标签:otf 技术 lazy 图片 get min 验证码 下载文件 环境变量
在使用Python做自动化时候遇到登录需要识别验证码问题,此时采用pytesseract模块,遇到异常:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it‘s not in your PATH. See README file for more information.
解决方式:
1、下载对应版本的“Tesseract-OCR”,下载地址:https://github.com/tesseract-ocr/tesseract/wiki 或者 https://github.com/UB-Mannheim/tesseract/wiki
下载文件名称:tesseract-ocr-w64-setup-v5.0.0-alpha.20201127.exe
2、安装Tesseract-OCR,请记住安装路径。
3、配置环境变量:
(1)配置Tesseract-OCR环境变量:
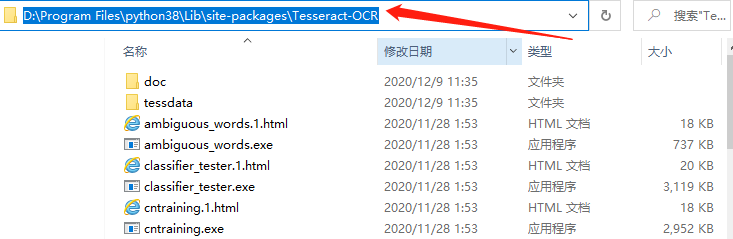
将Tesseract-OCR的安装路径配置在环境变量Path中。D:\Program Files\python38\Lib\site-packages\Tesseract-OCR 。如下图:
(2)配置tessdata环境变量:
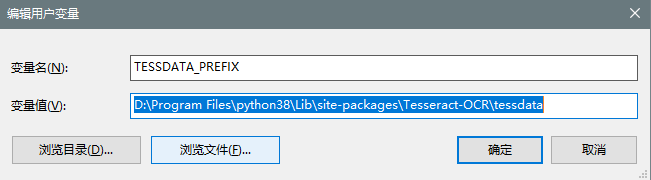
新增一个变量名:TESSDATA_PREFIX。变量值为安装的Tesseract-OCR路径下的tessdata的路径。即,在Tesseract-OCR的安装路径后追加tessdata。D:\Program Files\python38\Lib\site-packages\Tesseract-OCR\tessdata。如下图
4、然后将pytesseract.py源码中
tesseract_cmd = ‘tesseract‘
修改为:
tesseract_cmd = r‘D:\Program Files\python38\Lib\site-packages\Tesseract-OCR\tesseract.exe‘
重新运行脚本,OK
如下图所示的登录页面。
附带识别验证码代码:
from selenium import webdriver from PIL import Image import pytesseract def readvcode(): dr = webdriver.Chrome("D:\softwarePro\BrowserDriver\chromedriver.exe") dr.maximize_window() dr.get("http://192.168.2.211:8090/smartcommty/index") dr.save_screenshot(‘All.png‘) # 截取当前网页,该网页有我们需要的验证码 imgelement = dr.find_element_by_class_name(‘imgcode‘) location = imgelement.location # 获取验证码x,y轴坐标 size = imgelement.size # 获取验证码的长宽 rangle = (int(location[‘x‘]), int(location[‘y‘]), int(location[‘x‘] + size[‘width‘]), int(location[‘y‘] + size[‘height‘])) # 写成我们需要截取的位置坐标 i = Image.open("All.png") # 打开截图 result = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域 result.save(‘result.png‘) text = pytesseract.image_to_string(‘result.png‘, ‘eng‘).strip() dr.find_element_by_name("username").send_keys("admin") dr.find_element_by_name("password").send_keys("admin123") dr.find_element_by_name("validateCode").send_keys(text) dr.find_element_by_id("btnSubmit").click() if __name__ == ‘__main__‘: readvcode()
带有噪点或者划线类的验证码以后更新。
标签:otf 技术 lazy 图片 get min 验证码 下载文件 环境变量
原文地址:https://www.cnblogs.com/deliaries/p/14108540.html