标签:调用 collect abr cdn 分析 data avg 图片 src
Apache Spark 2.2 以及以上版本提供的三种 API - RDD、DataFrame 和 Dataset,它们都可以实现很多相同的数据处理,它们之间的性能差异如何,在什么情况下该选用哪一种呢?
从一开始 RDD 就是 Spark 提供的面向用户的主要 API。从根本上来说,一个 RDD 就是你的数据的一个不可变的分布式元素集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层 API 进行并行处理。
可能你会问:RDD 是不是快要降级成二等公民了?是不是快要退出历史舞台了?
答案是非常坚决的:不!
我们可以通过简单的 API 方法调用在 DataFrame 或 Dataset 与 RDD 之间进行无缝切换,事实上 DataFrame 和 Dataset也正是基于 RDD 提供的。
与 RDD 相似,DataFrame 也是数据的一个不可变分布式集合。但与 RDD 不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计 DataFrame 的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。它提供了特定领域内专用的 API 来处理你的分布式数据,并让更多的人可以更方便地使用 Spark,而不仅限于专业的数据工程师。
Spark 2.0 中,DataFrame 和 Dataset 的 API 融合到一起,完成跨函数库的数据处理能力的整合。在整合完成之后,开发者们就不必再去学习或者记忆那么多的概念了,可以通过一套名为 Dataset 的高级并且类型安全的 API 完成工作。
相对于RDD,Dataset 提供了强类型支持,也是在 RDD 的每行数据加了类型约束

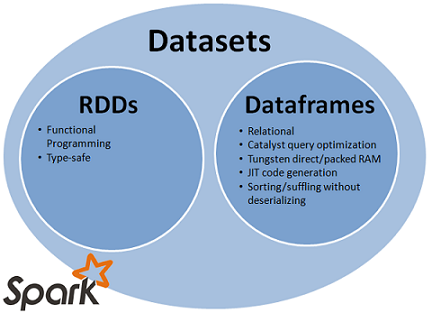
在 Spark 2.0 里,DataFrame 和 Dataset 的统一 API 会为 Spark 开发者们带来许多方面的好处
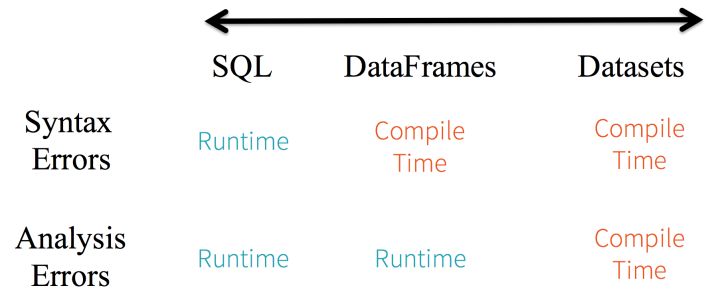
从 SQL 的最小约束到 Dataset 的最严格约束,把静态类型和运行时安全想像成一个图谱。比如,如果你用的是 Spark SQL 的查询语句,要直到运行时你才会发现有语法错误(这样做代价很大),而如果你用的是 DataFrame 和 Dataset,你在编译时就可以捕获错误(这样就节省了开发者的时间和整体代价)。也就是说,当你在 DataFrame 中调用了 API 之外的函数时,编译器就可以发现这个错。不过,如果你使用了一个不存在的字段名字,那就要到运行时才能发现错误了。
图谱的另一端是最严格的 Dataset。因为 Dataset API 都是用 lambda 函数和 JVM 类型对象表示的,所有不匹配的类型参数都可以在编译时发现。而且在使用 Dataset 时,你的分析错误也会在编译时被发现,这样就节省了开发者的时间和代价。
所有这些最终都被解释成关于类型安全的图谱,内容就是你的 Spark 代码里的语法和分析错误。在图谱中,Dataset 是最严格的一端,但对于开发者来说也是效率最高的。
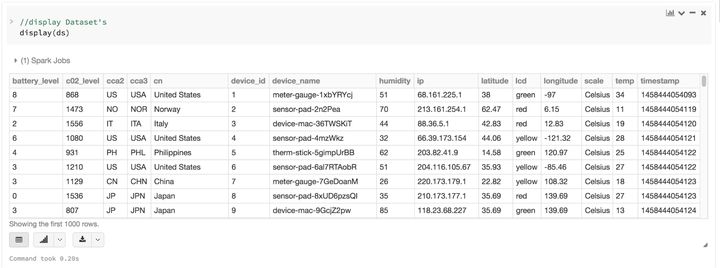
把 DataFrame 当成 Dataset[Row] 的集合,就可以对你的半结构化数据有了一个结构化的定制视图。比如,假如你有个非常大量的用 JSON 格式表示的物联网设备事件数据集。因为 JSON 是半结构化的格式,那它就非常适合采用 Dataset 来作为强类型化的 Dataset[DeviceIoTData] 的集合。
{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ",
"ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland",
"latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius",
"temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408,
"lcd": "red", "timestamp" :1458081226051}
你可以用一个Scala Case Class来把每条JSON记录都表示为一条DeviceIoTData,一个定制化的对象。
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2:
String, cca3: String, cn: String, device_id: Long, device_name: String,
humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double,
scale:String, temp: Long, timestamp: Long)
接下来,我们就可以从一个JSON文件中读入数据。
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read
.json(“/databricks-public-datasets/data/iot/iot_devices.json”)
.as[DeviceIoTData]
上面的代码其实可以细分为三步:
许多和结构化数据打过交道的人都习惯于用列的模式查看和处理数据,或者访问对象中的某个特定属性。将 Dataset 作为一个有类型的 Dataset[ElementType] 对象的集合,你就可以非常自然地又得到编译时安全的特性,又为强类型的JVM对象获得定制的视图。而且你用上面的代码获得的强类型的Dataset[T]也可以非常容易地用高级方法展示或处理。
虽然结构化可能会限制你的 Spark 程序对数据的控制,但它却提供了丰富的语义,和方便易用的特定领域内的操作,后者可以被表示为高级结构。事实上,用 Dataset 的高级 API 可以完成大多数的计算。
比如,它比用 RDD 数据行的数据字段进行 agg、select、sum、avg、map、filter或groupBy等操作简单得多,只需要处理Dataset 类型的 DeviceIoTData 对象即可。
用一套特定领域内的 API 来表达你的算法,比用 RDD 来进行关系代数运算简单得多。
除了上述优点之外,你还要看到使用 DataFrame 和 Dataset API 带来的空间效率和性能提升。原因有如下两点:

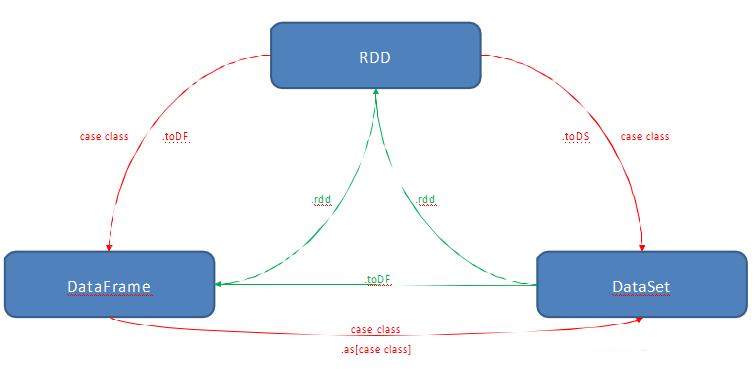
注意:只需要简单地调用一下.rdd,就可以无缝地将 DataFrame 或 Dataset 转换成 RDD,如下:
// select specific fields from the Dataset, apply a predicate
// using the where() method, convert to an RDD, and show first 10
// RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level")
.where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)
在什么时候该选用 RDD、DataFrame 或 Dataset 看起来好像挺明显。前者可以提供底层的功能和控制,后者支持定制的视图和结构,可以提供高级和特定领域的操作,节约空间并快速运行。
DataFrame 和 Dataset,或 RDD API,按你的实际需要和场景选一个来用吧!
Spark SQL 之 RDD、DataFrame 和 Dataset 如何选择
标签:调用 collect abr cdn 分析 data avg 图片 src
原文地址:https://www.cnblogs.com/binbingg/p/14240076.html