标签:结合 scl 使用 类别 类型 kaggle 取出 分类算法 算法
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
来源:KNN算法最早是由Cover和Hart提出的一种分类算法
两个样本的距离可以通过如下公式计算,又叫欧式距离
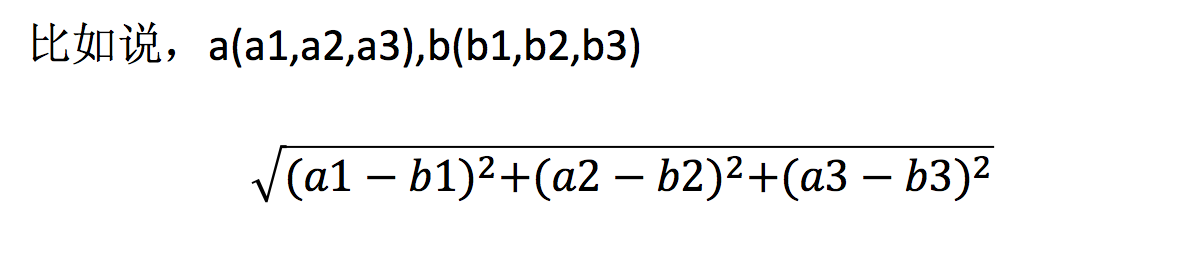
假设我们有现在几部电影
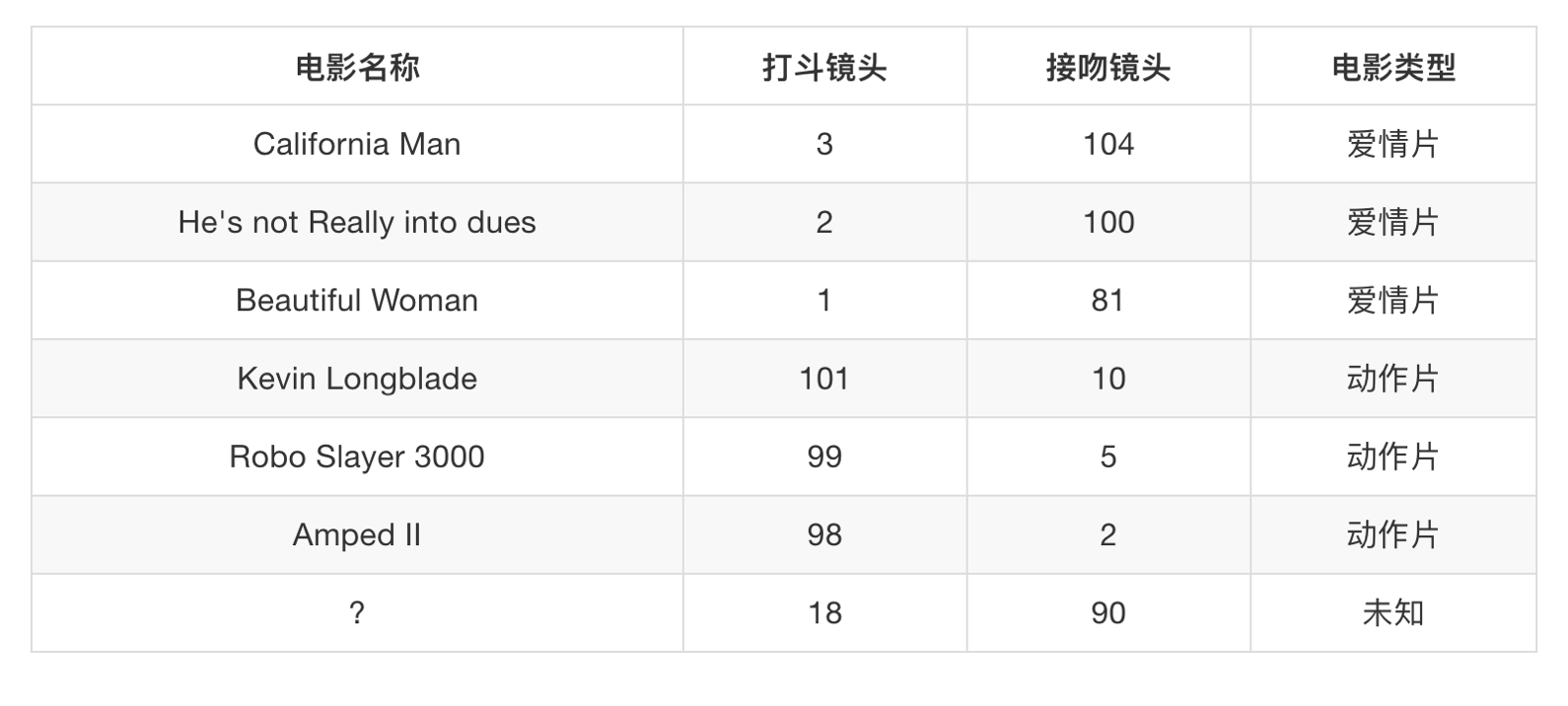
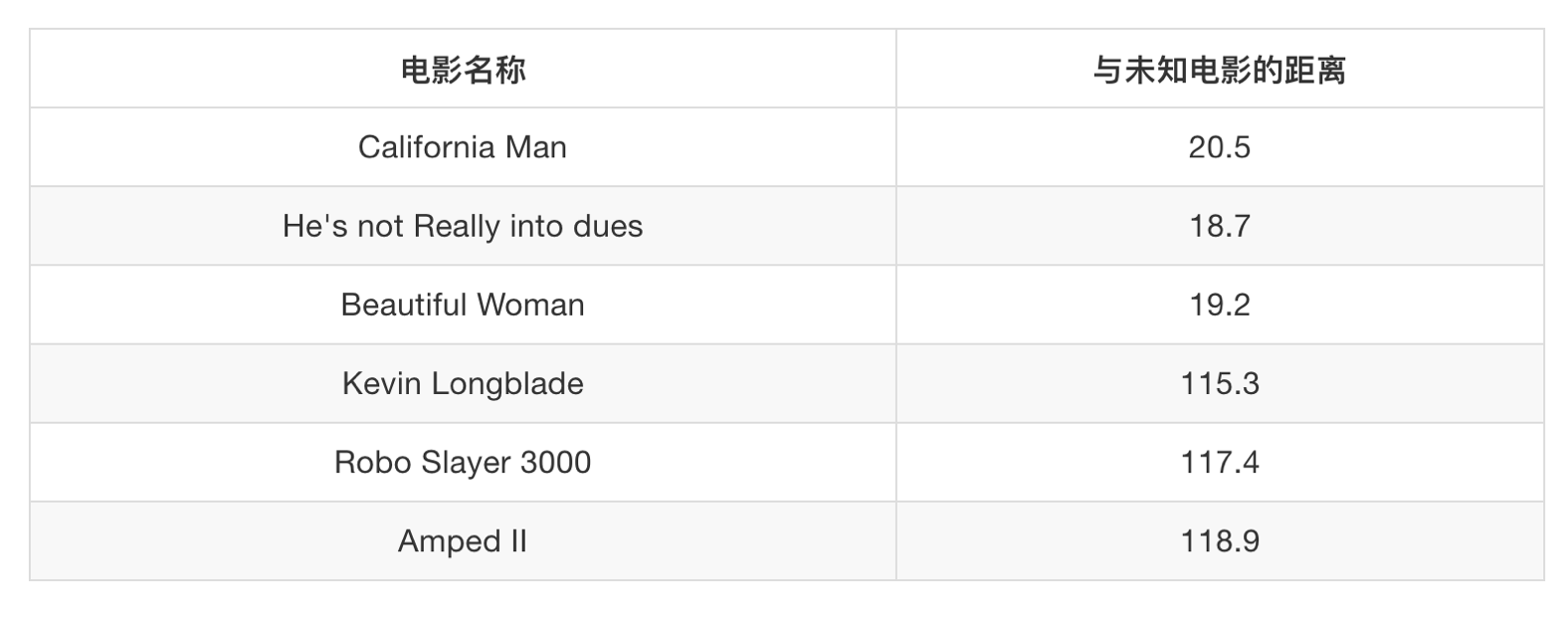
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想

数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
train.csv,test.csv
row_id:登记事件的ID
xy:坐标
准确性:定位准确性
时间:时间戳
place_id:业务的ID,这是您预测的目标
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
1、缩小数据集范围 DataFrame.query()
4、删除没用的日期数据 DataFrame.drop(可以选择保留)
5、将签到位置少于n个用户的删除
place_count = data.groupby(‘place_id‘).count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data[‘place_id‘].isin(tf.place_id)]
分割数据集
标准化处理
k-近邻预测
def knncls(): """ K近邻算法预测入住位置类别 :return: """ # 一、处理数据以及特征工程 # 1、读取收,缩小数据的范围 data = pd.read_csv("./data/FBlocation/train.csv") # 数据逻辑筛选操作 df.query() data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75") # 删除time这一列特征 