标签:utf8 === write 错误 efi use code ict 用户
最近写个简单的爬取贴吧数据的demo,分享给大家
爬取内容包括:
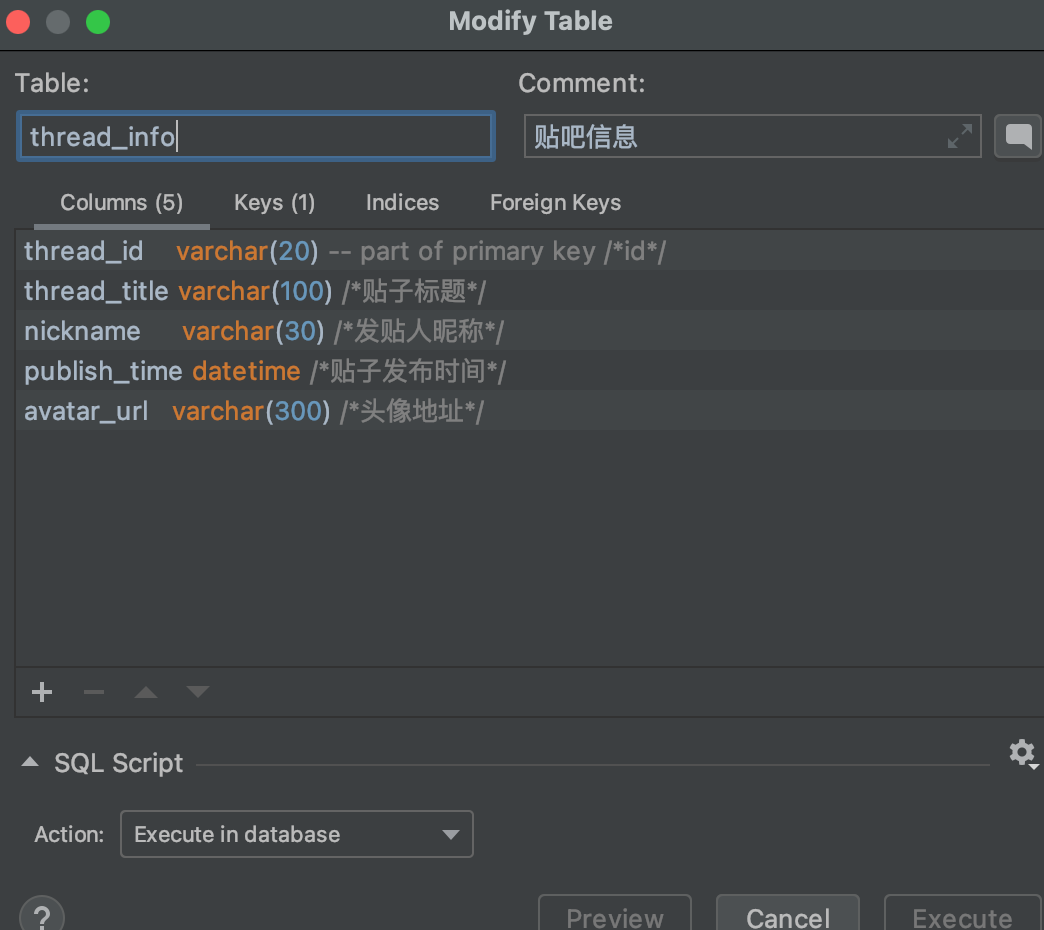
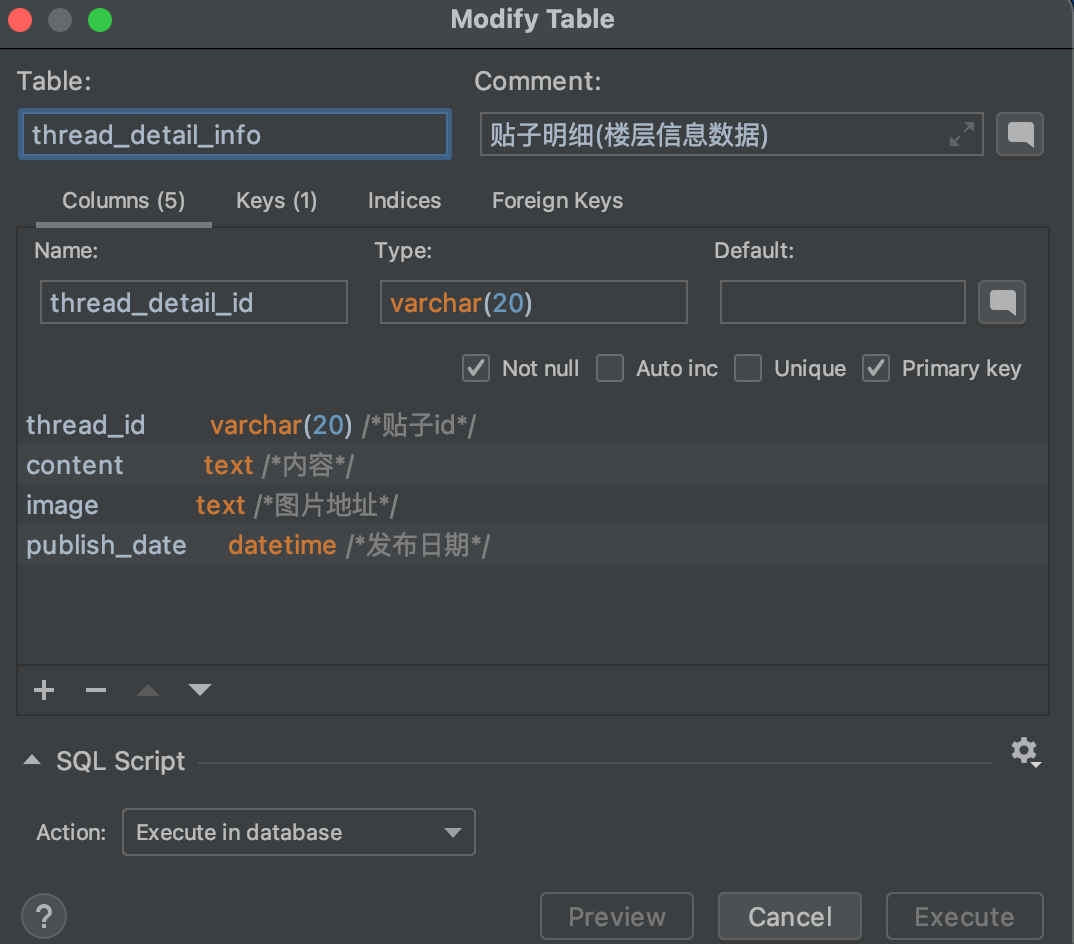
import requests import parsel # pip install parsel import urllib.request import urllib.parse import re import json import pymysql from pymysql.cursors import DictCursor header = { ‘user-agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36‘ } file = open(‘电脑吧数据.txt‘, ‘w‘, encoding=‘utf-8‘) # 爬取贴吧数据 def spider(startpage ,endpage, pagesize): page_num = 0 # range 左包右不包 for page in range(startpage, endpage + 1, pagesize): page_num += 1 print(‘===================正在抓取贴吧的第{}页数据===================‘.format(page_num)) url = ‘https://tieba.baidu.com/f?kw=%E7%94%B5%E8%84%91&ie=utf-8&pn={}‘.format(page) page_data(url) # 解析贴吧主页 def page_data(url): request = urllib.request.Request(url=url, headers=header) response = urllib.request.urlopen(request) html = response.read().decode(‘utf-8‘) # 解析帖子地址 thread_ids = re.findall(r‘href="/p/(\d+)"‘, html) # thread_urls = [‘http://tieba.baidu.com/p/‘ + str(url) for url in thread_ids] # for url in thread_urls: for thread_id in thread_ids: parser_thread(thread_id) # 解析帖子内容 def parser_thread(thread_id): thread_url = ‘http://tieba.baidu.com/p/‘ + str(thread_id) #print(‘id‘, thread_id) print(‘thread_url‘, thread_url) # 解析帖子第一页数据,获取帖子总页数 response = requests.get(thread_url, headers=header).text response_data = parsel.Selector(response) # 标题 thread_title = response_data.xpath(‘//h1/text()‘).extract()[0] # 发帖时间 content_field = response_data.xpath(‘//div[contains(@class,"l_post j_l_post l_post_bright")]/@data-field‘).extract() content_field_json = json.loads(content_field[0]) publish_date = content_field_json[‘content‘][‘date‘] # 楼主昵称 ps:如果名字中有图片/字符可能导致不完整 thread_author = content_field_json[‘author‘][‘user_name‘] # 楼主头像地址 avatar_url = ‘https:‘ + response_data.xpath(‘//ul/li/div/a/img/@src‘).extract()[0] # 帖子总回复数 thread_reply_count = response_data.xpath(‘//li[@class="l_reply_num"]/span/text()‘).extract()[0] # 帖子总页数 thread_page_count = int(response_data.xpath(‘//li[@class="l_reply_num"]/span/text()‘).extract()[1]) # print(‘----------------------------------------\n‘) # print(‘id:‘, thread_id) # print(‘链接:‘, thread_url) # print(‘标题:‘, thread_title) # print(‘日期:‘, publish_date) # print(‘作者:‘, thread_author) # print(‘头像:‘, avatar_url) # 保存贴子主数据 save_thread(thread_id, thread_title, thread_author, publish_date, avatar_url) # print(‘帖子总页数:{0},帖子总回复数:{1}‘.format(thread_page_count,thread_reply_count)) # for page_index in range(0, thread_page_count+1): # page_url = thread_url+"?pn={}".format(page_index+1) # parser_thread_detail(thread_url) # 帖子内容集合 thread_contents = response_data.xpath(‘.//div[contains(@id,"post_content_")]‘) # index 楼层 index = 0 while index < len(thread_contents): # 楼层文案 content_text = thread_contents.xpath(‘string(.)‘).extract()[index] # 楼层前面空格去除 content_text = content_text[12:] field_json = json.loads(content_field[index]) detail_publish_date = field_json[‘content‘][‘date‘] thread_detail_id = field_json[‘content‘][‘post_id‘] # 该层的Selector content_sel = thread_contents[index] # 获取该层图片 images = content_sel.xpath(‘img/@src‘).extract() index = index + 1 print(‘第{}楼‘.format(index)) # print(‘文案:‘, content_text) save_thread_detail(thread_detail_id, thread_id, content_text, str(images), detail_publish_date) # thread_images = response_data.xpath(‘//cc/div/img[@class="BDE_Image"]/@src‘).extract() # saveImg(thread_images) # 保存贴子主数据 def save_thread(thread_id, thread_title, nickname, publish_time, avatar_url): # SQL 插入语句 sql = ‘insert into thread_info(thread_id, thread_title, nickname, publish_time, avatar_url) ‘ ‘value (%s, %s, %s, %s, %s )‘ try: conn = pymysql.connect( host=‘47.101.213.133‘, # 连接名 port=3306, # 端口 user=‘dreaming‘, # 用户名 password=‘30wish2003!