标签:build dem except static 图片 sub col png date
Java解析分为两类四种方法。
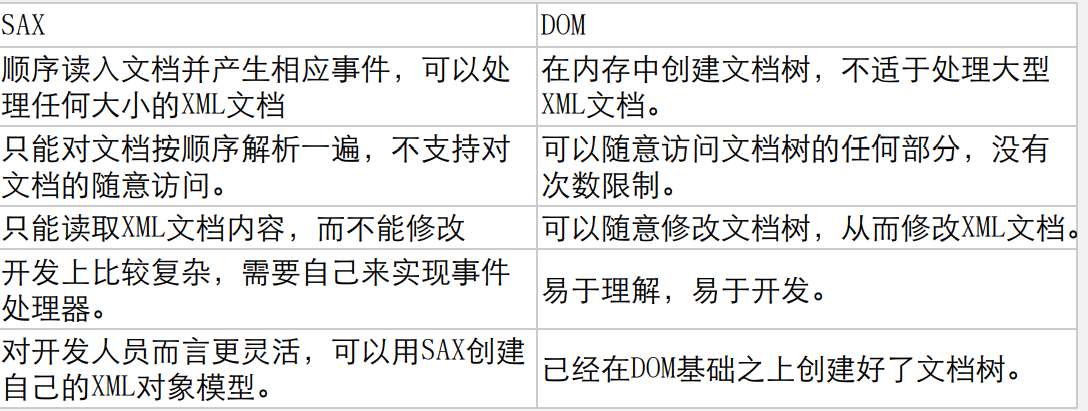
第一类是基础方法:DOM解析和SAX解析
第二类是在基础方法上扩展出来的方法:JDOM解析和DOM4J解析
DOM和SAX是两种解析方法(没有具体实现,只有接口),所有java自身提供了DomcumentBuilderFactory/DomcumentBuilder和SAXParserFactory/SAXParser实现这两个解析器(就是不需要添加额外的架包)
DOM(Document Object Model):文件对象模型,是W3C组织推荐的处理可扩展标志语言的标准编程接口。
DOM是与平台无关的官方解析方法。由W3C提供的接口,将整个XML文档读入,构建一个DOM树来对各个节点进行操作。
SAX(Simple API for XML):XML简单应用程序接口。
SAX是基于事件驱动的解析方法。是在读取文档时激活一系列事件,这些事件被推给事件处理器,然后由事件处理器提供对文档内容的访问。
由于JDOM和DOM4J是扩展方法,所以Java本身是没有的,需要添加相应的架包dom4j.jar和jdom.jar
JDOM是处理XML的纯JAVA API,API大量使用了Collection类,JDOM是使用具体类而不使用接口。
DOM4J是目前xml解析方面最优秀的(就是目前主流的),它合并了很多基本XML文档表示的功能,包括集成的XPATH支持、XML Schema支持以及基于事件的处理。
.xml如下:
<?xml version="1.0" encoding="UTF-8"?>
<Root>
<VALUE>
<NO DATE="C005">A1</NO>
<ADDR>A01</ADDR>
</VALUE>
<VALUE>
<NO DATE="C004">A2</NO>
<ADDR>A03</ADDR>
</VALUE>
<note>
<NO DATE="C014">A4</NO>
<ADDR>A09</ADDR>
</note>
</Root>
.class解析如下:
import java.io.*;
import java.util.*;
//导入相应架包的API
import org.dom4j.*;
import org.dom4j.io.*;
public class DOM4Java
{
public static void main(String[] args)
{
// 解析demo.xml文件
try {
String path=DOM4Java.class.getClassLoader().getResource("").toString().substring(6);// 获得绝对路径 注意:我的xml是放在这个绝对路径上的
File f= new File(path+"demo.xml");
// 创建SAXReader的对象reader
SAXReader reader = new SAXReader();
// 通过reader对象的read方法加载books.xml文件,获取docuemnt对象。
Document doc = reader.read(f);
// 通过document对象获取根节点root
Element root = doc.getRootElement();
System.out.println(root.getName());
// 通过element对象的elementIterator方法获取迭代器
Iterator it = root.elementIterator("VALUE");//获取root下所有value 子标签
while(it.hasNext())
{
Element foo = (Element) it.next(); //得到value
Element subfoo=foo.element("NO"); //获取value 下NO 子标签
System.out.print("车牌号码:" + foo.elementText("NO")+" 属性:"+subfoo.attributeValue("DATE"));
System.out.println("城市编号:" + foo.elementText("ADDR"));
}
System.out.println("-----------------------------------");
Element e=root.element("note");
System.out.println(e.elementText("NO"));
}catch (Exception e)
{
e.printStackTrace();
}
}
}
结果如下:
Root
车牌号码:A1 属性:C005城市编号:A01
车牌号码:A2 属性:C004城市编号:A03
-----------------------------------
A4
标签:build dem except static 图片 sub col png date
原文地址:https://www.cnblogs.com/shenStudy/p/14219474.html