data = data.drop([‘time‘], axis=1) print(data) # 删除入住次数少于三次位置 place_count = data.groupby(‘place_id‘).count() tf = place_count[place_count.row_id > 3].reset_index() data = data[data[‘place_id‘].isin(tf.place_id)] # 3、取出特征值和目标值 y = data[‘place_id‘] # y = data[[‘place_id‘]] x = data.drop([‘place_id‘, ‘row_id‘], axis=1) # 4、数据分割与特征工程? # (1)、数据分割 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3) # (2)、标准化 std = StandardScaler() # 队训练集进行标准化操作 x_train = std.fit_transform(x_train) print(x_train) # 进行测试集的标准化操作 x_test = std.fit_transform(x_test) # 二、算法的输入训练预测 # K值:算法传入参数不定的值 理论上:k = 根号(样本数) # K值:后面会使用参数调优方法,去轮流试出最好的参数[1,3,5,10,20,100,200] knn = KNeighborsClassifier(n_neighbors=1) # 调用fit() knn.fit(x_train, y_train) # 预测测试数据集,得出准确率 y_predict = knn.predict(x_test) print("预测测试集类别:", y_predict) print("准确率为:", knn.score(x_test, y_test)) return None
k值取很小:容易受到异常点的影响
k值取很大:受到样本均衡的问题
距离计算上面,时间复杂度高
标签:结合 scl 使用 类别 类型 kaggle 取出 分类算法 算法
原文地址:https://www.cnblogs.com/wendi/p/14283794.html