‘, # 密码 charset=‘utf8‘, # 不能写utf-8 在MySQL里面写utf-8会报错 database=‘x_player‘, # 数据库库名 cursorclass=DictCursor) # 使用cursor()方法获取操作游标 cursor = conn.cursor() # 执行sql语句 r = cursor.execute(sql, (thread_id, thread_title, nickname, publish_time, avatar_url)) # r = cursor.execute(sql) # 提交到数据库执行 conn.commit() print(‘save success - ‘, r) except: # 发生错误时回滚 print(‘ERROR - ‘, thread_id) # 关闭数据库连接 cursor.close() conn.close() # 保存每个楼层输入(只爬取贴子的第一页楼层数据) def save_thread_detail(thread_detail_id, thread_id, content, image, publish_date): # SQL 插入语句 sql = ‘insert into thread_detail_info(thread_detail_id, thread_id, content, image, publish_date) ‘ ‘value (%s, %s, %s, %s, %s )‘ try: conn = pymysql.connect( host=‘xx.xxx.xxx.xxx‘, # TODO:连接名 port=3306, # TODO:端口 user=‘xxx‘, # TODO:用户名 password=‘xxx!‘, # TODO:密码 charset=‘utf8‘, # 不能写utf-8 在MySQL里面写utf-8会报错 database=‘xxx‘, # TODO:数据库库名 cursorclass=DictCursor) # 使用cursor()方法获取操作游标 cursor = conn.cursor() # 执行sql语句 r = cursor.execute(sql, (thread_detail_id, thread_id, content, image, publish_date)) # 提交到数据库执行 conn.commit() print(‘save detail success - ‘, r) except: print(‘!!!!!!!save detail error:- ‘, thread_detail_id) # 关闭数据库连接 cursor.close() conn.close() # 将数据保存到txt文件 def savefile(data): for item in data: file.write(‘----------------------------------------\n‘) file.write(‘title:‘ + str(item[0]) + ‘\n‘) file.write(‘author:‘ + str(item[1]) + ‘\n‘) file.write(‘url:‘ + str(item[2]) + ‘\n‘) file.write(‘images:‘ + str(item[3]) + ‘\n‘) # 图片下载到本地/服务器 def saveImg(images): for img in images: img_data = requests.get(img, headers=header).content # 二进制数据用content image_name = img.split(‘/‘)[-1] with open(‘./tieba/‘ + image_name, ‘wb‘) as f: f.write(img_data) print(‘%s download img...‘ % image_name) if __name__ == ‘__main__‘: start = int(input("输入开始爬取贴吧的页码:")) end = int(input(‘输入结束爬取贴吧的页码(默认请输入0):‘)) end=end+1 if end !=0 else 3057000 + 1; spider(start,end, 50)
结局语:简单案例,仅供参考,适合python初学者。代码还有很多可优化的空间。有需要的人 或者有必要的话,后续会可能会更新。
标签:utf8 === write 错误 efi use code ict 用户
原文地址:https://www.cnblogs.com/chocolatexll/p/14071527.html