标签:响应 情况 定义 计算 不同 obj 体系结构 方案 频繁
传统的数据库管理系统把所有数据都放在磁盘上进行管理,所以称做磁盘数据库(DRDB:Disk-Resident Database)。磁盘数据库需要频繁地访问磁盘来进行数据的操作,由于对磁盘读写数据的操作一方面要进行磁头的机械移动,另一方面受到系统调用(通常通过CPU中断完成,受到CPU时钟周期的制约)时间的影响,当数据量很大,操作频繁且复杂时,就会暴露出很多问题。
近年来,内存容量不断提高,价格不断下跌,操作系统已经可以支持更大的地址空间(计算机进入了64位时代),同时对数据库系统实时响应能力要求日益提高,充分利用内存技术提升数据库性能成为一个热点。
在数据库技术中,目前主要有两种方法来使用大量的内存。一种是在传统的数据库中,增大缓冲池,将一个事务所涉及的数据都放在缓冲池中,组织成相应的数据结构来进行查询和更新处理,也就是常说的共享内存技术,这种方法优化的主要目标是最小化磁盘访问。另一种就是内存数据库(MMDB:Main Memory Database,也叫主存数据库)技术,就是干脆重新设计一种数据库管理系统,对查询处理、并发控制与恢复的算法和数据结构进行重新设计,以更有效地使用CPU周期和内存,这种技术近乎把整个数据库放进内存中,因而会产生一些根本性的变化。
内存数据库系统带来的优越性能不仅仅在于对内存读写比对磁盘读写快上,更重要的是,从根本上抛弃了磁盘数据管理的许多传统方式,基于全部数据都在内存中管理进行了新的体系结构的设计,并且在数据缓存、快速算法、并行操作方面也进行了相应的改进,从而使数据处理速度一般比传统数据库的数据处理速度快很多,一般都在10倍以上,理想情况甚至可以达到1000倍。
而使用共享内存技术的实时系统和使用内存数据库相比有很多不足,由于优化的目标仍然集中在最小化磁盘访问上,很难满足完整的数据库管理的要求,设计的非标准化和软件的专用性造成可伸缩性、可用性和系统的效率都非常低,对于快速部署和简化维护都是不利的。
从上个世纪60年代末到80年代初。在这个时期中,出现了主存数据库的雏形。1969年IBM公司研制了世界上最早的数据库管理系统——基于层次模型的数据库管理系统IMS,并作为商品化软件投入市场。在设计IMS时,IBM考虑到基于内存的数据管理方法,相应推出了IMS/VS Fast Path。Fast Path是一个支持内存驻留数据的商业化数据库,但它同时也可以很好地支持磁盘驻留数据。在这个产品中体现了主存数据库的主要设计思想,也就是将需要频繁访问,要求高响应速度的数据直接存放在物理内存中访问和管理。在这个阶段中,包括网状数据库、关系数据库等其他各种数据库技术也都逐渐成型。
1984年,D J DeWitt等人发表了《主存数据库系统的实现技术》一文。第一次提出了Main Memory Database(主存数据库)的概念。预言当时异常昂贵的计算机主存价格一定会下降,用户有可能将大容量的数据库全部保存在主存中,提出了AVL树、哈希算法、主存数据库恢复机制等主存数据库技术的关键理论,为主存数据库的发展指出了明确的方向 。
1984年,D J DeWitt等人提出使用非易逝内存或预提交和成组提交技术作为主存数据库的提交处理方案,使用指针实现主存数据库的存取访问。
1985年,IBM推出了IBM 370上运行的OBE主存数据库。
1986年,RB Hagman提出了使用检查点技术实现主存数据库的恢复机制。威斯康星大学提出了按区双向锁定模式解决主存数据库中的并发控制问题。并设计出MM-DBMS主存数据库。贝尔实验室推出了DALI主存数据库模型。
1987年,ACM SIGMOD会议中提出了以堆文件(HEAP FILE)作为主存数据库的数据存储结构。Southern Methodist大学设计出MARS主存数据库模型。
1988年普林斯顿大学设计出TPK主存数据库。
1990年普林斯顿大学又设计出System M主存数据库。
随着互联网的发展,越来越多的网络应用系统需要能够支持大用户量并发访问、高响应速度的的数据库系统,主存数据库市场成熟
