标签:tar config turn context idea RoCE code you min
概述:Spark 程序开发,调试和运行,intellij idea开发Spark java程序。
分两部分,第一部分基于intellij idea开发Spark实例程序并在intellij IDEA中运行Spark程序.第二部分,将开发程序提交到Spark local或者hadoop YARN集群运行。Github项目源码
图1,直接在intellij IDEA(社区版)中开发调试,直接run。
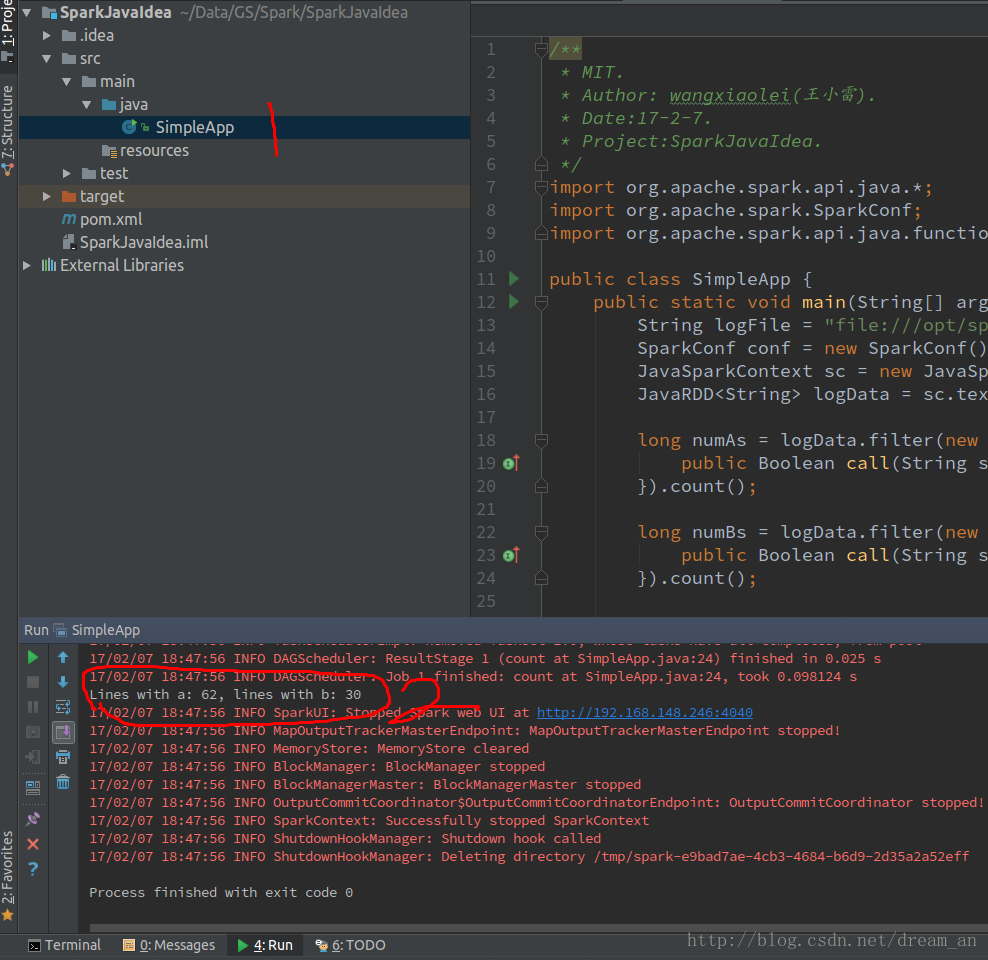
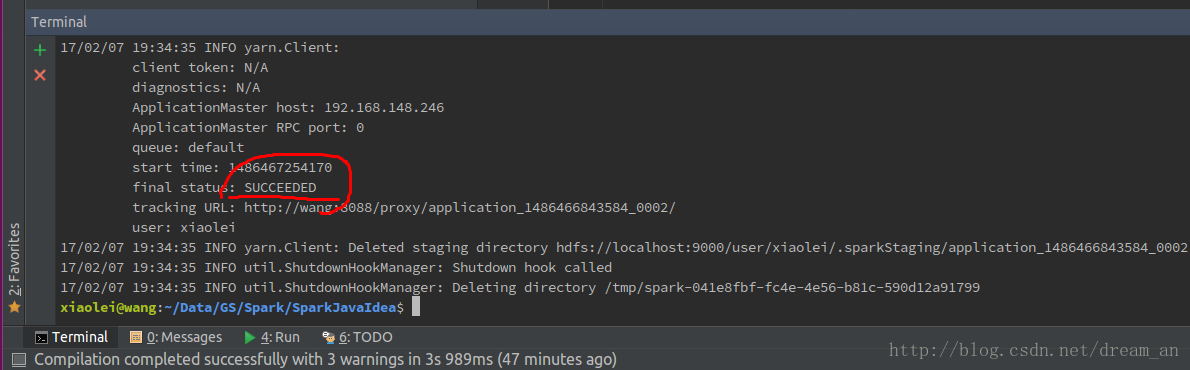
图2,直接在intellij IDEA(社区版)中用hadoop YARN模式。
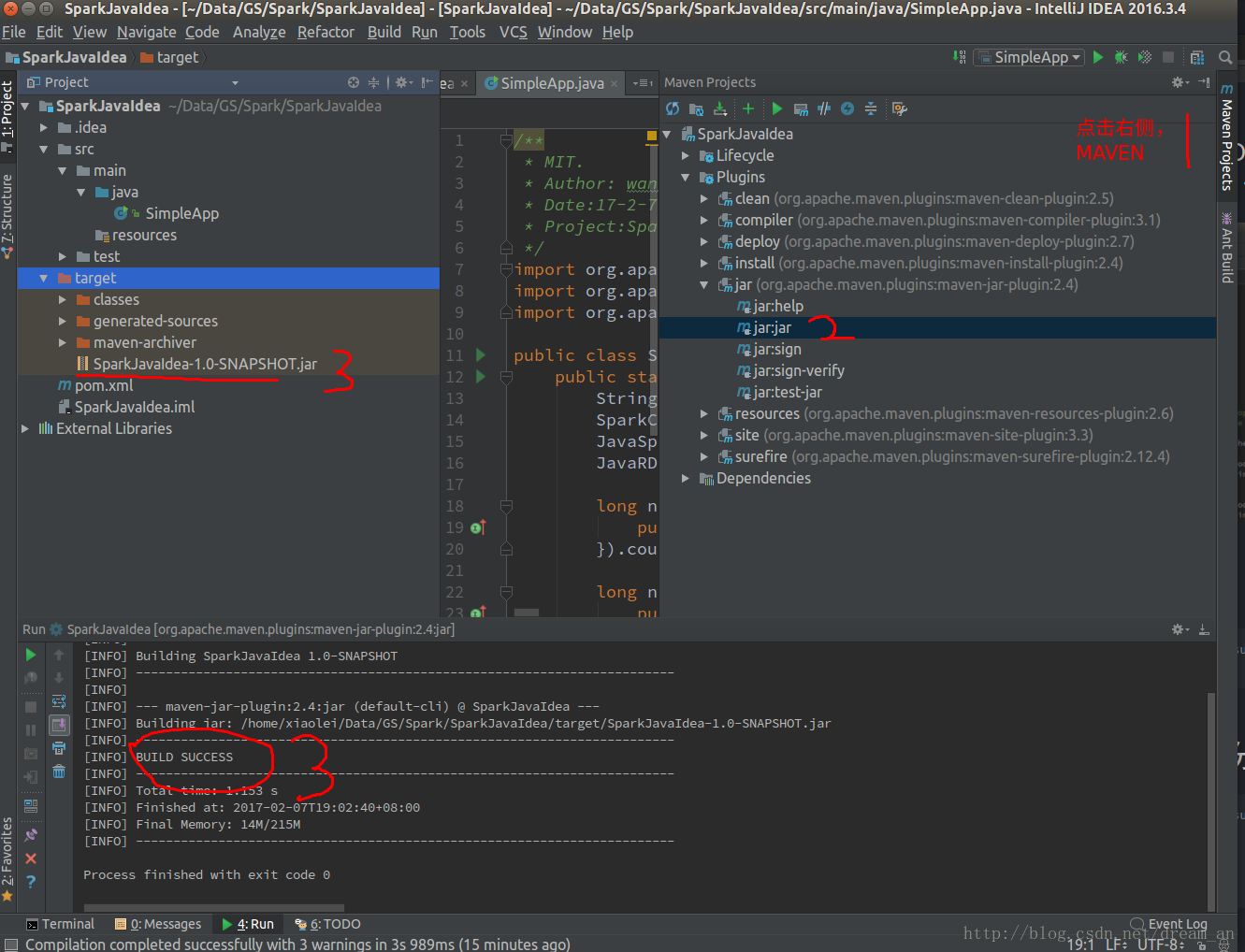
初始化的MAVEN项目如下

SimpleApp.java/**
* MIT.
* Author: wangxiaolei(王小雷).
* Date:17-2-7.
* Project:SparkJavaIdea.
