标签:div img format school tle name 入门 爬虫 数据
概述昨天那个推文发布后,有朋友反馈说表格上的信息太少了,于是我就又增加了各个调剂信息的详情。
此处我只列举了一部分调剂院校数据,更多数据请公众号后台回复“调剂”获取,该回复文件持续更新。祝成功上岸。祝福武汉,祝福湖北,祝福中国,祝福世界!
项目总述
其实和之前写的没啥区别,这里不再赘述,详见几十行代码批量下载高清壁纸 爬虫入门实战
部分代码
构建url
# 构建所有url
def get_url_list(self):
url_list = []
for i in range(1, 17):
url = self.base_url.format(i)
url_list.append(url)
return url_list
某网站的数据解析部分
# 解析存储数据
def parse_data(self, data):
tree = etree.HTML(data)
info_list = tree.xpath("//div[@class=‘info-item font14‘]")
for info in info_list:
school_name = info.xpath(‘./span/text()‘)[0]
major_name = info.xpath(‘./span/text()‘)[1]
info_title = info.xpath(‘./span/a/text()‘)
info_time = info.xpath(‘./span/text()‘)[2]
global n
sheet.write(n, 0, school_name)
sheet.write(n, 1, major_name)
sheet.write(n, 2, info_title)
sheet.write(n, 3, info_time)
n = n + 1获取数据查看
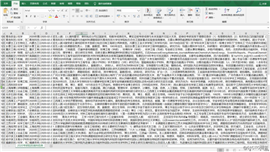
Python助力2020考研调剂 各大高校调剂信息(持续更新)
标签:div img format school tle name 入门 爬虫 数据
原文地址:https://blog.51cto.com/15069472/2577372