标签:避免 有一个 瓶颈 callback 信息 服务质量 back 实现 pidof
原创 宋宝华 Linux阅码场 2019-12-23前言
网上关于BIO和块设备读写流程的文章何止千万,但是能够让你彻底读懂读明白的文章实在难找,可以说是越读越糊涂!
我曾经跨过山和大海 也穿过人山人海
我曾经问遍整个世界 从来没得到答案
本文用一个最简单的read(fd, buf, 4096)的代码,分析它从开始读到读结束,在整个Linux系统里面波澜壮阔的一生。本文涉及到的代码如下:
#include <unistd.h>
#include <fcntl.h>
main()
{
int fd;
char buf[4096];
sleep(30); //run ./funtion.sh to trace vfs_read of this process
fd = open("file", O_RDONLY);
read(fd, buf, 4096);
read(fd, buf, 4096);
}本文的写作宗旨是:绝不装逼,一定要简单,简单,再简单!
本文适合:已经读了很多乱七八糟的block资料,但是没打通脉络的读者;
本文不适合:完全不知道block子系统是什么的读者,和完全知道block子系统是什么的读者
在Linux中,内存充当硬盘的page cache,所以,每次读的时候,会先check你读的那一部分硬盘文件数据是否在内存命中,如果没有命中,才会去硬盘;如果已经命中了,就直接从内存里面读出来。如果是写的话,应用如果是以非SYNC方式写的话,写的数据也只是进内存,然后由内核帮忙在适当的时机writeback进硬盘。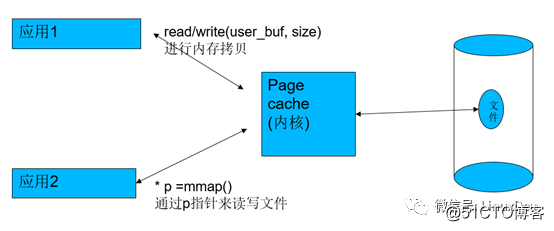
代码中有2行read(fd, buf, 4096),第1行read(fd, buf, 4096)发生的时候,显然”file”文件中的数据都不在内存,这个时候,要执行真正的硬盘读,app只想读4096个字节(一页),但是内核不会只是读一页,而是要多读,提前读,把用户现在不读的也先读,因为内核怀疑你读了一页,接着要连续读,怀疑你想读后面的。与其等你发指令,不如提前先斩后奏(存储介质执行大块读比多个小块读要快),这个时候,它会执行预读,直接比如读4页,这样当你后面接着读第2-4页的硬盘数据的时候,其实是直接命中了。
所以这个代码路径现在是 :
当你执行完第一个read(fd, buf, 4096)后,”file”文件的0~16KB都进入了pagecache,同时内核会给第2页标识一个PageReadahead标记,意思就是如果app接着读第2页,就可以预判app在做顺序读,这样我们在app读第2页的时候,内核可以进一步异步预读。
第一个read(fd,buf, 4096)之前,page cache命中情况(都不命中):
第一个read(fd,buf, 4096)之后,page cache命中情况:
我们紧接着又碰到第二个read(fd, buf, 4096),它要读硬盘文件的第2页内容,这个时候,第2页是page cache命中的,这一次的读,由于第2页有PageReadahead标记,让内核觉得app就是在顺序读文件,内核会执行更加激进的异步预读,比如读文件的第16KB~48KB。
所以第二个read(fd,buf, 4096)的代码路径现在是 :
第二个read(fd,buf, 4096)之前,page cache命中情况:
