标签:output pre multi 融合 自然语言 定义 target text nbsp
使用函数式 API,可以直接操作张量,也可以把层当作函数来使用,接收张量并返回张量。
将 Sequential 模型转换为对应的 函数式 API
Sequential 模型
seq_model = Sequential() seq_model.add(layers.Dense(32, activation=‘relu‘, input_shape=(64,))) seq_model.add(layers.Dense(32, activation=‘relu‘)) seq_model.add(layers.Dense(10, activation=‘softmax‘))

对比上面的两种实现,深蓝色的部分基本是一样的,只是需要后面添加关联的信息即可。
典型的问答模型有两个输入:一个自然语言描述的问题和一个文本片段(比如新闻文章),后者提供用于回答问题的信息。然后模型要生成一个回答,在最简单的情况下,这个回答只包含一个词,可以通过对摸个预定义的词表做softmax得到。
输入:问题 + 文本片段
输出:回答(一个词)
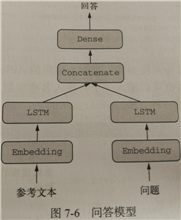
思考说明,相当于两个线性模型在合并,中间用 layers.concatenate() 连接

标准写法如下:
from keras.models import Model
from keras import layers
from keras import Input
text_vocabulary_size = 10000
question_vocabulary_size = 10000
answer_vocabulary_size = 500
text_input = Input(shape=(None,),
dtype=‘int32‘,
name=‘text‘)
embeded_text = layers.Embedding(text_vocabulary_size,64)(text_input)
encoded_text = layers.LSTM(32)(embeded_text)
question_input = Input(shape=(None,),
dtype = ‘int32‘,
name = ‘question‘)
embeded_question = layers.Embedding(question_vocabulary_size,32)(question_input)
encoded_question = layers.LSTM(16)(embeded_question)
concatenated = layers.concatenate([encoded_text,encoded_question],axis=-1)
answer = layers.Dense(answer_vocabulary_size,activation=‘softmax‘)(concatenated)
model = Model([text_input,question_input],answer)
model.compile(optimizer=‘rmsprop‘,
loss = ‘categorical_crossentropy‘,
metrics = [‘acc‘])
model.summary()
标签:output pre multi 融合 自然语言 定义 target text nbsp
原文地址:https://www.cnblogs.com/alex-bn-lee/p/14211423.html