标签:package ber pie inux cas crc 使用 伯克利 网络传输
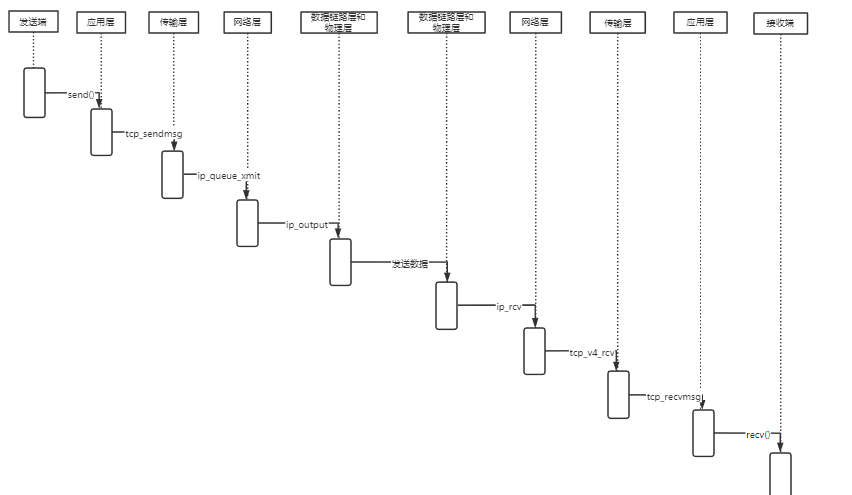
在深入理解Linux内核任务调度(中断处理、softirg、tasklet、wq、内核线程等)机制的基础上,分析梳理send和recv过程中TCP/IP协议栈相关的运行任务实体及相互协作的时序分析。
编译、部署、运行、测评、原理、源代码分析、跟踪调试等
应该包括时序图
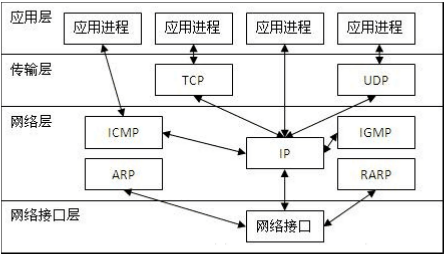
各层的功能如下:
1、应用层的功能为对客户发出的一个请求,服务器作出响应并提供相应的服务。
2、传输层的功能为通信双方的主机提供端到端的服务,传输层对信息流具有调节作用,提供可靠性传输,确保数据到达无误。
3、网络层功能为进行网络互连,根据网间报文IP地址,从一个网络通过路由器传到另一网络。
4、网络接口层负责接收IP数据报,并负责把这些数据报发送到指定网络上。
TCP/IP协议的主要特点:
(1)TCP/IP协议不依赖于任何特定的计算机硬件或操作系统,提供开放的协议标准,即使不考虑Internet,TCP/IP协议也获得了广泛的支持。所以TCP/IP协议成为一种联合各种硬件和软件的实用系统。
(2)标准化的高层协议,可以提供多种可靠的用户服务。
(3)统一的网络地址分配方案,使得整个TCP/IP设备在网中都具有惟一的地址。
(4)TCP/IP协议并不依赖于特定的网络传输硬件,所以TCP/IP协议能够集成各种各样的网络。用户能够使用以太网(Ethernet)、令牌环网(Token Ring Network)、拨号线路(Dial-up line)、X.25网以及所有的网络传输硬件。
Linux 内核主要由 5 个模块构成,它们分别是:
进程调度模块 用来负责控制进程对 CPU 资源的使用。所采取的调度策略是各进程能够公平合理地访问 CPU,同时保证内核能及时地执行硬件操作。
内存管理模块 用于确保所有进程能够安全地共享机器主内存区,同时,内存管理模块还支持虚拟内存管理方式,使得 Linux 支持进程使用比实际内存空间更多的内存容量。并可以利用文件系统把暂时不用的内存数据块会被交换到外部存储设备上去,当需要时再交换回来。
文件系统模块 用于支持对外部设备的驱动和存储。虚拟文件系统模块通过向所有的外部存储设备提供一个通用的文件接口,隐藏了各种硬件设备的不同细节。从而提供并支持与其它操作系统兼容的多种文件系统格式。
进程间通信模块 子系统用于支持多种进程间的信息交换方式。
网络接口模块 提供对多种网络通信标准的访问并支持许多网络硬件。
?独立于具体协议的网络编程接口
?在OSI模型中,主要位于会话层和传输层之间
?BSD Socket(伯克利套接字)是通过标准的UNIX文件描述符和其它程序通讯的一个方法,目前已经被广泛移植到各个平台。
?socket 创建套接字
?connect 建立连接
?bind 绑定本机端口
?listen 监听端口
?accept 接受连接
?recv, recvfrom 数据接收
?send, sendto 数据发送
close, shutdown 关闭套接字
UDP数据通信的过程如下所示:
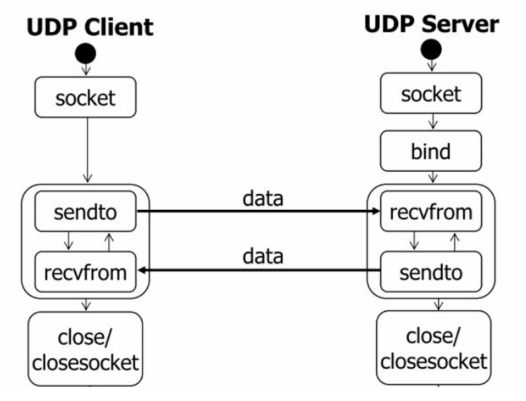
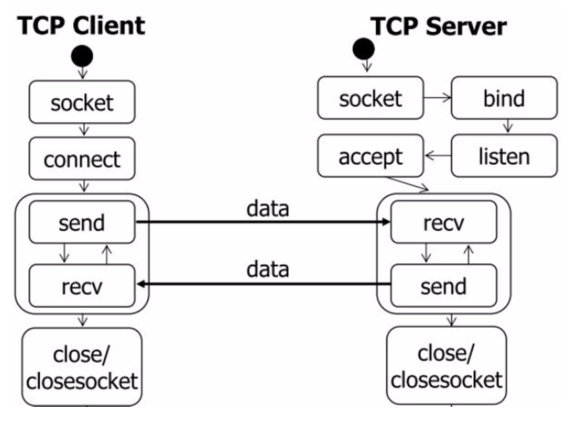
TCP数据通信的过程如下图所示:
tcp首部格式如下:
//tcp首部格式 //http://blog.csdn.net/wenqian1991/article/details/44598537 struct tcphdr { __u16 source;//源端口号 __u16 dest;//目的端口号 __u32 seq;//32位序列号 __u32 ack_seq;//32位确认号 #if defined(LITTLE_ENDIAN_BITFIELD) __u16 res1:4,//4位首部长度 doff:4,//保留 //下面为各个控制位 fin:1,//最后控制位,表示数据已全部传输完成 syn:1,//同步控制位 rst:1,//重置控制位 psh:1,//推控制位 ack:1,//确认控制位 urg:1,//紧急控制位 res2:2;// #elif defined(BIG_ENDIAN_BITFIELD) __u16 doff:4, res1:4, res2:2, urg:1, ack:1, psh:1, rst:1, syn:1, fin:1; #else #error "Adjust your <asm/byteorder.h> defines" #endif __u16 window;//16位窗口大小 __u16 check;//16位校验和 __u16 urg_ptr;//16位紧急指针 };
1 //该结构表示一个网络套接字 2 3 struct socket { 4 5 short type; /* 套接字所用的流类型*/ 6 7 socket_state state;//套接字所处状态 8 9 long flags;//标识字段,目前尚无明确作用 10 11 struct proto_ops *ops; /* 操作函数集指针 */ 12 13 /* data保存指向‘私有‘数据结构指针,在不同的域指向不同的数据结构 */ 14 15 //在INET域,指向sock结构,UNIX域指向unix_proto_data结构 16 17 void *data; 18 19 //下面两个字段只用于UNIX域 20 21 struct socket *conn; /* 指向连接的对端套接字 */ 22 23 struct socket *iconn; /* 指向正等待连接的客户端(服务器端) */ 24 25 struct socket *next;//链表 26 27 struct wait_queue **wait; /* 等待队列 */ 28 29 struct inode *inode;//inode结构指针 30 31 struct fasync_struct *fasync_list; /* 异步唤醒链表结构 */ 32 33 };
struct sock { struct options *opt;//IP选项缓冲于此处 volatile unsigned long wmem_alloc;//发送缓冲队列中存放的数据的大小,这两个与后面的rcvbuf和sndbuf一起使用 volatile unsigned long rmem_alloc;//接收缓冲队列中存放的数据的大小 /* 下面三个seq用于TCP协议中为保证可靠数据传输而使用的序列号 */ unsigned long write_seq;// unsigned long sent_seq;// unsigned long acked_seq;// unsigned long copied_seq;//应用程序有待读取(但尚未读取)数据的第一个序列号 unsigned long rcv_ack_seq;//目前本地接收到的对本地发送数据的应答序列号 unsigned long window_seq;//窗口大小 unsigned long fin_seq;//应答序列号 //下面两个字段用于紧急数据处理 unsigned long urg_seq;//紧急数据最大序列号 unsigned long urg_data;//标志位,1表示收到紧急数据 /* * Not all are volatile, but some are, so we * might as well say they all are. */ volatile char inuse,//表示其他进程正在使用该sock结构,本进程需等待 dead,//表示该sock结构已处于释放状态 urginline,//=1,表示紧急数据将被当做普通数据处理 intr,// blog, done, reuse, keepopen,//=1,使用保活定时器 linger,//=1,表示在关闭套接字时需要等待一段时间以确认其已关闭 delay_acks,//=1,表示延迟应答 destroy,//=1,表示该sock结构等待销毁 ack_timed, no_check, zapped, /* In ax25 & ipx means not linked */ broadcast, nonagle;//=1,表示不使用NAGLE算法 //NAGLE算法:在前一个发送的数据包被应答之前,不可再继续发送其它数据包 unsigned long lingertime;//等待关闭操作的时间 int proc;//该sock结构所属的进程的进程号 struct sock *next; struct sock *prev; /* Doubly linked chain.. */ struct sock *pair; //下面两个字段用于TCP协议重发队列 struct sk_buff * volatile send_head;//这个队列中的数据均已经发送出去,但尚未接收到应答 struct sk_buff * volatile send_tail; struct sk_buff_head back_log;//接收的数据包缓存队列,当套接字正忙时,数据包暂存在这里 struct sk_buff *partial;//用于创建最大长度的待发送数据包 struct timer_list partial_timer;//定时器,用于按时发送partial指针指向的数据包 long retransmits;//重发次数 struct sk_buff_head write_queue,//指向待发送数据包 receive_queue;//读队列,表示数据报已被正式接收,该队列中的数据可被应用程序读取? struct proto *prot;//传输层处理函数集 struct wait_queue **sleep; unsigned long daddr;//sock结构所代表套接字的远端地址 unsigned long saddr;//本地地址 unsigned short max_unacked;//最大未处理请求连接数 unsigned short window;//远端窗口大小 unsigned short bytes_rcv;//已接收字节总数 /* mss is min(mtu, max_window) */ unsigned short mtu; //和链路层协议密切相关 /* 最大传输单元 */ volatile unsigned short mss; //最大报文长度 =mtu-ip首部长度-tcp首部长度,也就是tcp数据包每次能够传输的最大数据分段 volatile unsigned short user_mss; /* mss requested by user in ioctl */ volatile unsigned short max_window;//最大窗口大小 unsigned long window_clamp;//窗口大小钳制值 unsigned short num;//本地端口号 //下面三个字段用于拥塞算法 volatile unsigned short cong_window; volatile unsigned short cong_count; volatile unsigned