第二个read(fd,buf, 4096)之后,page cache命中情况:
刚才我们提到,第一次的read(fd, buf, 4096),变成了读硬盘里面的16KB数据,到内存的4个页面(对应硬盘里面文件数据的第0~16KB)。但是我们还是不知道,硬盘里面文件数据的第0~16KB在硬盘的哪些位置?我们必须把内存的页,转化为硬盘里面真实要读的位置。
在Linux里面,用于描述硬盘里面要真实操作的位置与page cache的页映射关系的数据结构是bio。相信大家已经见到bio一万次了,但是就是和真实的案例对不上。
bio的定义如下(include/linux/blk_types.h):
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
…
struct bvec_iter bi_iter;
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
…
bio_end_io_t *bi_end_io;
void *bi_private;
unsigned short bi_vcnt; /* how many bio_vec‘s */
atomic_t bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
…
};它是一个描述硬盘里面的位置与page cache的页对应关系的数据结构,每个bio对应的硬盘里面一块连续的位置,每一块硬盘里面连续的位置,可能对应着page cache的多页,或者一页,所以它里面会有一个bio_vec *bi_io_vec的表。
我们现在假设2种情况
第1种情况是page_cache_sync_readahead()要读的0~16KB数据,在硬盘里面正好是顺序排列的(是否顺序排列,要查文件系统,如ext3、ext4),Linux会为这一次4页的读,分配1个bio就足够了,并且让这个bio里面分配4个bi_io_vec,指向4个不同的内存页: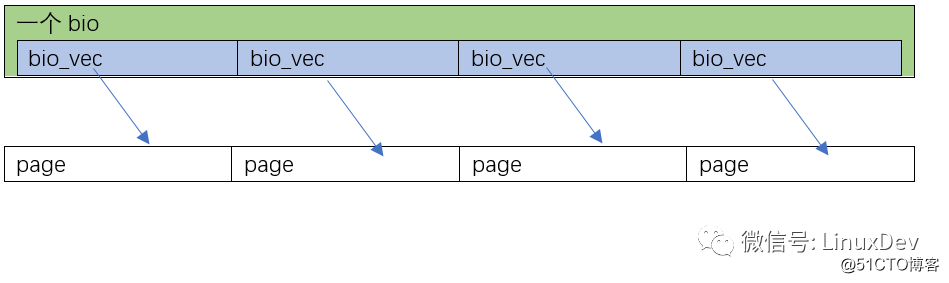
第2种情况是page_cache_sync_readahead()要读的0~16KB数据,在硬盘里面正好是完全不连续的4块 (是否顺序排列,要查文件系统,如ext3、ext4),Linux会为这一次4页的读,分配4个bio,并且让这4个bio里面,每个分配1个bi_io_vec,指向4个不同的内存页面: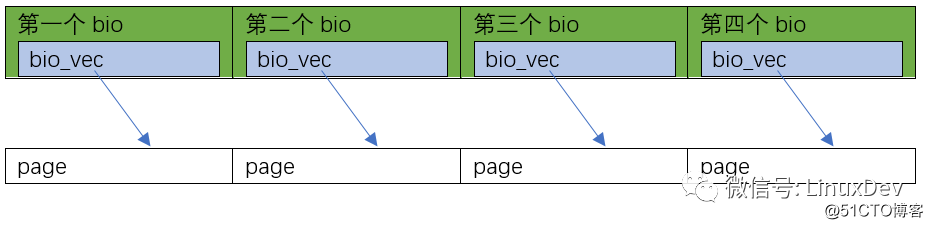
当然你还可以有第3种情况,比如0~8KB在硬盘里面连续,8~16KB不连续,那可以是这样的: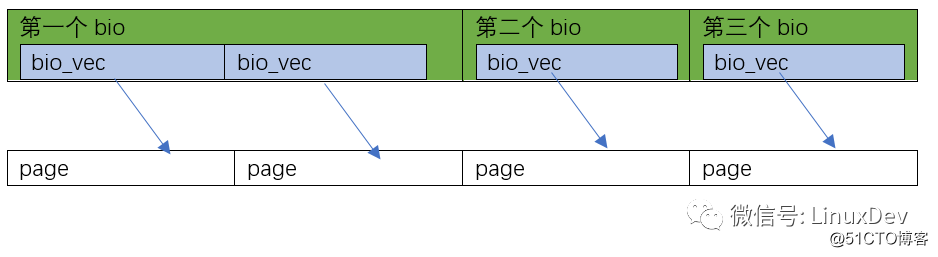
其他的情况请类似推理…完成这项工作的史诗级的代码就是mpage_readpages()。
mpage_readpages()会间接调用ext4_get_block(),真的搞清楚0~16KB的数据,在硬盘里面的摆列位置,并依据这个信息,转化出来一个个的bio。
人生,说到最后,简单得只有生死两个字。但由于有了命运的浮沉,由于有了人世的冷暖,简单的过程才变得跌宕起伏,纷繁复杂。小平三落三起,最终建立了不朽的功勋。曼德拉受非人待遇在监狱服刑数十年,终成世界公认的领袖。走向自由之路不会平坦,斗争就是生活。与天斗,其乐无穷;与地斗,其乐无穷;与Linux斗,痛苦无穷!