*/
import org.apache.spark.api.java.*;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///opt/spark-2.1.0-bin-hadoop2.7/README.md"; // Should be some file on your system
SparkConf conf = new SparkConf().setAppName("Simple Application");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs + ", lines with b: " + numBs);
sc.stop();
}
}pom.xml<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wangxiaolei</groupId>
<artifactId>SparkJavaIdea</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
</project>-Dspark.master=local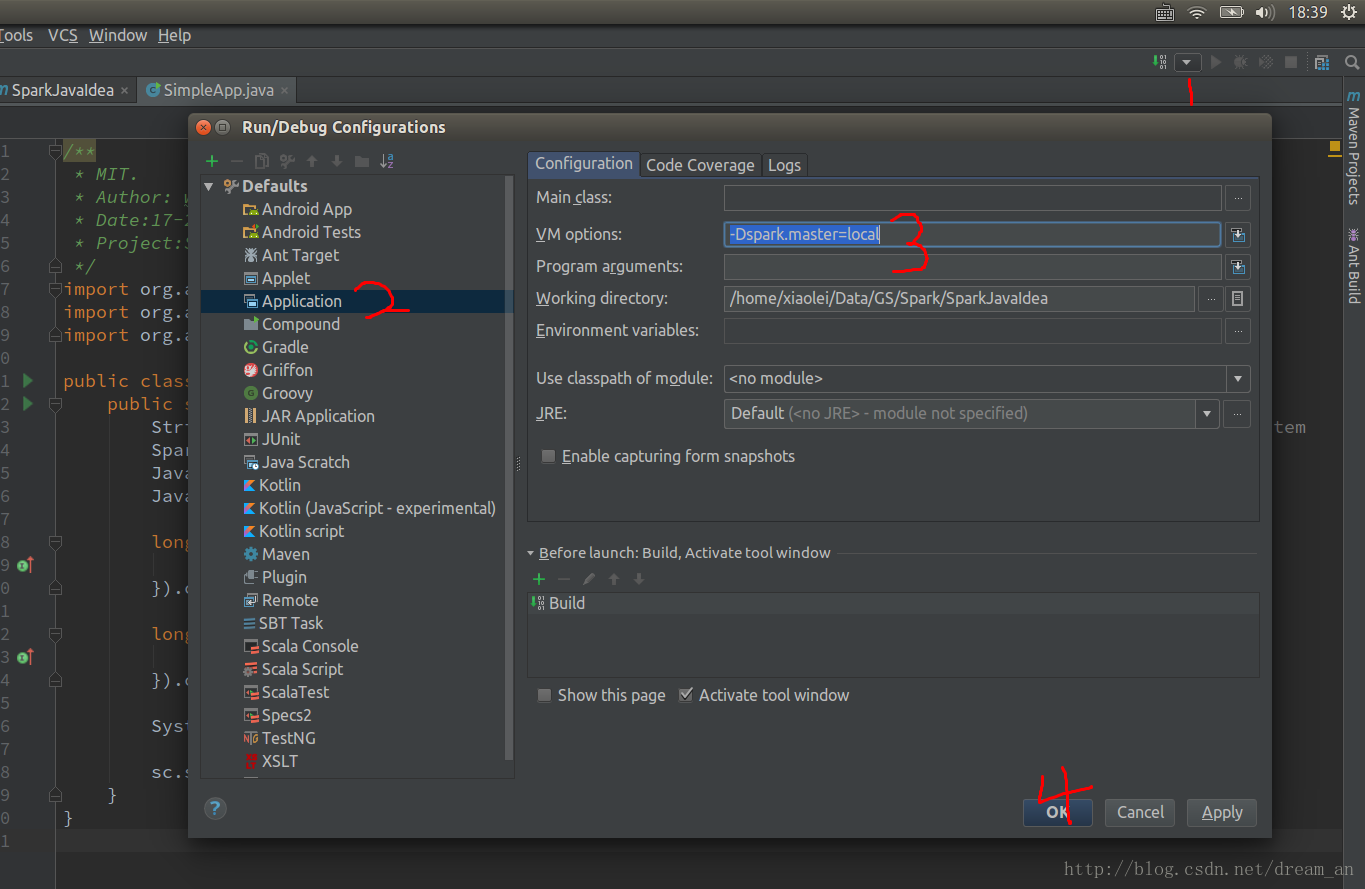
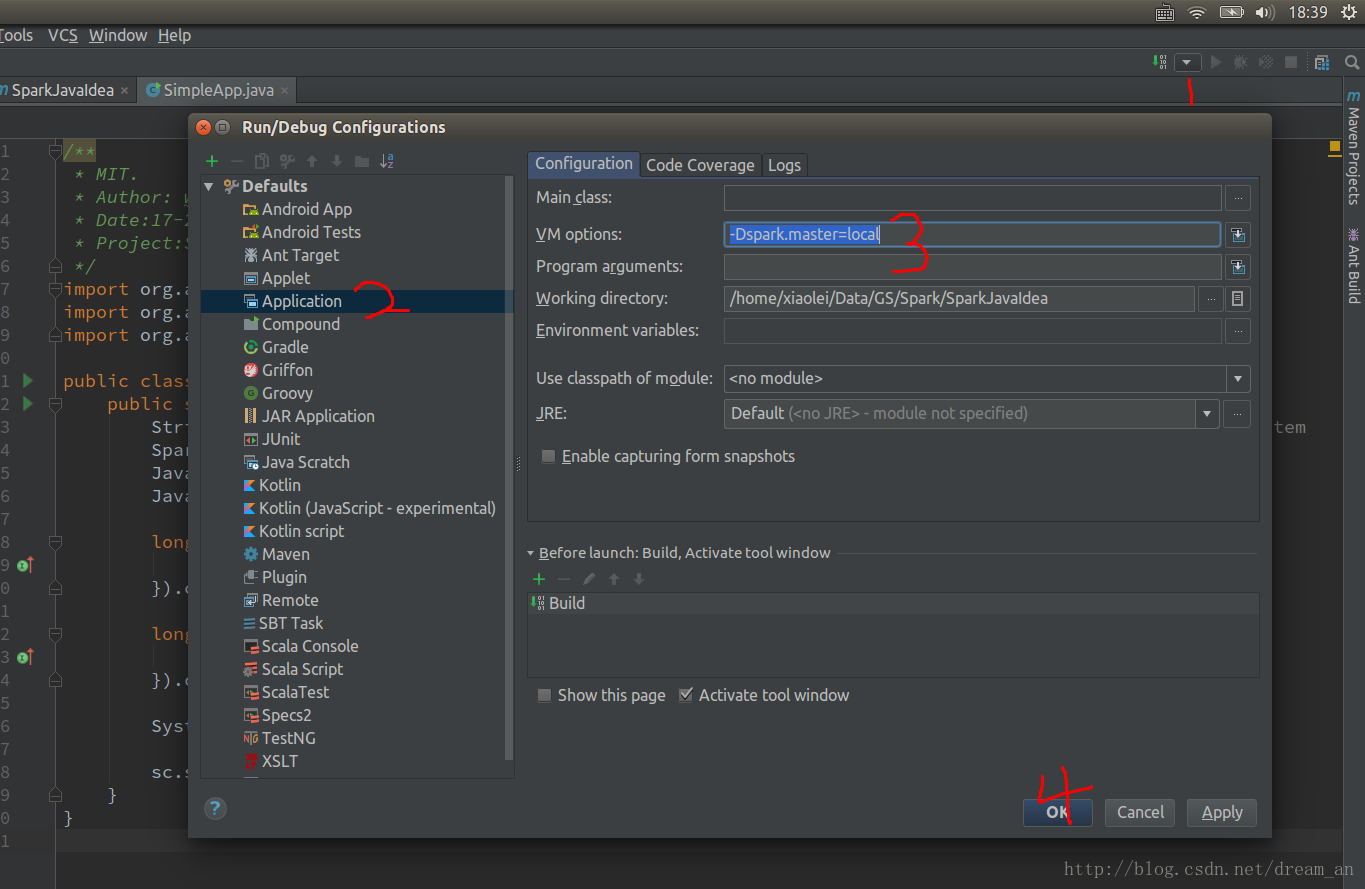
已经将Readme.md中的单词a和b统计出来了Lines with a: 62, lines with b: 30
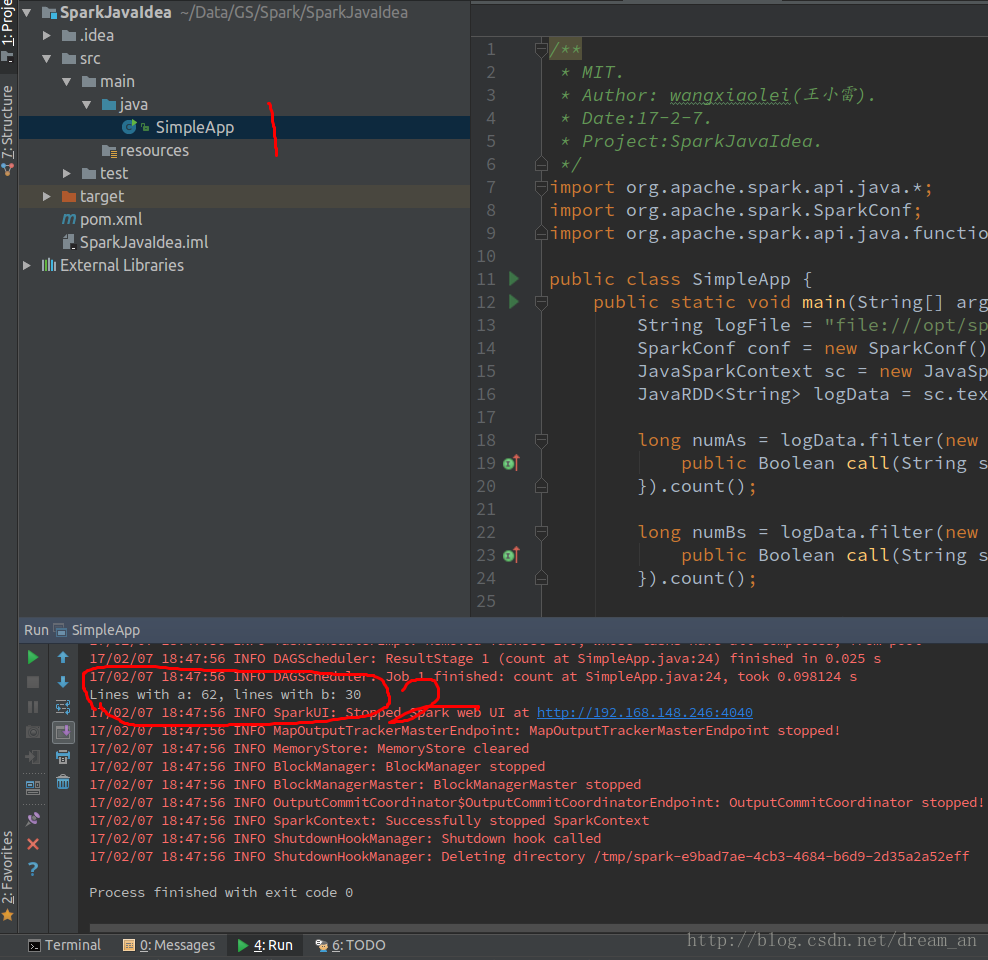
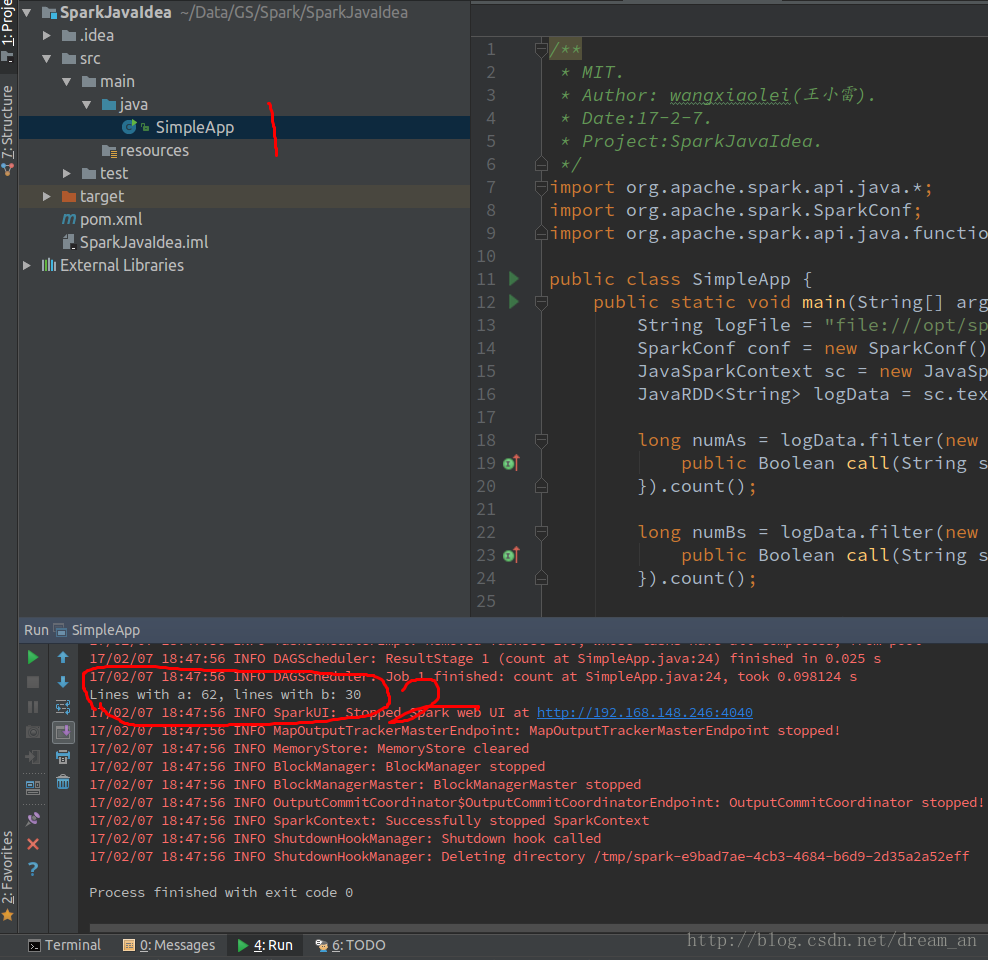
至此,Spark在intellij IDEA中开发,并在IDEA中运行成功!
