
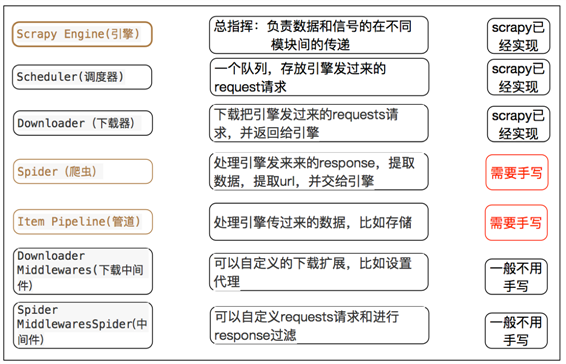
1. 爬虫中起始的url构造成request对象-->爬虫中间件-->引擎-->调度器
2. 调度器把request-->引擎-->下载中间件--->下载器
3. 下载器发送请求,获取response响应---->下载中间件---->引擎--->爬虫中间件--->爬虫
4. 爬虫提取url地址,组装成request对象---->爬虫中间件--->引擎--->调度器,重复步骤2
5. 爬虫提取数据--->引擎--->管道处理和保存数据
- 图中中文是为了方便理解后加上去的
- 图中绿色线条的表示数据的传递
- 注意图中中间件的位置,决定了其作用
- 注意其中引擎的位置,所有的模块之前相互独立,只和引擎进行交互
- request请求对象:由url method post_data headers等构成
- response响应对象:由url body status headers等构成
- item数据对象:本质是个字典
pip install scrapy
创建scrapy项目的命令: scrapy startproject <项目名字> 示例: scrapy startproject myspider

通过命令创建出爬虫文件,爬虫文件为主要的代码作业文件,通常一个网站的爬取动作都会在爬虫文件中进行编写。
命令:
在项目路径下执行
scrapy genspider <爬虫名字> <允许爬取的域名>
爬虫名字: 作为爬虫运行时的参数
允许爬取的域名:为对于爬虫设置的爬取范围,设置之后用于过滤要爬取的url,如果爬取的url与允许的域不通则被过滤掉。
示例:
cd myspider
scrapy genspider itcast itcast.cn


# -*- coding: utf-8 -*- import scrapy class ItcastSpider(scrapy.Spider): #爬虫名 name = ‘itcast‘ #域名,允许爬取的范围 allowed_domains = [‘itcast.cn‘] #开始爬取的url地址 start_urls = [‘http://www.itcast.cn/channel/teacher.shtml#ajavaee‘] def parse(self, response): #获取li 集合 teacher_list = response.xpath("//div[@class=‘tea_con‘]//li") #获取具体的数据文本 for li in teacher_list: item = {} item[‘name‘] = li.xpath(".//h3/text()").extract_first() item[‘level‘] = li.xpath(".//h4/text()").extract_first() item[‘text‘] = li.xpath(".//p/text()").extract_first() print(item)
- scrapy.Spider爬虫类中必须有名为parse的解析
- 如果网站结构层次比较复杂,也可以自定义其他解析函数
- 在解析函数中提取的url地址如果要发送请求,则必须属于allowed_domains范围内,但是start_urls中的url地址不受这个限制,我们会在后续的课程中学习如何在解析函数中构造发送请求
- 启动爬虫的时候注意启动的位置,是在项目路径下启动
- parse()函数中使用yield返回数据,**注意:解析函数中的yield能够传递的对象只能是:BaseItem, Request, dict, None**
> 解析并获取scrapy爬虫中的数据: 利用xpath规则字符串进行定位和提取
1. response.xpath方法的返回结果是一个类似list的类型,其中包含的是selector对象,操作和列表一样,但是有一些额外的方法
2. 额外方法extract():返回一个包含有字符串的列表
3. 额外方法extract_first():返回列表中的第一个字符串,列表为空没有返回None
- response.url:当前响应的url地址
- response.request.url:当前响应对应的请求的url地址
- response.headers:响应头
- response.requests.headers:当前响应的请求头
- response.body:响应体,也就是html代码,byte类型
- response.status:响应状态码
> 利用管道pipeline来处理(保存)数据
在pipelines.py文件中定义对数据的操作
1. 定义一个管道类
2. 重写管道类的process_item方法
3. process_item方法处理完item之后必须返回给引擎
class MyspriderPipeline(object): # 爬虫文件中提取数据的方法每yield一次item,就会运行一次 # 该方法为固定名称函数 def process_item(self, item, spider): print(item) return item
4: 在settings.py配置启用管道
ITEM_PIPELINES = { ‘myspider.pipelines.ItcastPipeline‘: 400 }
配置项中键为使用的管道类,管道类使用.进行分割,第一个为项目目录,第二个为文件,第三个为定义的管道类。
配置项中值为管道的使用顺序,设置的数值约小越优先执行,该值一般设置为1000以内。<br/>
5:运行scrapy
命令:在项目目录下执行scrapy crawl <爬虫名字>