bio产生后,到最终的完成,同样经历了三进三出的队列,这个过程的艰辛和痛苦,让人欲罢不能,欲说还休,求生不得求死不能。
这三步是:
1.原地蓄势
把bio转化为request,把request放入进程本地的plug队列;蓄势多个request后,再进行泄洪。
2.电梯排序
进程本地的plug队列的request进入到电梯,进行再次的合并、排序,执行QoS的排队,之后按照QoS的结果,分发给块设备驱动。电梯内部的实现,可以有各种各样的队列。
3.分发执行
电梯分发的request,被设备驱动的request_fn()挨个取出来,派发真正的硬件读写命令到硬盘。这个分发的队列,一般就是我们在块设备驱动里面见到的request_queue了。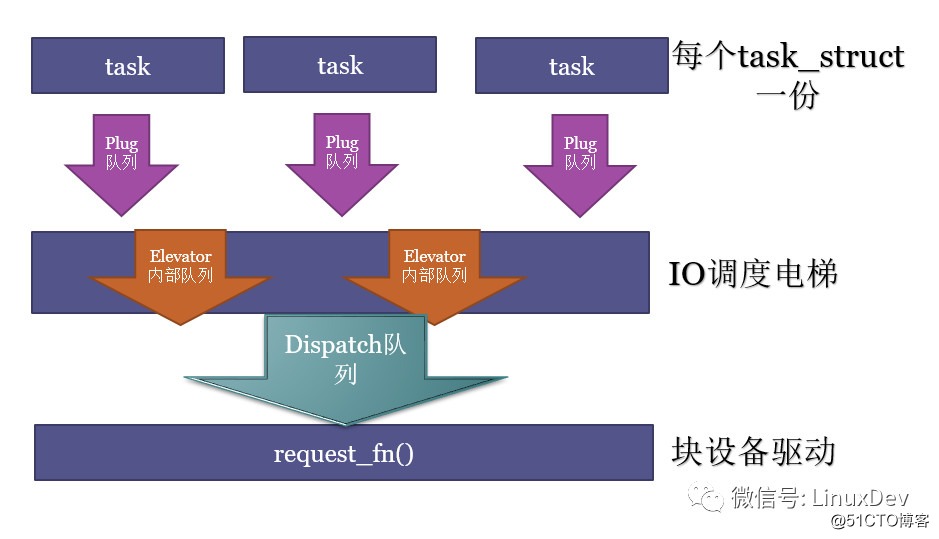
下面我们再一一呈现,这三进三出。
在Linux中,每个task_struct(对应一个进程,或轻量级进程——线程),会有一个plug的list。什么叫plug呢?类似于葛洲坝和三峡,先蓄水,当app需要发多个bio请求的时候,比较好的办法是先蓄势,而不是一个个单独发给最终的硬盘。
这个类似你现在有10个老师,这10个老师开学的时候都接受学生报名。然后有一个大的学生队列,如果每个老师有一个学生报名的时候,都访问这个唯一的学生队列,那么这个队列的操作会变成一个重要的锁瓶颈: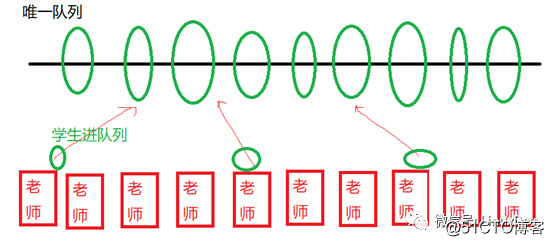
如果我们换一个方法,让每个老师有学生报名的时候,每天的报名的学生挂在老师自己的队列上面,老师的队列上面挂了很多学生后,一天之后再泄洪,挂到最终的学生队列,则可以避免这个问题,最终小队列融合进大队列的时候控制住时序就好。
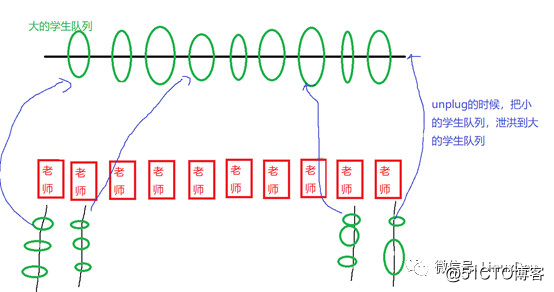
你会发现,代码路径是这样的:
read_pages()函数先把闸门拉上,然后发起一系列bio后,再通过blk_finish_plug()的调用来泄洪。
在这个蓄势的过程中,还要完成一项重要的工作,就是make request(造请求)。这个完成“造请求”的史诗级的函数,一般是void blk_queue_bio(struct request_queue q, struct bio bio),位于block/blk-core.c。
它会尝试把bio合并进入一个进程本地plug list里面的一个request,如果无法合并,则造一个新的request。request里面包含一个bio的list,这个list的bio对应的硬盘位置,最终在硬盘上是连续存放的。
下面我们假设"file"的第0~16KB在硬盘的存放位置为:
根据我们前面"内存到硬盘的转换"一节举的例子,这属于在硬盘里面完全不连续的"情况2",于是这4块数据,会被史诗级的mpage_readpages()转化为4个bio。
当他们进入进程本地的plug list的时候,由于最开始plug list为空,100显然无法与谁合并,这样形成一个新的request0。
Bio1也无法合并进request0,于是得到新的request1。