半导体技术快速发展,半导体内存大规模生产,动态随机存取存储器(DRAM)的容量越来越大,而价格越来越低,这无疑为计算机内存的不断扩大提供了硬件基础,使得主存数据库的技术可行性逐步成熟
1994年美国OSE公司推出了第一个商业化的,开始实际应用的主存数据库产品Polyhedra
1998年德国SoftwareAG推出了Tamino Database。
1999年日本UBIT会社开发出XDB主存数据库产品。韩国Altibase推出Altibase。
2000年奥地利的QuiLogic公司推出了SQL-IMDB。
2001年美国McObject推出eXtremeDB。加拿大Empress公司推出EmpressDB。
第一代:用户定制的主存数据库。通过应用程序来管理内存和数据;不支持SQL语句, 不提供本地存储, 没有数据库恢复技术;性能好但很难维护和在别的应用中不能使用;应用在实时领域比如工厂自动化生产。
第二代:简单功能的内存数据库。能够快速处理简单的查询;支持部分的 SQL语句和简单的恢复技术;主要目的是能够快速处理大量事务;针对简单事务处理领域,尤其是交换机, 移动通信等。
第三代:通用的主存数据库。针对传统的商业关系型数据库领域,能够提供更高的性能、通用性以及稳定性;提供不同的接口来处理复杂的SQL语句和满足不同的应用领域;可以应用在计费、电子商务、在线安全领域,几乎包括磁盘数据库的所有应用领域。
Memcached是一个自由开源的,高性能,分布式内存对象缓存系统。
Memcached是以LiveJournal旗下Danga Interactive公司的Brad Fitzpatric为首开发的一款软件。现在已成为mixi、hatena、Facebook、Vox、LiveJournal等众多服务中提高Web应用扩展性的重要因素。
Memcached是一种基于内存的key-value存储,用来存储小块的任意数据(字符串、对象)。这些数据可以是数据库调用、API调用或者是页面渲染的结果。
Memcached简洁而强大。它的简洁设计便于快速开发,减轻开发难度,解决了大数据量缓存的很多问题。它的API兼容大部分流行的开发语言。
本质上,它是一个简洁的key-value存储系统。
一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web应用的速度、提高可扩展性。
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
Tair是由淘宝网自主开发的Key/Value结构数据存储系统,在淘宝网有着大规模的应用。您在登录淘宝、查看商品详情页面或者在淘江湖和好友“捣浆糊”的时候,都在直接或间接地和Tair交互。
Tair是一个Key/Value结构数据的解决方案,它默认支持基于内存和文件的两种存储方式,分别和我们通常所说的缓存和持久化存储对应。
Tair除了普通Key/Value系统提供的功能,比如get、put、delete以及批量接口外,还有一些附加的实用功能,使得其有更广的适用场景。
5.4、测试
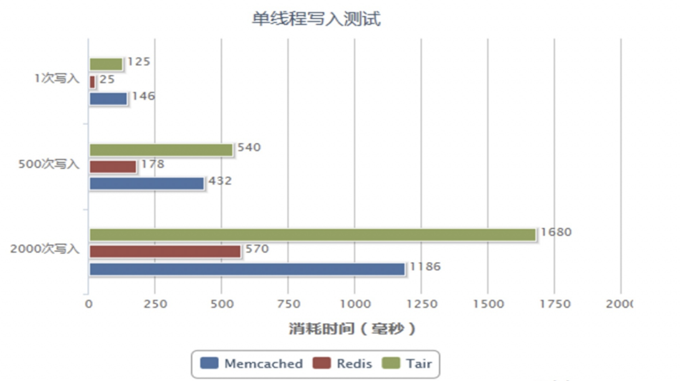
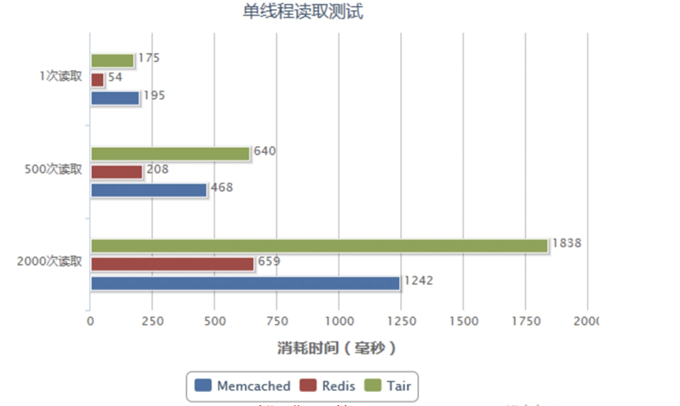
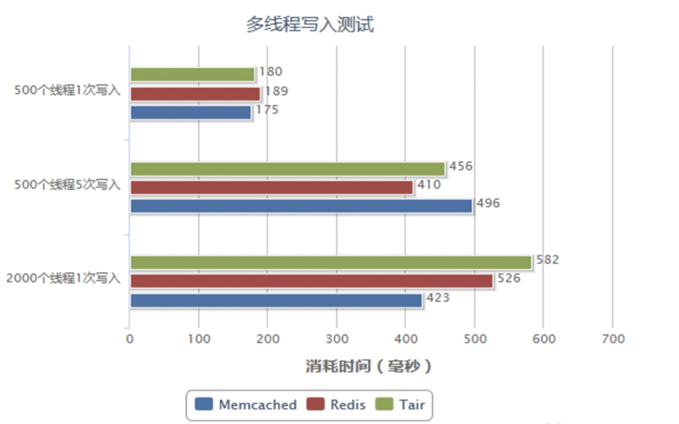
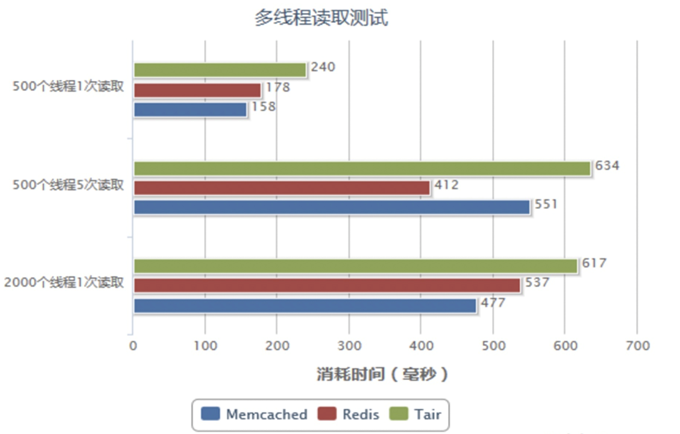
Memcached:多核的缓存服务,更加适合于多用户并发访问次数(访问次数较少的应用场景)。
Redis:单核缓存服务,在单节点情况下,更加适合少量用户,多次访问的应用场景。
Memcached:多核的缓存服务,更加适合于多用户并发访问次数(访问次数较少的应用场景)。
Redis:单核缓存服务,在单节点情况下,更加适合少量用户,多次访问的应用场景。
标签:响应 情况 定义 计算 不同 obj 体系结构 方案 频繁
原文地址:https://www.cnblogs.com/zyc99/p/14151469.html