short ssthresh; volatile unsigned short packets_out;//本地已发送出去但尚未得到应答的数据包数目 volatile unsigned short shutdown;//本地关闭标志位,用于半关闭操作 volatile unsigned long rtt;//往返时间估计值 volatile unsigned long mdev;//绝对偏差 volatile unsigned long rto;//用rtt和mdev 用算法计算出的延迟时间值 /* currently backoff isn‘t used, but I‘m maintaining it in case * we want to go back to a backoff formula that needs it */ volatile unsigned short backoff;//退避算法度量值 volatile short err;//错误标志值 unsigned char protocol;//传输层协议值 volatile unsigned char state;//套接字状态值 volatile unsigned char ack_backlog;//缓存的未应答数据包个数 unsigned char max_ack_backlog;//最大缓存的未应答数据包个数 unsigned char priority;//该套接字优先级 unsigned char debug; unsigned short rcvbuf;//最大接收缓冲区大小 unsigned short sndbuf;//最大发送缓冲区大小 unsigned short type;//类型值如 SOCK_STREAM unsigned char localroute;//=1,表示只使用本地路由 /* Route locally only */ #ifdef CONFIG_IPX ipx_address ipx_dest_addr; ipx_interface *ipx_intrfc; unsigned short ipx_port; unsigned short ipx_type; #endif #ifdef CONFIG_AX25 /* Really we want to add a per protocol private area */ ax25_address ax25_source_addr,ax25_dest_addr; struct sk_buff *volatile ax25_retxq[8]; char ax25_state,ax25_vs,ax25_vr,ax25_lastrxnr,ax25_lasttxnr; char ax25_condition; char ax25_retxcnt; char ax25_xx; char ax25_retxqi; char ax25_rrtimer; char ax25_timer; unsigned char ax25_n2; unsigned short ax25_t1,ax25_t2,ax25_t3; ax25_digi *ax25_digipeat; #endif #ifdef CONFIG_ATALK struct atalk_sock at; #endif /* IP ‘private area‘ or will be eventually */ int ip_ttl;//ip首部ttl字段值,实际上表示路由器跳数 /* TTL setting */ int ip_tos;//ip首部tos字段值,服务类型值 /* TOS */ struct tcphdr dummy_th;//缓存的tcp首部,在tcp协议中创建一个发送数据包时可以利用此字段快速创建tcp首部 