Bio2正好可以合并进request1,于是Bio1合并进request1。
Bio3对应硬盘的200块,无法合并,于是得到新的request2。
现在进程本地plug list上的request排列如下:
泄洪的时候,进程本地的plug list的request,会通过调用elevator调度算法的elevator_add_req_fn() callback函数,被加入电梯的队列。
当各个进程本地的plug list里面的request被泄洪,以排山倒海之势进入的,不是最终的设备驱动(不会直接被拍死在沙滩上的),而是一个电梯排队算法,进行再一次的排队。这个电梯调度,其实目的3个:
电梯的内部实现可以非常灵活,但是入口是elevator_add_req_fn(),出口是elevator_dispatch_fn()。
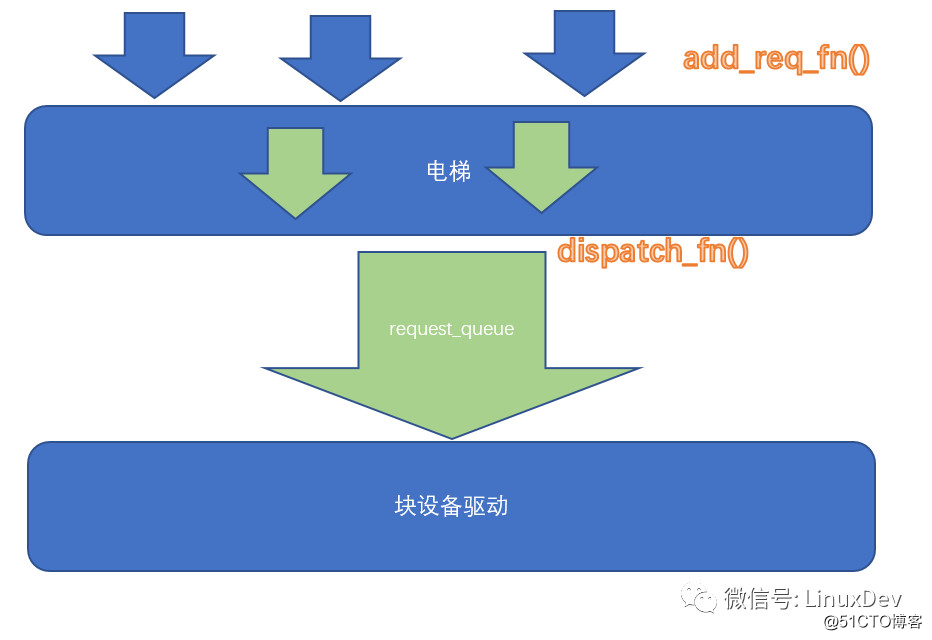
合并和排序都好理解,下面我们重点解释QoS(服务质量)。想象你家里的宽带,有迅雷,有在线电影,有机顶盒看电视。
当你只用迅雷下电影的时候,你当然可以全速的下电影,但是当你还看电视,在线看电影,这个时候,你可能会对迅雷限流,以保证相关电视盒电影的服务质量。
电梯调度里面也执行同样的逻辑,比如CFQ调度算法,可以根据进程的ionice,调整不同进程访问硬盘的时候的优先级。比如,如下2个优先级不同的dd
# ionice-c 2 -n 0 cat /dev/sda > /dev/null&
# ionice -c 2 -n 7 cat /dev/sda >/dev/null&最终访问硬盘的速度是不一样的,一个371M,一个只有72M。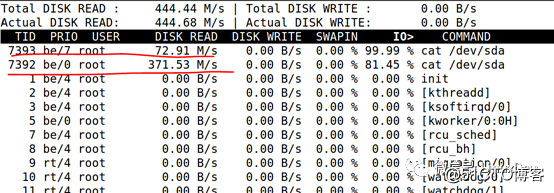
所以当泄洪开始,漫江碧透,百舸争流,谁能到中流击水,浪遏飞舟?QoS是一个关于一将功成万骨枯的故事。
目前常用的IO电梯调度算法有:cfq, noop, deadline。详细的区别不是本文的重点,建议阅读《刘正元:Linux 通用块层之DeadLine IO调度器》从了解deadline的实现开始。
到了最后要交差的时刻了,设备驱动的request_fn()通过调用电梯调度算法的elevator_dispatch_fn()取出经过QoS排序后的request并发命令给最终的存储设备执行I/O动作。
static void xxx_request_fn(struct request_queue *q)
{
struct request *req;
struct bio *bio;
while ((req = blk_peek_request(q)) != NULL) {
struct xxx_disk_dev *dev = req->rq_disk->private_data;
if (req->cmd_type != REQ_TYPE_FS) {
printk (KERN_NOTICE "Skip non-fs request\n");
blk_start_request(req);
__blk_end_request_all(req, -EIO);
continue;
