标签:高性能 存储 online 建模 htm line 过拟合 http 组成
本文来自The Learning Machine——一个开放源代码的新项目,该项目旨在为不同背景的人群创建交互式路线图,其中包含对概念、方法、算法及其在Python或R中的代码里实现所有的解释。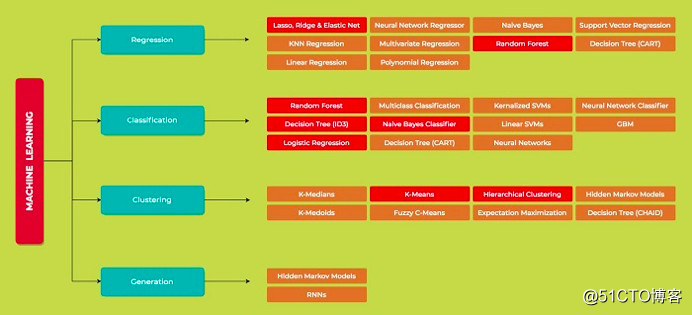


随机森林是一种灵活的、便于使用的机器学习算法,即使没有超参数调整,大多数情况下也会带来好的结果。它可以用来进行分类和回归任务。通过本文,你将会学习到随机森林算法是如何解决分类和回归问题的。
为了理解什么是随机森林算法,首先要熟悉决策树。
决策树往往会产生过拟合问题,尤其会发生在存在整组数据的决策树上。有时决策树仿佛变得只会记忆数据了。下面是一些过拟合的决策树的典型例子,既有分类数据,也有连续数据。
如果一位年龄在15岁到25岁之间的美国男性,他喜欢吃冰激凌,有位德国朋友,厌恶鸟类,2012年8月25日曾吃过薄煎饼——那么他很有可能下载Pokemon Go。
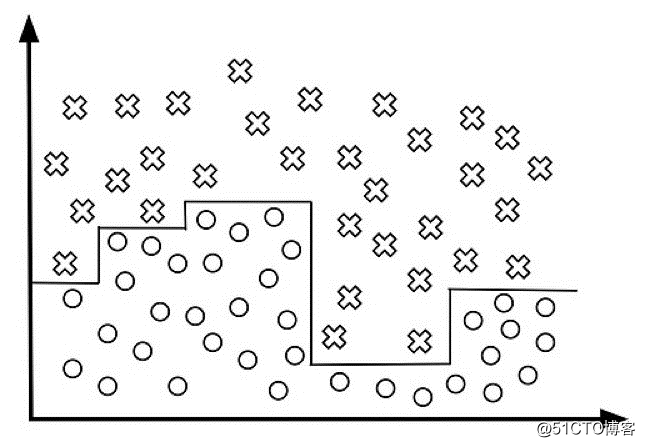
随机森林阻止了这类问题的发生:它是多重决策树的组合,而不只是一棵决策树。随机森林算法下决策树的数量越多,泛化的结果更好。
更准确地说,随机森林的工作原理如下:
从数据集(表)中随机选择k个特征(列),共m个特征(其中k小于等于m)。然后根据这k个特征建立决策树。
重复n次,这k个特性经过不同随机组合建立起来n棵决策树(或者是数据的不同随机样本,称为自助法样本)。
对每个决策树都传递随机变量来预测结果。存储所有预测的结果(目标),你就可以从n棵决策树中得到n种结果。
*针对回归问题,随机森林中的决策树会预测Y的值(输出值)。通过随机森林中所有决策树预测值的平均值计算得出最终预测值。而针对分类问题,随机森林中的每棵决策树会预测最新数据属于哪个分类。最终,哪一分类被选择最多,就预测这个最新数据属于哪一分类。
詹姆斯要决定在巴黎的一周要去哪些景点。他拜访了一位曾在巴黎住过一年的朋友,问朋友曾去过哪些景点,是否觉得有趣。基于自己的经验,这位朋友会给詹姆斯一些建议。
这是典型的决策树算法方法。詹姆斯的朋友根据自己的经验,告诉詹姆斯可以去哪些景点游览。
之后,詹姆斯问了很多在巴黎待过的朋友,询问建议,他们推荐了自己去过的景点。然后詹姆斯选择了被推荐次数最多的景点,这就是典型的随机森林算法。
因此,随机森林是一种在共拥有m个特征的决策树中随机选择k个特征组成n棵决策树,再选择预测结果模式(如果是回归问题,选择平均值)。

可以用来解决分类和回归问题:随机森林可以同时处理分类和数值特征。
抗过拟合能力:通过平均决策树,降低过拟合的风险性。
据观测,如果一些分类/回归问题的训练数据中存在噪音,随机森林中的数据集会出现过拟合的现象。
比决策树算法更复杂,计算成本更高。

随机森林中的超参数既可以用来提高模型的预测能力,也可以加快建模的速度。下面介绍了sklearn内置随机森林函数的超参数:
· 子模型的数量:在利用最大投票数或平均值来预测之前,你想要建立子树的数量。一般来说,子树的数量越多,越能提高性能,预测的准确性就越稳定,但是也会放缓计算过程。
· 节点分裂时参与判断的最大特征数:随机森林允许单个决策树使用特征的最大数量。Sklearn提供了几个选项,如文档中所述。
· 叶子节点最小样本数:内部节点再划分所需最小样本数。
· 并行数:允许使用处理器的数量。如果输出值为1,只能使用一个处理器。输出值为-1则意味着没有限制。
· 随机数生成器:使模型的输出可复制。当模型具有一个确定的随机数,并且给定相同的超参数和相同的训练数据时,模型将始终产生相同的结果。
· 是否计算袋外得分:也称作袋外抽样——它是一种随机森林交叉验证方法。在这个样本中,大约三分之一的数据不是用来训练模型,而是用来评估模型的性能。这些样品被称为袋外样品。这一方法与留一法交叉验证非常相似,但几乎没有额外的计算负担。

查看/下载位于Git存储库中的随机森林模板:
资源:
https://www.kdnuggets.com/education/online.html
https://www.kdnuggets.com/software/index.html

编译组:谢中琦、王书晗
相关链接:
https://www.kdnuggets.com/2019/03/random-forest-python.html
如需转载,请后台留言,遵守转载规范ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
标签:高性能 存储 online 建模 htm line 过拟合 http 组成
原文地址:https://blog.51cto.com/15057819/2567748