struct timer_list keepalive_timer;//保活定时器,用于探测对方窗口大小,防止对方通报窗口大小的数据包丢弃 /* TCP keepalive hack */ struct timer_list retransmit_timer;//重发定时器,用于数据包超时重发 /* TCP retransmit timer */ struct timer_list ack_timer;//延迟应答定时器 /* TCP delayed ack timer */ int ip_xmit_timeout;//表示定时器超时原因 /* Why the timeout is running */ //用于ip多播 #ifdef CONFIG_IP_MULTICAST int ip_mc_ttl; /* Multicasting TTL */ int ip_mc_loop; /* Loopback (not implemented yet) */ char ip_mc_name[MAX_ADDR_LEN]; /* Multicast device name */ struct ip_mc_socklist *ip_mc_list; /* Group array */ #endif /* This part is used for the timeout functions (timer.c). */ int timeout; /* What are we waiting for? */ struct timer_list timer; /* This is the TIME_WAIT/receive timer when we are doing IP */ struct timeval stamp; /* identd */ //一个套接在在不同的层次上分别由socket结构和sock结构表示 struct socket *socket; /* Callbacks *///回调函数 void (*state_change)(struct sock *sk); void (*data_ready)(struct sock *sk,int bytes); void (*write_space)(struct sock *sk); void (*error_report)(struct sock *sk); };
络应用调用Socket API socket (int family, int type, int protocol) 创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 Linux Kernel 的 sock_create() 方法。该方法返回被创建好了的那个 socket 的 file descriptor。对于每一个 userspace 网络应用创建的 socket,在内核中都有一个对应的 struct socket和 struct sock。其中,struct sock 有三个队列(queue),分别是 rx , tx 和 err,在 sock 结构被初始化的时候,这些缓冲队列也被初始化完成;在收据收发过程中,每个 queue 中保存要发送或者接受的每个 packet 对应的 Linux 网络栈 sk_buffer 数据结构的实例 skb。
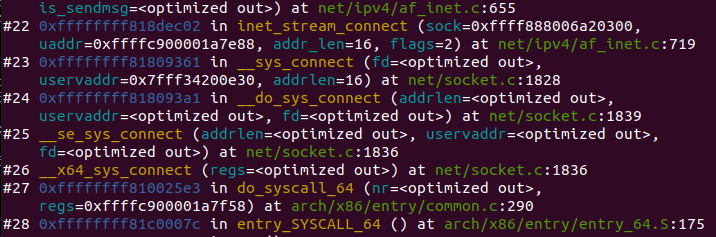
对于 TCP socket 来说,应用调用 connect()API ,使得客户端和服务器端通过该 socket 建立一个虚拟连接。在此过程中,TCP 协议栈通过三次握手会建立 TCP 连接。默认地,该 API 会等到 TCP 握手完成连接建立后才返回。在建立连接的过程中的一个重要步骤是,确定双方使用的 Maxium Segemet Size (MSS)。因为 UDP 是面向无连接的协议,因此它是不需要该步骤的。
