标签:标记语言 可扩展 解释 order 格式 root 电子 子集 height
xml 是实现不通语言或程序之间进行数据交换的协议,可扩展标记语言,标准通用标记语言的子集。是一种用于标记电子文件使其具有结构性的标记语言。xml格式如下,是通过<>节点来区别数据结构的。xml在各种语言都是支持的。
如下
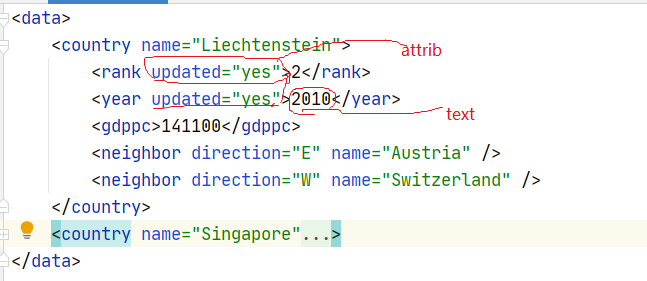
<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year updated="yes">2010</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year updated="yes">2013</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> </data>
1.xml文件读取
a.节点
import xml.etree.ElementTree as ET tree = ET.parse(‘test.xml‘) # parse 解析一个xml文件 root = tree.getroot() # 根节点 print(root) print(root.tag) for i in root: print(i.tag) # 子节点 for j in i: # 孙节点 print(j.tag)

b.attrib属性,text文本
import xml.etree.ElementTree as ET tree = ET.parse(‘test.xml‘) # parse 解析一个xml文件 root = tree.getroot() # 根节点 for i in root: for j in i: print(j.attrib) #属性 print(j.text) #文本

c.def iter(self, tag=None):-迭代器:
源码解释的是Create tree iterator.
The iterator loops over the element and all subelements in document
order, returning all elements with a matching tag.
就是迭代所有节点,找出tag对应的节点
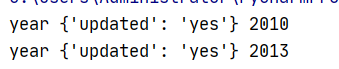
import xml.etree.ElementTree as ET tree = ET.parse(‘test.xml‘) root = tree.getroot() for i in root.iter("year"): # iter为所有节点,不传参为所有节点。传参寻找tag的节点 print(i.tag, i.attrib, i.text)
2.xml修改
import xml.etree.ElementTree as ET tree = ET.parse(‘test.xml‘) root = tree.getroot() for i in root.iter("year"): # iter为所有节点 print(type(i.text)) # text为str格式 ‘‘‘修改‘‘‘ new_year = int(i.text) + 1 # i.text = str(new_year) i.set(‘updated‘, ‘yes‘) # 原文提示是Set element attribute 设置属性 ‘‘‘tree已经修改,还需要写入xml文件‘‘‘ tree.write(‘test_new.xml‘)
3.xml删除
import xml.etree.ElementTree as ET tree = ET.parse(‘test.xml‘) root = tree.getroot() for i in root.findall(‘country‘):#"""Find all matching subelements by tag name or path. rank=i.find(‘rank‘).text rank=int(rank) if rank>1: root.remove(i) #只是tree修改了,还需要写入xml tree.write(‘test.xml‘)
4.用python写xml
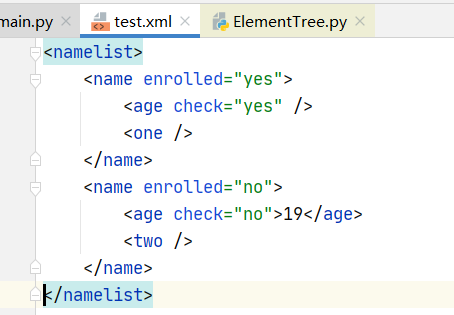
import xml.etree.ElementTree as ET new_xml=ET.Element(‘namelist‘) #根节点 name=ET.SubElement(new_xml,‘name‘,attrib={‘enrolled‘:‘yes‘}) #def SubElement(parent, tag, attrib={}, **extra): age=ET.SubElement(name,‘age‘,attrib={‘check‘:‘yes‘}) sex=ET.SubElement(name,‘one‘) name1=ET.SubElement(new_xml,‘name‘,attrib={‘enrolled‘:‘no‘}) #def SubElement(parent, tag, attrib={}, **extra): age=ET.SubElement(name1,‘age‘,attrib={‘check‘:‘no‘}) age.text=‘19‘ sex=ET.SubElement(name1,‘two‘) et=ET.ElementTree(new_xml)#生成文档对象 et.write(‘test.xml‘)
标签:标记语言 可扩展 解释 order 格式 root 电子 子集 height
原文地址:https://www.cnblogs.com/liaoyifu/p/14085134.html