标签:内存 例子 特殊 指令 另一个 顺序 规则 多线程程序 alt
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排。
为什么指令重排序可以提高性能?
简单地说,每一个指令都会包含多个步骤,每个步骤可能使用不同的硬件。因此,流水线技术产生了,它的原理是指令1还没有执行完,就可以开始执行指令2,而不用等到指令1执行结束之后再执行指令2,这样就大大提高了效率。
但是,流水线技术最害怕中断,恢复中断的代价是比较大的,所以我们要想尽办法不让流水线中断。指令重排就是减少中断的一种技术。
我们分析一下下面这个代码的执行情况:
a = b + c;
d = e - f ;
先加载b、c(注意,即有可能先加载b,也有可能先加载c),但是在执行add(b,c)的时候,需要等待b、c装载结束才能继续执行,也就是增加了停顿,那么后面的指令也会依次有停顿,这降低了计算机的执行效率。
为了减少这个停顿,我们可以先加载e和f,然后再去加载add(b,c),这样做对程序(串行)是没有影响的,但却减少了停顿。既然add(b,c)需要停顿,那还不如去做一些有意义的事情。
综上所述,指令重排对于提高CPU处理性能十分必要。虽然由此带来了乱序的问题,但是这点牺牲是值得的。
指令重排一般分为以下三种:
编译器优化重排
编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
指令并行重排
现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
内存系统重排
由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。所以在多线程下,指令重排序可能会导致一些问题。
顺序一致性模型是一个理论参考模型,内存模型在设计的时候都会以顺序一致性内存模型作为参考。
当程序未正确同步的时候,就可能存在数据竞争。
数据竞争:在一个线程中写一个变量,在另一个线程读同一个变量,并且写和读没有通过同步来排序。
如果程序中包含了数据竞争,那么运行的结果往往充满了不确定性,比如读发生在了写之前,可能就会读到错误的值;如果一个线程程序能够正确同步,那么就不存在数据竞争。
Java内存模型(JMM)对于正确同步多线程程序的内存一致性做了以下保证:
如果程序是正确同步的,程序的执行将具有顺序一致性。 即程序的执行结果和该程序在顺序一致性模型中执行的结果相同。
这里的同步包括了使用volatile、final、synchronized等关键字来实现多线程下的同步。
如果程序员没有正确使用volatile、final、synchronized,那么即便是使用了同步(单线程下的同步),JMM也不会有内存可见性的保证,可能会导致你的程序出错,并且具有不可重现性,很难排查。
所以如何正确使用volatile、final、synchronized,是程序员应该去了解的。后面会有专门的章节介绍这几个关键字的内存语义及使用。
顺序一致性内存模型是一个理想化的理论参考模型,它为程序员提供了极强的内存可见性保证。
顺序一致性模型有两大特性:
为了理解这两个特性,我们举个例子,假设有两个线程A和B并发执行,线程A有3个操作,他们在程序中的顺序是A1->A2->A3,线程B也有3个操作,B1->B2->B3。
假设正确使用了同步,A线程的3个操作执行后释放锁,B线程获取同一个锁。那么在顺序一致性模型中的执行效果如下所示:
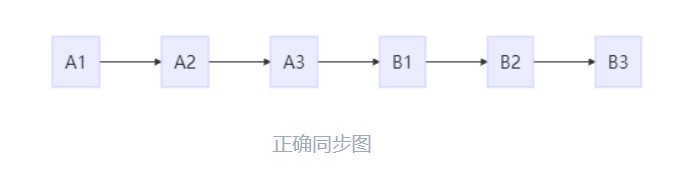
正确同步图
操作的执行整体上有序,并且两个线程都只能看到这个执行顺序。
假设没有使用同步,那么在顺序一致性模型中的执行效果如下所示:
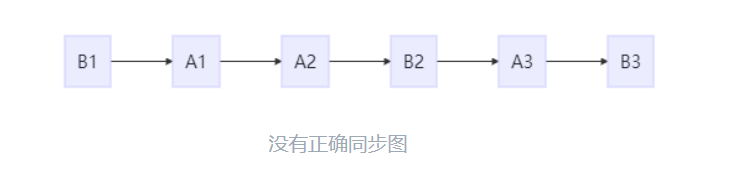
没有正确同步图
操作的执行整体上无序,但是两个线程都只能看到这个执行顺序。之所以可以得到这个保证,是因为顺序一致性模型中的每个操作必须立即对任意线程可见。
但是JMM没有这样的保证。
比如,在当前线程把写过的数据缓存在本地内存中,在没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,这个写操作根本没有被当前线程所执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才对其他线程可见。在这种情况下,当前线程和其他线程看到的执行顺序是不一样的。
在顺序一致性模型中,所有操作完全按照程序的顺序串行执行。但是JMM中,临界区内(同步块或同步方法中)的代码可以发生重排序(但不允许临界区内的代码“逃逸”到临界区之外,因为会破坏锁的内存语义)。
