标签:组成 pat 全连接 random func 环境搭建 continue sse numpy
开发工具Python版本:3.6.4
相关模块:
numpy模块;
argparse模块;
pygame模块;
以及一些python自带的模块。
安装Python并添加到环境变量,pip安装需要的相关模块即可。
遗传算法,即:
Genetic Algorithm, GA
是一种元启发式算法,其核心思想与达尔文的进化理论很相似。简单而言就是物种在进化过程中,好的基因将得到保留,不好的基因将被淘汰。经过很多代的演变之后,物种当前保留下来的基因就可以看作是对当前环境适应度最好的基因了。
具体应用到我们的小恐龙小游戏上,我们设计算法的思路如下。首先,随机生成若干个小恐龙(比如100个):
self.dinos = [Dinosaur(cfg.IMAGEPATHS[‘dino‘]) for in range(self.population_size)]
每个恐龙的行动由一个小的神经网络来控制:
self.populations = [Network() for _ in range(self.population_size)]
其中,每个神经网络都是由两个全连接层组成,且他们的权重矩阵都是随机生成的:
‘‘‘define the network‘‘‘
class Network():
def __init__(self, fc1=None, fc2=None, **kwargs):
self.fc1 = np.random.randn(5, 16) if fc1 is None else fc1
self.fc2 = np.random.randn(16, 2) if fc2 is None else fc2
self.fitness = 0
‘‘‘predict the action‘‘‘
def predict(self, x):
x = x.dot(self.fc1)
x = self.activation(x)
x = x.dot(self.fc2)
x = self.activation(x)
return x
‘‘‘activation function‘‘‘
def activation(self, x):
return 0.5 * (1 + np.tanh(0.5 * x))
每个全连接层的输出结果由以下函数激活以保证输出值的范围都在0到1之间:
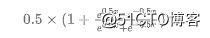
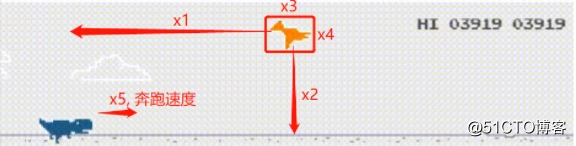
网络的输入值有5个,分别为:
画个示意图就是:
接着,我们让这些神经网络来控制对应的小恐龙进行游戏:
‘‘‘make decision for all dinos‘‘‘
def makedecision(self, x):
threshold = 0.55
actions = self.ai.predict(x)
for i in range(len(actions)):
action = actions[i]
if self.dinos[i].is_dead:
continue
if action[0] >= threshold:
self.dinos[i].jump(self.sounds)
elif action[1] >= threshold:
self.dinos[i].duck()
else:
self.dinos[i].unduck()
self.ai.populations[i].fitness = self.dinos[i].score直到所有的神经网络都让自己控制的小恐龙因为撞到路上的障碍物而死掉。接下来,我们从这些神经网络中选出几个让小恐龙存活的时间最久的(比如选两个,也就是对应控制的小恐龙得分最高的两个):
def keepbest(self):
self.populations.sort(key=lambda x: x.fitness, reverse=True)
self.keeped_nets = self.populations[:self.num_keeped_nets]
让选出的神经网络的权重矩阵进行交叉和变异,从而生成新的一批神经网络:
‘‘‘crossover‘‘‘
def crossover(self):
def crossoverweight(fc1, fc2):
assert len(fc1) == len(fc2)
crossover_len = int(len(fc1) * random.uniform(0, 1))
for i in range(crossover_len):
fc1[i], fc2[i] = fc2[i], fc1[i]
return fc1, fc2
nets_new = []
size = min(self.num_keeped_nets * self.num_keeped_nets, self.population_size)
for _ in range(size):
net_1 = copy.deepcopy(random.choice(self.keeped_nets))
net_2 = copy.deepcopy(random.choice(self.keeped_nets))
for _ in range(self.num_crossover_times):
net_1.fc1, net_2.fc1 = crossoverweight(net_1.fc1, net_2.fc1)
net_1.fc2, net_2.fc2 = crossoverweight(net_1.fc2, net_2.fc2)
nets_new.append(net_1)
return nets_new
‘‘‘mutate‘‘‘
def mutate(self, net):
def mutateweight(fc, prob):
if random.uniform(0, 1) < prob:
return fc * random.uniform(0.5, 1.5)
else:
return fc
net = copy.deepcopy(net)
net.fc1 = mutateweight(net.fc1, self.mutation_prob)
net.fc2 = mutateweight(net.fc2, self.mutation_prob)
return net同样地,这批神经网络每个都会分别控制一只新的小恐龙来进行游戏,直到这批新的神经网络控制下的小恐龙再次全部死掉。此时,重复之前的动作,即选择其中表现最好的几个神经网络并进行交叉变异,然后再次开始新的游戏,如此反复循环,直到得到满意的效果。
嗯,原理大概就是这样,完整源代码详见相关文件呗~
标签:组成 pat 全连接 random func 环境搭建 continue sse numpy
原文地址:https://blog.51cto.com/15010956/2557506