标签:ODB 快速 直接 mysq 种类 tiny 约束 nbsp 分区
多个层面思考,优化性能
存储层:存储引擎、字段类型选择、范式设计
设计层:索引、缓存、分区(分表)
架构层:多个mysql服务器设置,读写分离(主从模式)
sql语句层:多个sql语句都可以达到目的的情况下,要选择性能高、速度快的sql语句
show engine/G; 显示数据库的使用引擎
1.存储引擎: Myisam 和 innoDb
innodb:
数据库每个数据表的数据设计三方面信息:表结构、数据、索引
技术特点:支持事务、行级锁定、外键
并发性
该类型表的并发性非常高
多人同时操作该数据表
为了操作数据表的时候,数据内容不会随便发生变化,
要对信息进行“锁定” 该类型锁定级别为:行锁。
只锁定被操作的当前记录。
Myisam:
结构、数据、索引独立存储
技术特点:表级锁定、读写效率高
并发性
该类型并发性较低
该类型的锁定级别为:表锁
网站大多数情况下“读和写”操作非常多,适合选择Myisam类型
网站对业务逻辑有一定要求(办公网站、商城)适合选择innodb
2.字段类型选择
2.1 尽量少的占据存储空间
int(3) 表示可以存放3个长度 如123 如果插入1234 侧会显示长度超出显示
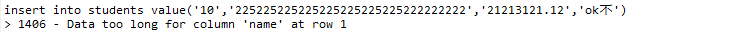
设置name长度为32
CHAR、VARCAHR的长度是指字符的长度
TINYINT、SMALLINT、MEDIUMINT、INT和BIGINT的长度,其实和数据的大小无关!Length指的是显示宽度
例如 int(3)可以存放10亿

一个字节 等于8个位 位就是存储0和1数值
1B=8b;
1k =1024B;
int(3)可以存放1000000000
长度 M 与你存放的数值型的数的大小无关
3.表优化:设计符合三范式,
① 一范式:原子性,数据不可以再分割
② 二范式:数据没有冗余
③ 三范式 数据表每个字段与当前表的主键产生直接关联(非间接关联)
4.索引优化
有了索引,我们根据索引为条件进行数据查询速度就非常快
① 索引本身有”算法”支持,可以快速定位我们要找到的关键字(字段)
② 索引字段与物理地址有直接对应,帮助我们快速定位要找到的信息
索引类型
四种类型:
① 主键 primary key auto_increment必须给主键索引设置 信息内容要求不能为null,唯一
② 唯一 unique index 信息内容不能重复
③ 普通 index 没有具体要求
④ 全文 fulltext index myisam数据表可以设置该索引
复合索引:索引关联的字段是多个组成的,该索引就是复合索引。
执行explain
explain 查询sql语句\G;
索引适合场景:
1) where查询条件
where 之后设置的查询条件字段都适合做索引。
2) 排序查询 order by 字段 //排序字段适合做索引
排序字段没有索引,做排序查询就没有使用:
3) 连接查询(约束字段)
4) OR左右的关联条件必须都具备索引 才可以使用索引:
5)左原则
模糊查询,like % _
%:关联多个模糊内容
_: 关联一个模糊内容
select * from 表名 like “beijing%”; //使用索引 select * from 表名 like “beijing_”;//索引索引
查询条件信息在左边出现,就给使用索引 XXX% YYY_ 使用索引
%AAA% _ABC_ %UUU 不使用索引
标签:ODB 快速 直接 mysq 种类 tiny 约束 nbsp 分区
原文地址:https://www.cnblogs.com/kevin-yang123/p/14132268.html