应用调用 Linux Socket 的 send 或者 write API 来发出一个 message 给接收端
sock_sendmsg 被调用,它使用 socket descriptor 获取 sock struct,创建 message header 和 socket control message
_sock_sendmsg 被调用,根据 socket 的协议类型,调用相应协议的发送函数。
对于 TCP ,调用 tcp_sendmsg 函数。
对于 UDP 来说,userspace 应用可以调用 send()/sendto()/sendmsg() 三个 system call 中的任意一个来发送 UDP message,它们最终都会调用内核中的 udp_sendmsg() 函数。
以TCP为例,编译代码可得如下所示:
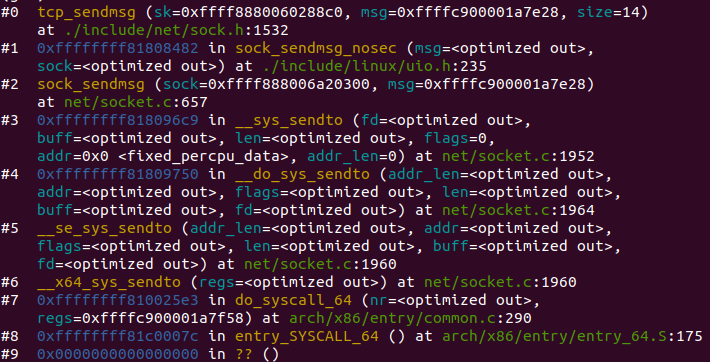
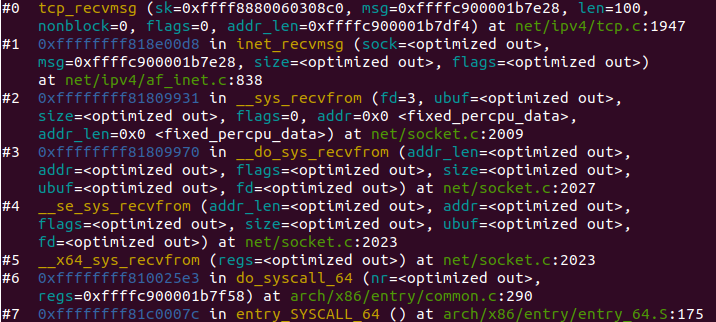
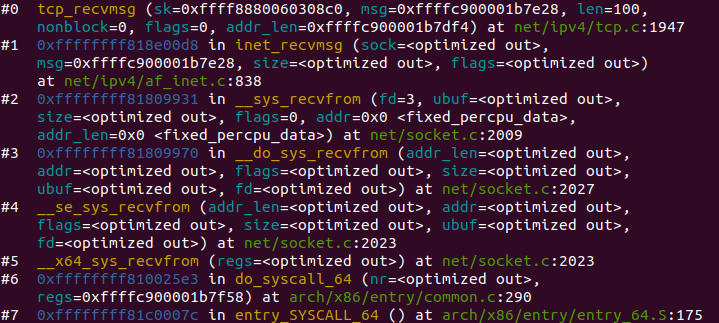
每当用户应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
对于 INET 类型的 socket,/net/ipv4/af inet.c 中的 inet_recvmsg 方法会被调用,它会调用相关协议的数据接收方法。
对 TCP 来说,调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
对 UDP 来说,从 user space 中可以调用三个 system call recv()/recvfrom()/recvmsg() 中的任意一个来接收 UDP package,这些系统调用最终都会调用内核中的 udp_recvmsg 方法。
传输层的最终目的是向它的用户提供高效的、可靠的和成本有效的数据传输服务,主要功能包括 (1)构造 TCP segment (2)计算 checksum (3)发送回复(ACK)包 (4)滑动窗口(sliding windown)等保证可靠性的操作。
TCP 栈简要过程:
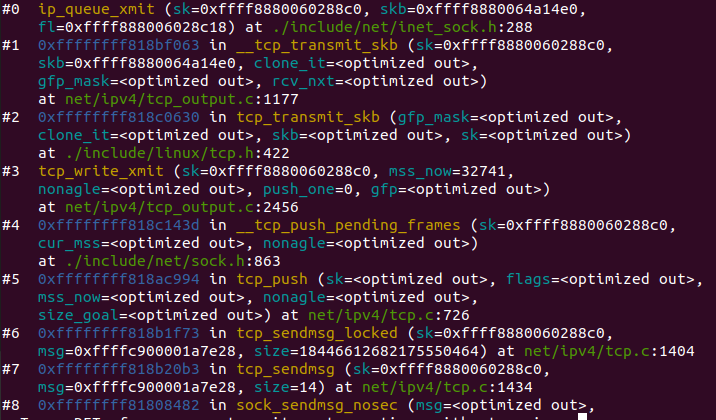
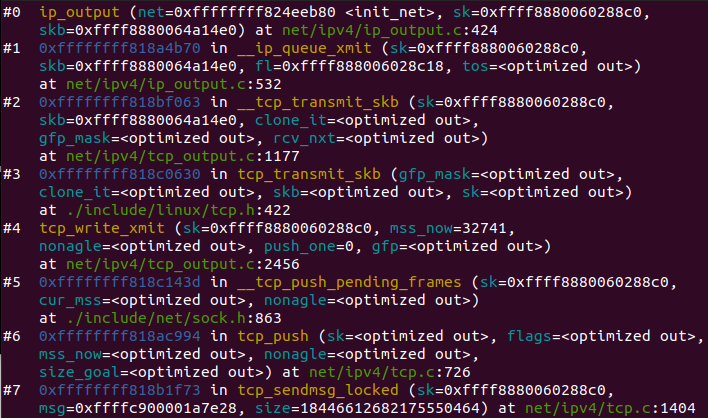
tcp_sendmsg 函数会首先检查已经建立的 TCP connection 的状态,然后获取该连接的 MSS,开始 segement 发送流程。
构造 TCP 段的 playload:它在内核空间中创建该 packet 的 sk_buffer 数据结构的实例 skb,从 userspace buffer 中拷贝 packet 的数据到 skb 的 buffer。
构造 TCP header。
计算 TCP 校验和(checksum)和 顺序号 (sequence number)。
TCP 校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现TCP首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则TCP段会被直接丢弃。TCP校验和覆盖 TCP 首部和 TCP 数据。
TCP的校验和是必需的
发到 IP 层处理:调用 IP handler 句柄 ip_queue_xmit,将 skb 传入 IP 处理流程。
UDP 栈简要过程:
UDP 将 message 封装成 UDP 数据报
调用 ip_append_data() 方法将 packet 送到 IP 层进行处理。
