标签:分发 定义 client 启动 角度 tor for map 默认值
本节将开始介绍Document API,本节将重点介绍ElasticSearch Doucment Index API(新增索引)。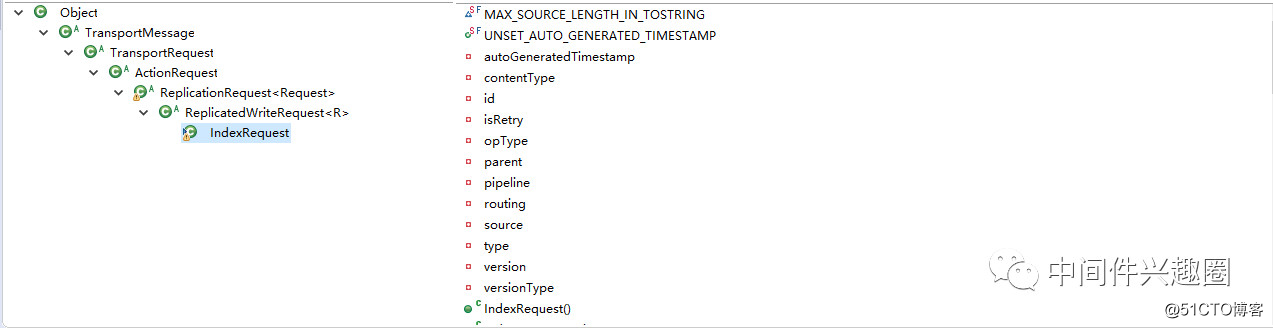
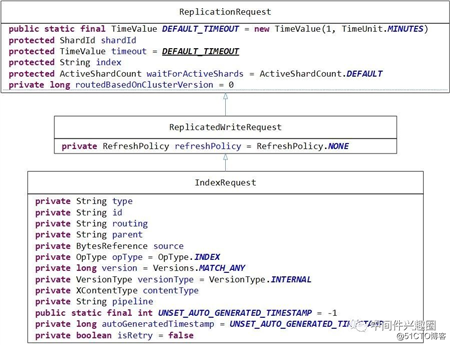

3、Index BytesReference source构造详解
下面是4中构建JSON document的4种形式:
String json = "{" +
"\"user\":\"kimchy\"," +
"\"postDate\":\"2013-01-30\"," +
"\"message\":\"trying out Elasticsearch\"" +
"}";
IndexResponse response = client.prepareIndex("twitter", "tweet")
.setSource(json, XContentType.JSON)
.get();3.2 Map
Map<String, Object> json = new HashMap<String, Object>();
json.put("user","kimchy");
json.put("postDate",new Date());
json.put("message","trying out Elasticsearch");
IndexResponse response = client.prepareIndex("twitter", "tweet")
.setSource(json)
.get();3.3 使用第三方类库
import com.fasterxml.jackson.databind.*;
// instance a json mapper
ObjectMapper mapper = new ObjectMapper(); // create once, reuse
// generate json
byte[] json = mapper.writeValueAsBytes(yourbeaninstance);
IndexResponse response = client.prepareIndex("twitter", "tweet")
.setSource(json, XContentType.JSON)
.get();3.4、使用ElasticSearch自带类库
import static org.elasticsearch.common.xcontent.XContentFactory.*;
IndexResponse response = client.prepareIndex("twitter", "tweet", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
.get();4、Index API使用Demo
Demo在单机版本的ElasticSearch服务器中运行。
package persistent.prestige.elasticsearchdemo;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
public class IndexApiDemo {
public static void main(String[] args) {
RestHighLevelClient client = EsClient.getClient();
try {
IndexRequest request = new IndexRequest();
request.index("twitter");
request.type("_doc");
request.id("1");
Map<String, String> source = new HashMap<>();
source.put("user", "dingw");
source.put("post_date", "2009-11-16T14:12:12");
source.put("message", "trying out Elasticsearch");
request.source(source);
try {
IndexResponse result = client.index(request, RequestOptions.DEFAULT);
System.out.println(result);
} catch (IOException e) {
e.printStackTrace();
}
} finally {
EsClient.close(client);
}
}
}运行结果如下:
{