}
blk_start_request(req);
__rq_for_each_bio(bio, req)
xxx_xfer_bio(dev, bio);
}
}request_fn()只是派发读写事件和命令,最终的完成一般是在另外一个上下文,而不是发起IO的进程。request处理完成后,探知到IO完成的上下文会以blk_end_request()的形式,通知等待IO请求完成的本进程。主动发起IO的进程的代码序列一般是:
blk_end_request()一般把io_schedule()后放弃CPU的进程唤醒。io_schedule()的这段等待时间,会计算到进程的iowait时间上,详见:《朱辉(茶水):Linux Kernel iowait 时间的代码原理》。
本文所涉及到的所有流程,都可以用ftrace跟踪到。这样可以了解更多更深刻的细节。
char buf[4096];
sleep(30); //run ./funtion.sh to trace vfs_read of this process
fd = open("file", O_RDONLY);
read(fd, buf, 4096);在上述代码的中间,我特意留下了30秒的延时,在这个延时的空挡,你可以启动如下的脚本,来对整个过程进行function graph的trace,抓取进程对vfs_read()开始后的调用栈:
#!/bin/bash
debugfs=/sys/kernel/debug
echo nop > $debugfs/tracing/current_tracer
echo 0 > $debugfs/tracing/tracing_on
echo `pidof read` > $debugfs/tracing/set_ftrace_pid
echo function_graph > $debugfs/tracing/current_tracer
echo vfs_read > $debugfs/tracing/set_graph_function
echo 1 > $debugfs/tracing/tracing_on笔者也是通过ftrace的结果,用vim打开,逐句分析的。关于ftrace使用的详细方法,可以阅读《宋宝华:关于Ftrace的一个完整案例》。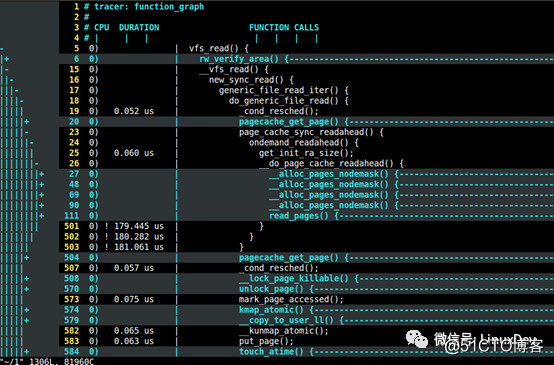
本文描述的是主干,许多的细节和代码分支没有涉及,因为在本文描述太多的分支,会让读者抓不住主干。很多分支都没有介绍,比如unplug的泄洪,除了可以人为的blk_finish_plug()泄洪外,也会发生plug队列较满的时候,以及进程睡眠schedule()的时候的自动泄洪。另外,关于写,后面的三进三出的过程,基本与读类似,但是写有个page cache堆积和writeback的启动机制,是read所没有的。
(完)
标签:避免 有一个 瓶颈 callback 信息 服务质量 back 实现 pidof
原文地址:https://blog.51cto.com/15015138/2555506