标签:地方 记录 home 插件 record AAT lib 有用 文件系统
0、题记实际业务场景中,会遇到基础数据存在Mysql中,实时写入数据量比较大的情景。迁移至kafka是一种比较好的业务选型方案。
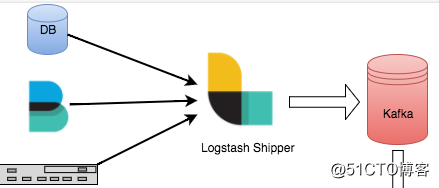
而mysql写入kafka的选型方案有:
方案一:logstash_output_kafka 插件。
方案二:kafka_connector。
方案三:debezium 插件。
方案四:flume。
方案五:其他类似方案。
其中:debezium和flume是基于mysql binlog实现的。
如果需要同步历史全量数据+实时更新数据,建议使用logstash。
常用的logstash的插件是:logstash_input_jdbc实现关系型数据库到Elasticsearch等的同步。
实际上,核心logstash的同步原理的掌握,有助于大家理解类似的各种库之间的同步。
logstash核心原理:输入生成事件,过滤器修改它们,输出将它们发送到其他地方。
logstash核心三部分组成:input、filter、output。
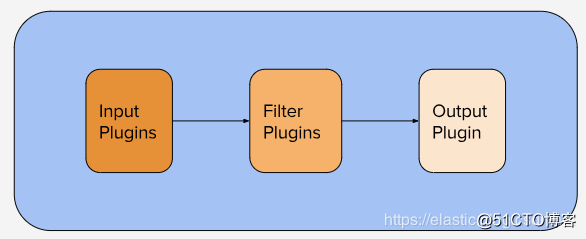
input { }
filter { }
output { }包含但远不限于:
过滤器是Logstash管道中的中间处理设备。您可以将过滤器与条件组合,以便在事件满足特定条件时对其执行操作。
可以把它比作数据处理的ETL环节。
一些有用的过滤包括:
输出是Logstash管道的最后阶段。一些常用的输出包括:
elasticsearch:将事件数据发送到Elasticsearch。
file:将事件数据写入磁盘上的文件。
kafka:将事件写入Kafka。
详细的filter demo参考:http://t.cn/EaAt4zP
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.1.12:3306/news_base"
jdbc_user => "root"
jdbc_password => "xxxxxxx"
jdbc_driver_library => "/home/logstash-6.4.0/lib/mysql-connector-java-5.1.47.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
#schedule => "* * * * *"
statement => "SELECT * from news_info WHERE id > :sql_last_value order by id"
use_column_value => true
tracking_column => "id"
tracking_column_type => "numeric"
record_last_run => true
last_run_metadata_path => "/home/logstash-6.4.0/sync_data/news_last_run"
}
}
filter {
ruby{
code => "event.set(‘gather_time_unix‘,event.get(‘gather_time‘).to_i*1000)"
}
ruby{
code => "event.set(‘publish_time_unix‘,event.get(‘publish_time‘).to_i*1000)"
}
mutate {
remove_field => [ "@version" ]
remove_field => [ "@timestamp" ]
remove_field => [ "gather_time" ]
remove_field => [ "publish_time" ]
}
}
output {
kafka {
bootstrap_servers => "192.168.1.13:9092"
codec => json_lines
topic_id => "mytopic"
}
file {
codec => json_lines
path => "/tmp/output_a.log"
}
}以上内容不复杂,不做细讲。
注意:
Mysql借助logstash同步后,日期类型格式:“2019-04-20 13:55:53”已经被识别为日期格式。
code =>
"event.set(‘gather_time_unix‘,event.get(‘gather_time‘).to_i*1000)",
是将Mysql中的时间格式转化为时间戳格式。
from星友:使用logstash同步mysql数据的,因为在jdbc.conf里面没有添加 lowercase_column_names
=> "false" 这个属性,所以logstash默认把查询结果的列明改为了小写,同步进了es,所以就导致es里面看到的字段名称全是小写。
最后总结:es是支持大写字段名称的,问题出在logstash没用好,需要在同步配置中加上 lowercase_column_names => "false" 。记录下来希望可以帮到更多人。
想将关系数据库的数据同步至ES中,如果在集群的多台服务器上同时启动logstash。
解读:实际项目中就是没用随机id 使用指定id作为es的_id ,指定id可以是url的md5.这样相同数据就会走更新覆盖以前数据
解读:高版本基于时间增量有优化。
tracking_column_type => "timestamp"应该是需要指定标识为时间类型,默认为数字类型numeric
解读:可以logstash同步mysql的时候sql查询阶段处理,如:select a_value as avalue***。
或者filter阶段处理,mutate rename处理。
mutate {
rename => ["shortHostname", "hostname" ]
}或者kafka阶段借助kafka stream处理。
推荐阅读:
1、实战 | canal 实现Mysql到Elasticsearch实时增量同步
2、干货 | Debezium实现Mysql到Elasticsearch高效实时同步
3、一张图理清楚关系型数据库与Elasticsearch同步 http://t.cn/EaAceD3
4、新的实现:http://t.cn/EaAt60O
5、mysql2mysql: http://t.cn/EaAtK7r
6、推荐开源实现:http://t.cn/EaAtjqN
加入星球,更短时间更快习得更多干货!
logstash_output_kafka:Mysql同步Kafka深入详解
标签:地方 记录 home 插件 record AAT lib 有用 文件系统
原文地址:https://blog.51cto.com/15050720/2562057