标签:http 冲突 优点 回收 直接 没有 内存分配 info 缓存
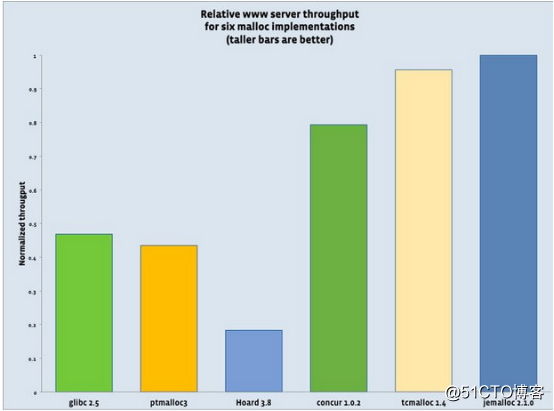
C++性能优化(十一) —— 内存管理器性能分析(1)集成在glibc中,Linux主要发行版的通用实现。
(1)后分配的内存先释放。由于ptmalloc2收缩内存是从top chunk开始,如果与top chunk相邻的chunk不能释放,top chunk 以下的chunk都无法释放。
(2)多线程锁开销大,需要避免多线程频繁分配释放。
(3)内存从thread的arena中分配,不能从一个arena移动到另一个arena。如果多线程使用内存不均衡,容易导致内存的浪费。
(4)每个chunk至少8字节的开销很大。
(5)不定期分配长生命周期的内存容易造成内存碎片,不利于回收。
(1)小内存在线程ThreadCache中分配,不加锁(加锁代价大约100ns)。
(2)大内存直接按照大小调用mmap系统调用分配。
(3)大内存加锁使用更高效的自旋锁。
(4)减少内存碎片。
(1)使用大内存频繁时,内存在Central Cache或者Page Heap加锁分配。
(2)TCMalloc对大量小内存的分配过于保守,对于内存需求较大的服务(如推荐系统),小内存上限过低。如果请求量过多,锁冲突严重,CPU使用率将指数暴增。
当线程数量不定时,使用TCMalloc。
(1)采用多个arena来避免线程同步。
(2)使用细粒度锁,大大减少加锁。
(3)TCache?GC时对缓存容量进行动态调整。
JeMalloc内存分配器的缺点在于arena?间的内存不可见。
(1)某个线程在arena使用了大量内存,但arena?并没有其它线程使用,导致arena?内存无法被回收,占用过多。
(2)两个位于不同arena的线程频繁进行内存申请,导致两个arena的内存出现大量交叉,但连续的内存由于在不同arena而无法进行合并。
当线程数量固定,不会频繁创建退出时,可以使用jemalloc。
标签:http 冲突 优点 回收 直接 没有 内存分配 info 缓存
原文地址:https://blog.51cto.com/9291927/2575317