示例:scrapy crawl itcast
通常在做项目的过程中,在items.py中进行数据建模
1. 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
2. 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
3. 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
在items.py文件中定义要提取的字段:
class MyspiderItem(scrapy.Item): name = scrapy.Field() # 讲师的名字 title = scrapy.Field() # 讲师的职称 desc = scrapy.Field() # 讲师的介绍
1.3 如何使用模板类
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
job.py:
from myspider.items import MyspiderItem # 导入Item,注意路径 def parse(self, response) item = MyspiderItem() # 实例化后可直接使用 item[‘name‘] = node.xpath(‘./h3/text()‘).extract_first() item[‘title‘] = node.xpath(‘./h4/text()‘).extract_first() item[‘desc‘] = node.xpath(‘./p/text()‘).extract_first() print(item)
注意:
1. from myspider.items import MyspiderItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误
2. python中的导入路径要诀:从哪里开始运行,就从哪里开始导入
1. 创建项目
scrapy startproject 项目名
2. 明确目标
在items.py文件中进行建模
3. 创建爬虫<br/>
4. 保存数据<br/>
在pipelines.py文件中定义对数据处理的管道<br/>
在settings.py文件中注册启用管道
对于要提取如下图中所有页面上的数据该怎么办?
回顾requests模块是如何实现翻页请求的:
scrapy实现翻页的思路:
3.1 实现方法
3.2 网易招聘爬虫
> 通过爬取网易招聘的页面的招聘信息,学习如何实现翻页请求
> 地址:https://hr.163.com/position/list.do
思路分析:
注意:
1. 可以在settings中设置ROBOTS协议
# False表示忽略网站的robots.txt协议,默认为True ROBOTSTXT_OBEY = False
2. 可以在settings中设置User-Agent:
scrapy发送的每一个请求的默认UA都是设置的这个User-Agent USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36‘
3.3 代码实现
在爬虫文件的parse方法中:
# 提取下一页的href next_url = response.xpath(‘//a[contains(text(),">")]/@href‘).extract_first() # 判断是否是最后一页 if next_url != ‘javascript:void(0)‘: # 构造完整url url = ‘https://hr.163.com/position/list.do‘ + next_url # 构造scrapy.Request对象,并yield给引擎 # 利用callback参数指定该Request对象之后获取的响应用哪个函数进行解析 yield scrapy.Request(url, callback=self.parse)
3.4 scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
参数解释
1. 中括号里的参数为可选参数
2. **callback**:表示当前的url的响应交给哪个函数去处理
3. **meta**:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
4. dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
5. method:指定POST或GET请求
6. headers:接收一个字典,其中不包括cookies
7. cookies:接收一个字典,专门放置cookies
8. body:接收json字符串,为POST的数据,发送payload_post请求时使用(在下一章节中会介绍post请求)
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response): yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item}) def parse_detail(self,response): #获取之前传入的item item = resposne.meta["item"]
特别注意
1. meta参数是一个字典
2. meta字典中有一个固定的键`proxy`,表示代理ip,关于代理ip的使用我们将在scrapy的下载中间件的学习中进行介绍
1.1 requests模块是如何实现模拟登陆的?
1.2 selenium是如何模拟登陆的?