虽然线程A在临界区做了重排序,但是因为锁的特性,线程B无法观察到线程A在临界区的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
同时,JMM会在退出临界区和进入临界区做特殊的处理,使得在临界区内程序获得与顺序一致性模型相同的内存视图。
由此可见,JMM的具体实现方针是:在不改变(正确同步的)程序执行结果的前提下,尽量为编译期和处理器的优化打开方便之门。
对于未同步的多线程程序,JMM只提供最小安全性:线程读取到的值,要么是之前某个线程写入的值,要么是默认值,不会无中生有。
为了实现这个安全性,JVM在堆上分配对象时,首先会对内存空间清零,然后才会在上面分配对象(这两个操作是同步的)。
JMM没有保证未同步程序的执行结果与该程序在顺序一致性中执行结果一致。因为如果要保证执行结果一致,那么JMM需要禁止大量的优化,对程序的执行性能会产生很大的影响。
未同步程序在JMM和顺序一致性内存模型中的执行特性有如下差异: 1. 顺序一致性保证单线程内的操作会按程序的顺序执行;JMM不保证单线程内的操作会按程序的顺序执行。(因为重排序,但是JMM保证单线程下的重排序不影响执行结果) 2. 顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而JMM不保证所有线程能看到一致的操作执行顺序。(因为JMM不保证所有操作立即可见) 3. JMM不保证对64位的long型和double型变量的写操作具有原子性,而顺序一致性模型保证对所有的内存读写操作都具有原子性。
一方面,程序员需要JMM提供一个强的内存模型来编写代码;另一方面,编译器和处理器希望JMM对它们的束缚越少越好,这样它们就可以最可能多的做优化来提高性能,希望的是一个弱的内存模型。
JMM考虑了这两种需求,并且找到了平衡点,对编译器和处理器来说,只要不改变程序的执行结果(单线程程序和正确同步了的多线程程序),编译器和处理器怎么优化都行。
而对于程序员,JMM提供了happens-before规则(JSR-133规范),满足了程序员的需求——简单易懂,并且提供了足够强的内存可见性保证。换言之,程序员只要遵循happens-before规则,那他写的程序就能保证在JMM中具有强的内存可见性。
JMM使用happens-before的概念来定制两个操作之间的执行顺序。这两个操作可以在一个线程以内,也可以是不同的线程之间。因此,JMM可以通过happens-before关系向程序员提供跨线程的内存可见性保证。
happens-before关系的定义如下: 1. 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。 2. 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么JMM也允许这样的重排序。
happens-before关系本质上和as-if-serial语义是一回事。
as-if-serial语义保证单线程内重排序后的执行结果和程序代码本身应有的结果是一致的,happens-before关系保证正确同步的多线程程序的执行结果不被重排序改变。
总之,如果操作A happens-before操作B,那么操作A在内存上所做的操作对操作B都是可见的,不管它们在不在一个线程。
在Java中,有以下天然的happens-before关系:
举例:
int a = 1; // A操作
int b = 2; // B操作
int sum = a + b;// C 操作
System.out.println(sum);
根据以上介绍的happens-before规则,假如只有一个线程,那么不难得出:
1> A happens-before B
2> B happens-before C
3> A happens-before C
注意,真正在执行指令的时候,其实JVM有可能对操作A & B进行重排序,因为无论先执行A还是B,他们都对对方是可见的,并且不影响执行结果。
如果这里发生了重排序,这在视觉上违背了happens-before原则,但是JMM是允许这样的重排序的。
所以,我们只关心happens-before规则,不用关心JVM到底是怎样执行的。只要确定操作A happens-before操作B就行了。
重排序有两类,JMM对这两类重排序有不同的策略:
标签:内存 例子 特殊 指令 另一个 顺序 规则 多线程程序 alt
原文地址:https://www.cnblogs.com/chenyameng/p/14099350.html