以TCP为例,可得如下图所示:
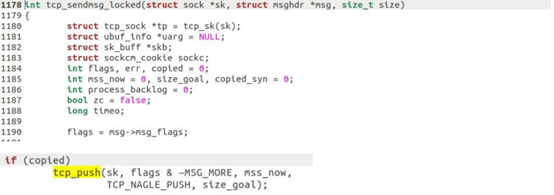
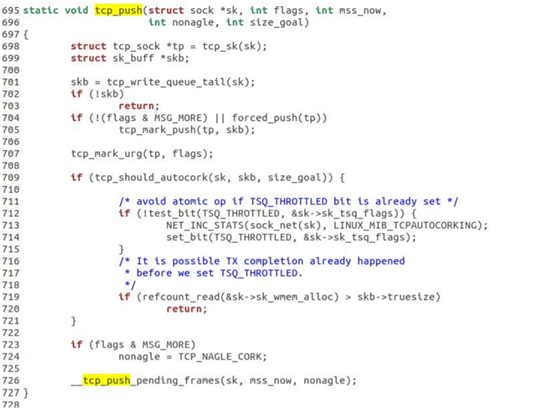
相应部分函数代码截图下:



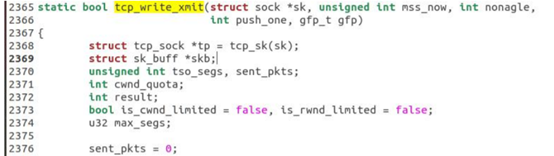
传输层 TCP 处理入口在 tcp_v4_rcv 函数(位于 linux/net/ipv4/tcp ipv4.c 文件中),它会做 TCP header 检查等处理。
调用 _tcp_v4_lookup,查找该 package 的 open socket。如果找不到,该 package 会被丢弃。接下来检查 socket 和 connection 的状态。
如果socket 和 connection 一切正常,调用 tcp_prequeue 使 package 从内核进入 user space,放进 socket 的 receive queue。然后 socket 会被唤醒,调用 system call,并最终调用 tcp_recvmsg 函数去从 socket recieve queue 中获取 segment。
网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。其主要任务包括 (1)路由处理,即选择下一跳 (2)添加 IP header(3)计算 IP header checksum,用于检测 IP 报文头部在传播过程中是否出错 (4)可能的话,进行 IP 分片(5)处理完毕,获取下一跳的 MAC 地址,设置链路层报文头,然后转入链路层处理。
IP 栈基本处理过程如下:
首先,ip_queue_xmit(skb)会检查skb->dst路由信息。如果没有,比如套接字的第一个包,就使用ip_route_output()选择一个路由。
接着,填充IP包的各个字段,比如版本、包头长度、TOS等。
中间的一些分片等,可参阅相关文档。基本思想是,当报文的长度大于mtu,gso的长度不为0就会调用 ip_fragment 进行分片,否则就会调用ip_finish_output2把数据发送出去。ip_fragment 函数中,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发送一个原因为需要分片而设置了不分片标志的目的不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
接下来就用 ip_finish_ouput2 设置链路层报文头了。如果,链路层报头缓存有(即hh不为空),那就拷贝到skb里。如果没,那么就调用neigh_resolve_output,使用 ARP 获取。
下图为相关函数的运行流程:
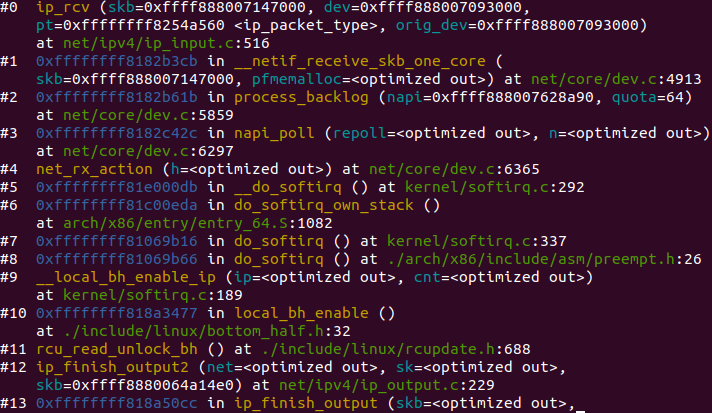
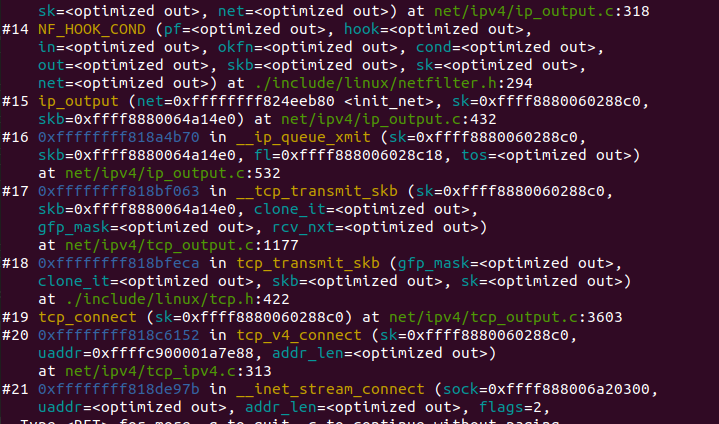
IP 层的入口函数在 ip_rcv 函数。该函数首先会做包括 package checksum 在内的各种检查,如果需要的话会做 IP defragment(将多个分片合并),然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
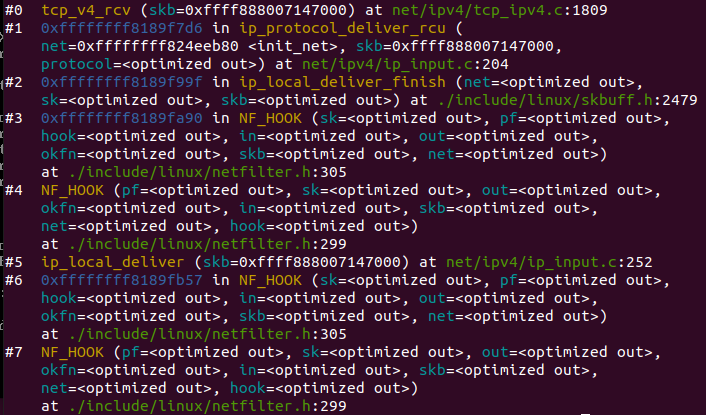
ip_rcv_finish 函数会调用 ip_router_input 函数,进入路由处理环节。它首先会调用 ip_route_input 来更新路由,然后查找 route,决定该 package 将会被发到本机还是会被转发还是丢弃:
如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment(合并多个 IP packet),然后调用 ip_local_deliver 函数。该函数根据 package 的下一个处理层的 protocal number,调用下一层接口,包括 tcp_v4_rcv (TCP), udp_rcv (UDP),icmp_rcv (ICMP),igmp_rcv(IGMP)。对于 TCP 来说,函数 tcp_v4_rcv 函数会被调用,从而处理流程进入 TCP 栈。
如果需要转发 (forward),则进入转发流程。该流程需要处理 TTL,再调用 dst_input 函数。该函数会 处理 Netfilter Hook;执行 IP fragmentation;调用 dev_queue_xmit,进入链路层处理流程。
功能上,在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。在这一层,数据的单位称为帧(frame)。数据链路层协议的代表包括:SDLC、HDLC、PPP、STP、帧中继等。实现上,Linux 提供了一个 Network device 的抽象层,其实现在 linux/net/core/dev.c。具体的物理网络设备在设备驱动中(driver.c)需要实现其中的虚函数。Network Device 抽象层调用具体网络设备的函数。
物理层在收到发送请求之后,通过 DMA 将该主存中的数据拷贝至内部RAM(buffer)之中。在数据拷贝中,同时加入符合以太网协议的相关header,IFG、前导符和CRC。对于以太网网络,物理层发送采用CSMA/CD,即在发送过程中侦听链路冲突。一旦网卡完成报文发送,将产生中断通知CPU,然后驱动层中的中断处理程序就可以删除保存的 skb 了。
一个 package 到达机器的物理网络适配器,当它接收到数据帧时,就会触发一个中断,并将通过 DMA 传送到位于 linux kernel 内存中的 rx_ring。
网卡发出中断,通知 CPU 有个 package 需要它处理。中断处理程序主要进行以下一些操作,包括分配 skb_buff 数据结构,并将接收到的数据帧从网络适配器I/O端口拷贝到skb_buff 缓冲区中;从数据帧中提取出一些信息,并设置 skb_buff 相应的参数,这些参数将被上层的网络协议使用,例如skb->protocol;
终端处理程序经过简单处理后,发出一个软中断(NET_RX_SOFTIRQ),通知内核接收到新的数据帧。
内核 2.5 中引入一组新的 API 来处理接收的数据帧,即 NAPI。所以,驱动有两种方式通知内核:(1) 通过以前的函数netif_rx;(2)通过NAPI机制。该中断处理程序调用 Network device的 netif_rx_schedule 函数,进入软中断处理流程,再调用 net_rx_action 函数。
该函数关闭中断,获取每个 Network device 的 rx_ring 中的所有 package,最终 pacakage 从 rx_ring 中被删除,进入 netif _receive_skb 处理流程。
netif_receive_skb 是链路层接收数据报的最后一站。它根据注册在全局数组 ptype_all 和 ptype_base 里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数(INET域中主要是ip_rcv和arp_rcv)。该函数主要就是调用第三层协议的接收函数处理该skb包,进入第三层网络层处理。
标签:package ber pie inux cas crc 使用 伯克利 网络传输
原文地址:https://www.cnblogs.com/szp123456/p/14295190.html