1.3 scrapy的模拟登陆
应用场景
1. cookie过期时间很长,常见于一些不规范的网站
2. 能在cookie过期之前把所有的数据拿到
3. 配合其他程序使用,比如其使用selenium把登陆之后的cookie获取到保存到本地,scrapy发送请求之前先读取本地cookie
scrapy中start_url是通过start_requests来进行处理的,其实现代码如下
# 这是源代码 def start_requests(self): cls = self.__class__ if method_is_overridden(cls, Spider, ‘make_requests_from_url‘): warnings.warn( "Spider.make_requests_from_url method is deprecated; it " "won‘t be called in future Scrapy releases. Please " "override Spider.start_requests method instead (see %s.%s)." % ( cls.__module__, cls.__name__ ), ) for url in self.start_urls: yield self.make_requests_from_url(url) else: for url in self.start_urls: yield Request(url, dont_filter=True)
所以对应的,如果start_url地址中的url是需要登录后才能访问的url地址,则需要重写start_request方法并在其中手动添加上cookie
import scrapy import re class Login1Spider(scrapy.Spider): name = ‘login1‘ allowed_domains = [‘github.com‘] start_urls = [‘https://github.com/NoobPythoner‘] # 这是一个需要登陆以后才能访问的页面 def start_requests(self): # 重构start_requests方法 # 这个cookies_str是抓包获取的 cookies_str = ‘...‘ # 抓包获取 # 将cookies_str转换为cookies_dict cookies_dict = {i.split(‘=‘)[0]:i.split(‘=‘)[1] for i in cookies_str.split(‘; ‘)} yield scrapy.Request( self.start_urls[0], callback=self.parse, cookies=cookies_dict ) def parse(self, response): # 通过正则表达式匹配用户名来验证是否登陆成功 # 正则匹配的是github的用户名 result_list = re.findall(r‘noobpythoner|NoobPythoner‘, response.body.decode()) print(result_list) pass
注意:
1. scrapy中cookie不能够放在headers中,在构造请求的时候有专门的cookies参数,能够接受字典形式的coookie
2. 在setting中设置ROBOTS协议、USER_AGENT
我们知道可以通过scrapy.Request()指定method、body参数来发送post请求;但是通常使用scrapy.FormRequest()来发送post请求
> 注意:scrapy.FormRequest()能够发送表单和ajax请求,参考阅读 https://www.jb51.net/article/146769.htm
3.1.1 思路分析
3.1.2 代码实现如下:
import scrapy import re class Login2Spider(scrapy.Spider): name = ‘login2‘ allowed_domains = [‘github.com‘] start_urls = [‘https://github.com/login‘] def parse(self, response): authenticity_token = response.xpath("//input[@name=‘authenticity_token‘]/@value").extract_first() utf8 = response.xpath("//input[@name=‘utf8‘]/@value").extract_first() commit = response.xpath("//input[@name=‘commit‘]/@value").extract_first() #构造POST请求,传递给引擎 yield scrapy.FormRequest( "https://github.com/session", formdata={ "authenticity_token":authenticity_token, "utf8":utf8, "commit":commit, "login":"noobpythoner", "password":"***" }, callback=self.parse_login ) def parse_login(self,response): ret = re.findall(r"noobpythoner|NoobPythoner",response.text) print(ret)
小技巧
在settings.py中通过设置COOKIES_DEBUG=TRUE 能够在终端看到cookie的传递传递过程
1. process_item(self,item,spider):
2. open_spider(self, spider): 在爬虫开启的时候仅执行一次
3. close_spider(self, spider): 在爬虫关闭的时候仅执行一次
继续完善wangyi爬虫,在pipelines.py代码中完善
import json from pymongo import MongoClient class WangyiFilePipeline(object): def open_spider(self, spider): # 在爬虫开启的时候仅执行一次 if spider.name == ‘itcast‘: self.f = open(‘json.txt‘, ‘a‘, encoding=‘utf-8‘) def close_spider(self, spider): # 在爬虫关闭的时候仅执行一次 if spider.name == ‘itcast‘: self.f.close() def process_item(self, item, spider): if spider.name == ‘itcast‘: self.f.write(json.dumps(dict(item), ensure_ascii=False, indent=2) + ‘,\n‘) # 不return的情况下,另一个权重较低的pipeline将不会获得item return item class WangyiMongoPipeline(object): def open_spider(self, spider): # 在爬虫开启的时候仅执行一次 if spider.name == ‘itcast‘: # 也可以使用isinstanc函数来区分爬虫类: con = MongoClient(host=‘127.0.0.1‘, port=27017) # 实例化mongoclient self.collection = con.itcast.teachers # 创建数据库名为itcast,集合名为teachers的集合操作对象 def process_item(self, item, spider): if spider.name == ‘itcast‘: self.collection.insert(item) # 此时item对象必须是一个字典,再插入 # 如果此时item是BaseItem则需要先转换为字典:dict(BaseItem) # 不return的情况下,另一个权重较低的pipeline将不会获得item return item
在settings.py设置开启pipeline
ITEM_PIPELINES = { ‘myspider.pipelines.ItcastFilePipeline‘: 400, # 400表示权重 ‘myspider.pipelines.ItcastMongoPipeline‘: 500, # 权重值越小,越优先执行! }
思考:在settings中能够开启多个管道,为什么需要开启多个?
