标签:exe 方式 call test begin inf exists mysq incr
原创 java金融 java金融 4月5日一般我们数据量大的时候,然后就需要进行分页,一般分页语句就是limit offset,rows。这种分页数据量小的时候是没啥影响的,一旦数据量越来越大随着offset的变大,性能就会越来越差。下面我们就来实验下:
准备数据
a. 建一个测试表引擎为MyISAM(插入数据没有事务提交,插入速度快)的表。
1. CREATE TABLE USER (
2. id INT ( 20 ) NOT NULL auto_increment,
3. NAME VARCHAR ( 20 ) NOT NULL,
4. address VARCHAR ( 20 ) NOT NULL,
5. PRIMARY KEY ( id )
6. ) ENGINE = MyISAM;2 . 写一个批量插入的存储过程
1. delimiter //
2. # 删除表数据
3. TRUNCATE TABLE t;
4. # 如果已经有sp_test_batch存储过程,将其删除,后面重新创建
5. DROP PROCEDURE IF EXISTS sp_test_batch;
6. # 创建存储过程,包含num和batch输入,num表示插入的总行数,batch表示每次插入的行数
7. CREATE PROCEDURE sp_test_batch(IN num INT,IN batch INT)
8. BEGIN
9. SET @insert_value = ‘‘;
10. # 已经插入的记录总行数
11. SET @count = 0;
12. #
13. SET @batch_count = 0;
14. WHILE @count < num DO
15. # 内while循环用于拼接INSERT INTO t VALUES (),(),(),...语句中VALUES后面部分
16. WHILE (@batch_count < batch AND @count < num) DO
17. IF @batch_count>0
18. THEN
19. SET @insert_value = concat(@insert_value,‘,‘);
20. END IF;
21. SET @insert_value = concat(@insert_value,"(‘name", @count, "‘,‘address", @count, "‘)");
22. SET @batch_count = @batch_count+1;
23. END WHILE;
24.
25. SET @count = @count + @batch_count;
26. # 拼接SQL语句并执行
27. SET @exesql = concat("insert into user(name,address) values ", @insert_value);
28. PREPARE stmt FROM @exesql;
29. EXECUTE stmt;
30. DEALLOCATE PREPARE stmt;
31. # 重置变量值
32. SET @insert_value = ‘‘;
33. SET @batch_count=0;
34. END WHILE;
35. # 数据插入完成后,查看表中总记录数
36. SELECT COUNT(id) FROM user;
37. END
38. CALL sp_test_batch(10000000,10000);插入1000w数据
3 . 测试性能
下面我们分别针对于offset等于不同的值来进行实:offset等于10000时耗时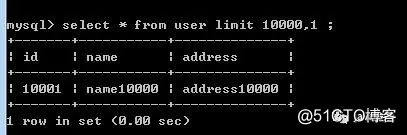
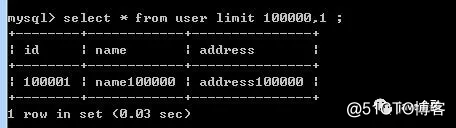
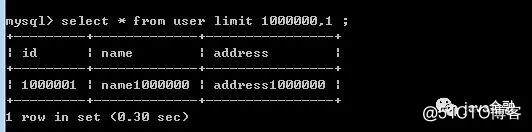


从上图可以得出随着offset的值越大耗时就越来越多。这还只是1000w数据,如果我们上亿数据呢,可想而知这时候查询的效率有多差。下面我们来进行优化。
4 .进行优化
子查询的分页方式:
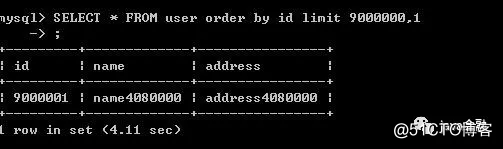
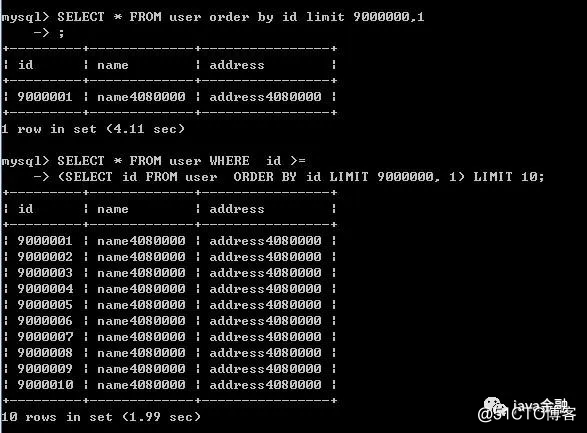
1.SELECT * FROM user WHERE id >=
2.(SELECT id FROM user ORDER BY id LIMIT 9000000, 1) LIMIT 10从图可以得出子查询确实速度快了一倍。
JOIN分页方式:
SELECT * FROM user t1 INNER join
(SELECT id FROM user ORDER BY id LIMIT 9000000, 10) t2 on t2.id =t1.id
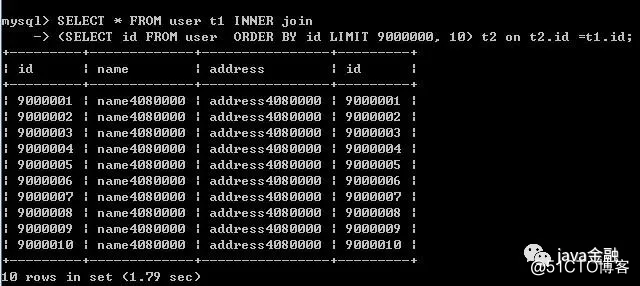
join的方式比子查询性能在稍微好点。
终极优化:
这个时间性能是最好的。这种优化必须要依赖前一次的查询的最大ID,如果是那种分页直接可以指定多少页的是不行的,必须是只能后一页,后一页这么点击。
1.SELECT id FROM user where id > 9000000 ORDER BY id LIMIT 10;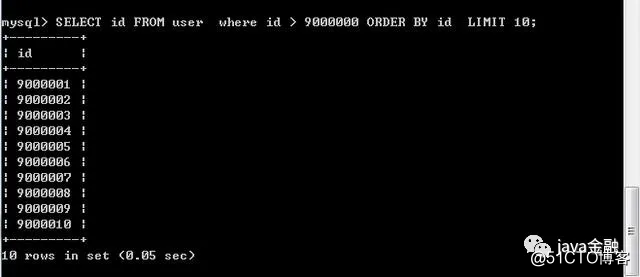
标签:exe 方式 call test begin inf exists mysq incr
原文地址:https://blog.51cto.com/14987832/2558042