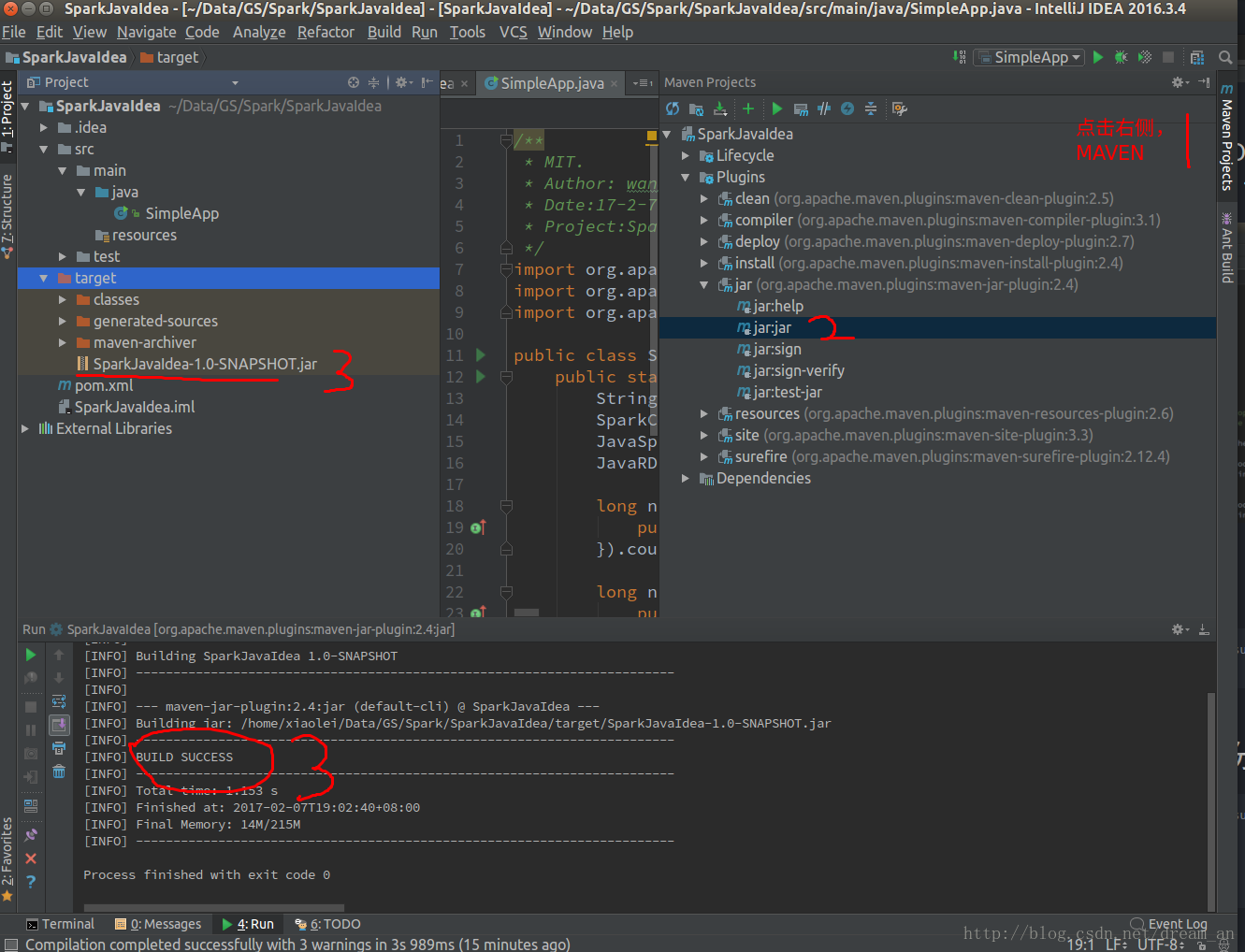
/opt/spark-2.1.0-bin-hadoop2.7/bin/spark-submit --class "SimpleApp" --master local[4] target/SparkJavaIdea-1.0-SNAPSHOT.jar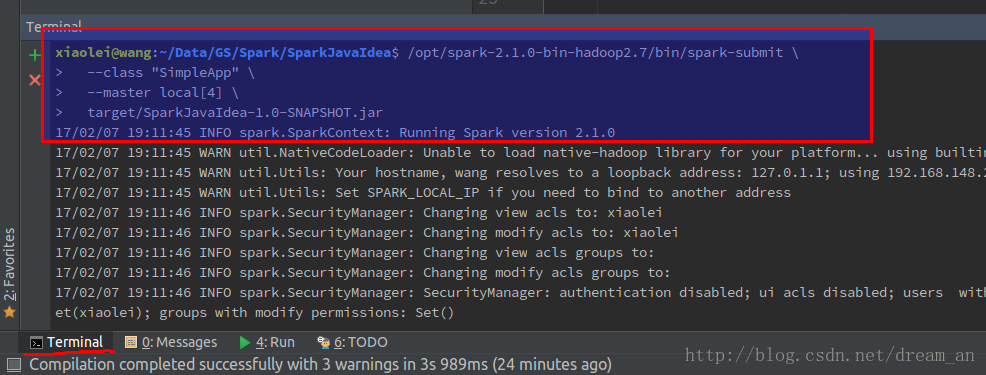
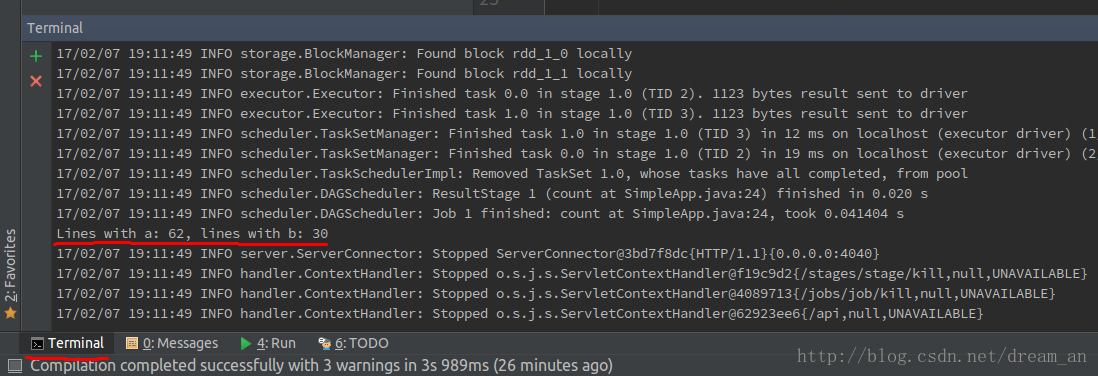
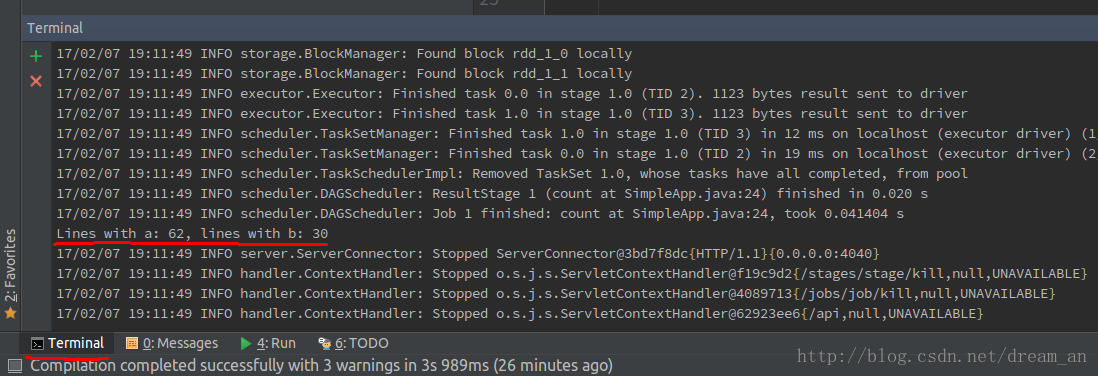
至此,Spark local模式程序开发和运行成功!