1. 不同的pipeline可以处理不同爬虫的数据,通过spider.name属性来区分
2. 不同的pipeline能够对一个或多个爬虫进行不同的数据处理的操作,比如一个进行数据清洗,一个进行数据的保存
3. 同一个管道类也可以处理不同爬虫的数据,通过spider.name属性来区分
1. 使用之前需要在settings中开启
2. pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:**权重值小的优先执行**
3. 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
4. pipeline中process_item的方法必须有,否则item没有办法接受和处理
5. process_item方法接受item和spider,其中spider表示当前传递item过来的spider
6. open_spider(spider) :能够在爬虫开启的时候执行一次
7. close_spider(spider) :能够在爬虫关闭的时候执行一次
8. 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
1.2 scrapy中间的作用:预处理request和response对象
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
> 接下来我们对腾讯招聘爬虫进行修改完善,通过下载中间件来学习如何使用中间件
> 编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:
- process_request(self, request, spider):
- process_response(self, request, response, spider):
- 在settings.py中配置开启中间件,权重值越小越优先执行
3.1 在middlewares.py中完善代码
import random from Tencent.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示 class UserAgentMiddleware(object): def process_request(self, request, spider): user_agent = random.choice(USER_AGENTS_LIST) request.headers[‘User-Agent‘] = user_agent # 不写return class CheckUA: def process_response(self,request,response,spider): print(request.headers[‘User-Agent‘]) return response # 不能少!
3.2 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = { ‘Tencent.middlewares.UserAgentMiddleware‘: 543, # 543是权重值 ‘Tencent.middlewares.CheckUA‘: 600, # 先执行543权重的中间件,再执行600的中间件 }
3.3 在settings中添加UA的列表
USER_AGENTS_LIST = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" ]
1. 代理添加的位置:request.meta中增加`proxy`字段
2. 获取一个代理ip,赋值给`request.meta[‘proxy‘]`
4.2 具体实现
免费代理ip:
``` class ProxyMiddleware(object): def process_request(self,request,spider): # proxies可以在settings.py中,也可以来源于代理ip的webapi # proxy = random.choice(proxies) # 免费的会失效,报 111 connection refused 信息!重找一个代理ip再试 proxy = ‘https://1.71.188.37:3128‘ request.meta[‘proxy‘] = proxy return None
收费代理ip:
# 人民币玩家的代码(使用abuyun提供的代理ip) import base64 # 代理隧道验证信息 这个是在那个网站上申请的 proxyServer = ‘http://proxy.abuyun.com:9010‘ # 收费的代理ip服务器地址,这里是abuyun proxyUser = 用户名 proxyPass = 密码 proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass) class ProxyMiddleware(object): def process_request(self, request, spider): # 设置代理 request.meta["proxy"] = proxyServer # 设置认证 request.headers["Proxy-Authorization"] = proxyAuth
4.3 检测代理ip是否可用
在使用了代理ip的情况下可以在下载中间件的process_response()方法中处理代理ip的使用情况,如果该代理ip不能使用可以替换其他代理ip
class ProxyMiddleware(object): ...... def process_response(self, request, response, spider): if response.status != ‘200‘: request.dont_filter = True # 重新发送的请求对象能够再次进入队列 return requst
在settings.py中开启该中间件
> 以github登陆为例
5.1 完成爬虫代码
import scrapy class Login4Spider(scrapy.Spider): name = ‘login4‘ allowed_domains = [‘github.com‘] start_urls = [‘https://github.com/1596930226‘] # 直接对验证的url发送请求 def parse(self, response): with open(‘check.html‘, ‘w‘) as f: f.write(response.body.decode())
5.2 在middlewares.py中使用selenium
import time from selenium import webdriver def getCookies(): # 使用selenium模拟登陆,获取并返回cookie username = input(‘输入github账号:‘) password = input(‘输入github密码:‘) options = webdriver.ChromeOptions() options.add_argument(‘--headless‘) options.add_argument(‘--disable-gpu‘) driver = webdriver.Chrome(‘/home/worker/Desktop/driver/chromedriver‘, chrome_options=options) driver.get(‘https://github.com/login‘) time.sleep(1) driver.find_element_by_xpath(‘//*[@id="login_field"]‘).send_keys(username) time.sleep(1) driver.find_element_by_xpath(‘//*[@id="password"]‘).send_keys(password) time.sleep(1) driver.find_element_by_xpath(‘//*[@id="login"]/form/div[3]/input[3]‘).click() time.sleep(2) cookies_dict = {cookie[‘name‘]: cookie[‘value‘] for cookie in driver.get_cookies()} driver.quit() return cookies_dict class LoginDownloaderMiddleware(object): def process_request(self, request, spider): cookies_dict = getCookies() print(cookies_dict) request.cookies = cookies_dict # 对请求对象的cookies属性进行替换
配置文件中设置开启该中间件后,运行爬虫可以在日志信息中看到selenium相关内容
标签:cookies detail web 详情 auth 多个 参数 java 规律
原文地址:https://www.cnblogs.com/1164xiepei-qi/p/14033671.html