"_shards" : {
"total" : 2,
"failed" : 0,
"successful" : 1
},
"_index" : "twitter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"result" : "created"
}接下来的内容将详细介绍Index API返回结果相关的扩展知识,让大家更加全面的了解Index API内部运行的机制。
5、Index API 内部实现机制
5.1 _shards 返回字段概述
_shards 结构体将反馈索引在副本级的复制信息。
注:索引操作成功的标志是successful大于0。当索引操作成功返回时,复制分片(副本)可能不会全部启动(默认情况下,只有主服务器是必需的,但是这种行为可以被更改)。
当前单机环境,total为2表示,一个分片存在1主一从,但同一个复制组内的分片不会分布在同一个机器上,故只启动了主分片,复制分片未启动;successful为1表示在主分片上已成功执行,failed为0表示没有执行失败的分片。
5.2 自动创建索引
使用Index API,如果索引不存在,则会自动创建对应的索引(类型映射类型为动态映射机制,具体关于字段映射,将会在Mapping章节中详细介绍)。Elasticsearch数据的组织形式为(index/type/document)。索引的管理(增删改查等API在后续文中会描述)。
自动索引创建可以通过配置来禁用。通过在所有节点的配置文件中添加action.auto_create_index=false来禁用。通过配置index.mapper.dynamic=false可以禁用索引的映射自动创建。配置是否禁用自动创建索引可基于模式的白名单/黑名单列表模式,例如action.auto_create_index=aaa,-bbb,+ccc,- 分别代表 aaa开头的索引自动创建,bbb开头的索引禁止自动创建,禁用索引自动创建。
5.3 版本工作机制
每个索引文档都有一个版本号。关联的版本号作为对索引API请求的响应的一部分返回。索引请求如果指定了版本号这个参数(IndexRequest#version)时,索引API可选择性地允许乐观并发控制机制,所谓乐观并发控制就是如果待操作的索引文档的版本号如果与IndexRequest#version版本不相同,则本次操作失败。版本控制完全是实时的,如果未提供版本,则无需验证版本信息而立即执行。
默认情况下使用内部版本控制,从1开始,每次更新自增1,(包含删除)。可选地,版本号可以用外部值来补充(例如,如果在数据库中维护)。为了启用这个功能,IndexRequest#versionType应该被设置为外部(VersionType.EXTERNAL或VersionType.EXTERNAL_GTE)。外部版本号的取值范围为[0,9.2 e+18)。如果使用外部版本号,系统会检查传递给索引请求的版本号是否大于当前存储文档的版本号,而不是检查匹配的版本号。如果所提供的值小于或等于存储文档的版本号,则会出现版本冲突,索引操作将失败。
警告:外部版本控制支持0作为有效版本号。这允许版本与外部版本控制系统同步,其中版本号从0开始,而不是1。它有一个副作用,即版本号为零的文档不能使用更新的查询API进行更新,也不能使用查询API的Delete来删除,只要它们的版本号等于零。
外部版本号一个最佳实践,使用源数据库中数据的版本号,就不需要维护对源数据库的更改所执行的异步索引操作的严格排序。即使使用来自数据库的数据来更新Elasticsearch索引的简单情况,如果使用外部版本控制,也会简化,因为如果索引操作出于某种原因而不正常,则只使用最新的版本即可。
5.4 版本类型
ElasticSearch支持如下版本类型:
5.6 自动ID生成
索引动作可以不指定文档ID,ElasticSearch会自动创建ID,此时的opType属性会自动设置为OpType.CREATE。其Restfull请求又原先的PUT变更为POST,当然我们在使用Rest Hign Level API时无需关注restfull请求类型,都是通过index方法发生调用,内部会自动封装相应的http请求。
5.7 路由
默认情况下,路由字段是通过使用文档的id值的散列来控制的,其路由算法(hash(路由字段) % (primary count))来定位所在的主分片(复制组)。ElasticSearch提供了显示指定路由字段的方法,通过routing来指定路由值,索引API通过IndexRequest#routing()方法来指定路由值。
当设置显式映射(Mapping)时,可以选择使用路由字段来指导索引操作从文档本身提取路由值。如果路由映射被定义并设置为required,那么如果没有提供或提取路由值,则索引操作将失败。
5.8 分布式