# 初次搭建集群需要格式化namenode(已经初始化过可省略)
/opt/hadoop-2.7.3/bin/hdfs namenode -format
#开启hadoop集群(伪分布式)
/opt/hadoop-2.7.3/sbin/start-all.sh
#开启Spark
/opt/spark-2.1.0-bin-hadoop2.7/sbin/start-all.sh
#查看开启状态
jps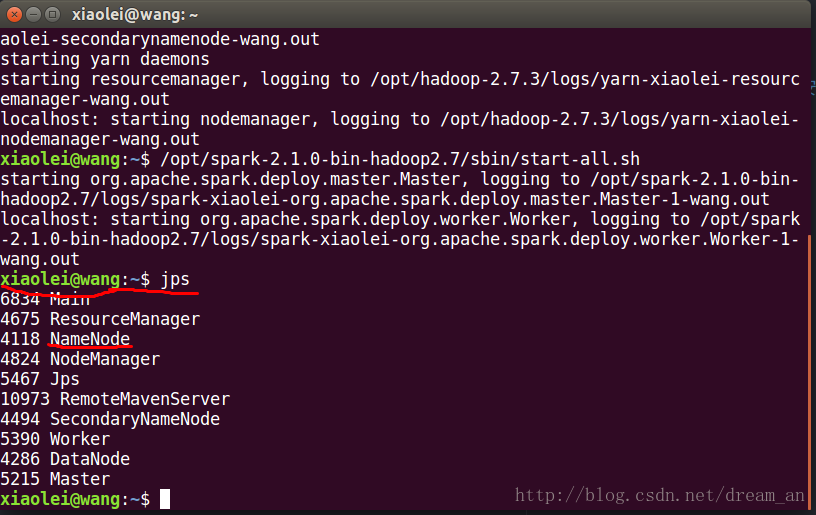
/opt/spark-2.1.0-bin-hadoop2.7/bin/spark-submit --class SimpleApp --master yarn --deploy-mode cluster target/SparkJavaIdea-1.0-SNAPSHOT.jar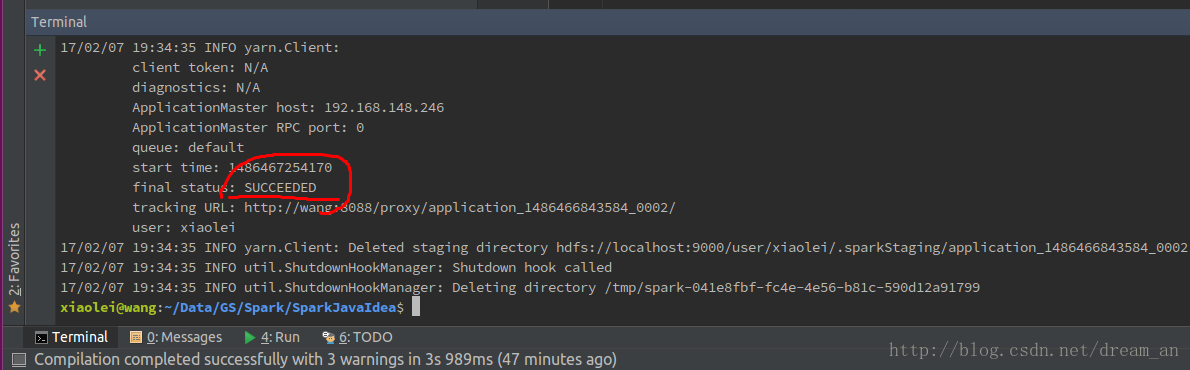
至此,Spark在intellij IDEA中开发,并在hadoop YARN模式下运行成功!
http://localhost:8088/cluster/apps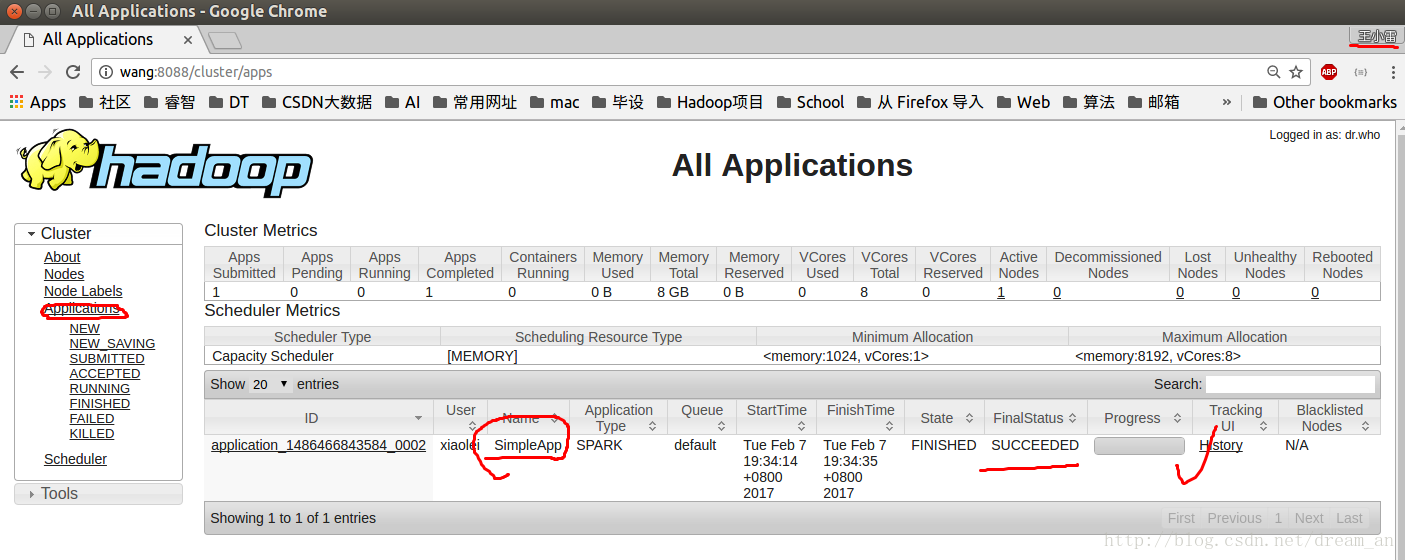
至此,Spark在intellij IDEA中开发,并在hadoop YARN模式下运行成功!
spark (Java API) 在Intellij IDEA中开发并运行
标签:tar config turn context idea RoCE code you min
原文地址:https://www.cnblogs.com/cnndevelop/p/14242264.html