索引操作首先根据路由规则将请求转发到主分片,并在包含此分片的的实际节点上执行。在主分片完成操作之后,如果需要,更新将被分发到对应复制组中的副本所在的节点上执行。其执行逻辑已在上篇《Elasticsearch Document API之文档读写概要设计》中写模型一节中详细介绍,在此不重复介绍。
5.9 等待活动的分片数(Wait For Active Shards )
为了提高对系统写操作的弹性,引入了(wait for active shards)机制,就是在进行索引操作之前,先校验当前活跃的分片(副本数量),如果当前的激活分片数量不足,则先等待更多的分片启动直到有新的分片加入或等待超时。默认情况下,写操作只需等待主分片处于激活状态即可(即wait_for_active_shards=1、请求参数waitForActiveShards=1)。这个默认值可以通过设置索引的配置(Setting)index.write.wait_for_active_shards来动态改变。同样也可以通过请求参数IndexRequest#waitForActiveShards(waitForActiveShards)来动态改变。
wait_for_active_shards的数据类型为正整数,取值范围为[1,number_of_replicas+1]。
例如,假设我们有一个由三个节点组成的集群,A、B和C,我们创建一个索引,其中的副本数量(number_of_replicas)设置为3(3个副本+1个主分片,比节点数量多一个)。如果我们尝试索引操作,默认情况下,只要主节点处于激活,则索引操作会在主节点上执行,然后转发到其他复制组。这意味着,即使B和C宕机(主分片在A节点上),索引操作仍然会在主分片上执行。如果wait_for_active_shards设置为3(并且所有3个节点都正常),索引操作能继续执行而无需等待,因为集群中有3个活动节点,每个节点都持有分片的副本。但是,如果我们将wait_for_active_shards设置为all或4,索引操作将不会继续,陷入等待,因为我们目前集群中没有4个副本。除非集群中出现一个新的节点来承载第4个副本,否则该操作将超时。
需要注意的是,这种设置大大减少了不必要的写操作(能避免无谓的写处理,如果分片数量不足,则不执行索引动作),但是它并没有完全消除这种可能性,因为这种检查发生在写操作开始之前。一旦写操作开始,复制在任意数量的碎片副本上仍然可能失败,但是在主服务器上仍然成功。写操作响应的分片部分(5.1节所示)揭示了复制成功/失败的分片副本的数量,数据在主分片、副本之间数据的最终一致性处理在《Elasticsearch Document API之文档读写概要设计》写模型异常处理部分有相应的处理机制。
ActiveShardCount取值常量说明:
5.10 刷新机制
Index API 、Update API、Delete API、Bulk API都支持RefreshPolicy设置刷新策略(private RefreshPolicy refreshPolicy),以便控制上述API所产生的变化对查询API的可见性策略。其可选值如下:
空字符串或true(RefreshPolicy.IMMEDIATE)
在操作(index,update,delete)发生之后,立即刷新相关的主分片与复制分片(不是刷新整个索引,只是刷新发生变化的文档)。目前从索引与查询的角度来看,他不会导致性能低下。
false(RefreshPolicy.NONE)
在操作(index,update,delete)执行完毕后,直接返回,而不执行刷新,而是依靠Elasticsearch的刷新机制。
5.11 超时
当执行索引操作时,主分片所在的节点可能不可用。造成这种情况的一些原因可能是,主分片目前正在从网关中恢复或正在进行重新安置。默认情况下,索引操作将在主上等待最多1分钟,然后失败并以错误响应。超时参数可以用来显式地指定它等待多长时间,可通过IndexRequest#timeout(timeout)方法设置,或通过?timeout=5m设置。
总结:本文首先罗列了Elasticsearch Index API, 然后详细介绍了其API两个核心的对象(IndexRequest与RequestOptions),接着通过示例演示了RestHighLevelClient index API的使用,最后深入分析了Index API的一些内在处理机制。后续会更深一步从源码角度深度剖析其实现细节。
关注《中间件兴趣圈》公众号,查看更多关于中间件相关的文章:
Elasticsearch Document Index API详解、原理与示例
标签:分发 定义 client 启动 角度 tor for map 默认值
原文地址:https://blog.51cto.com/15023237/2559627