标签:位置 term 指令 assert 字节 tor 类对象 检测 center
[x] 基本类型的内存占用
| 数据类型 | 32位 | 64位 | 取值范围(32位) |
|---|---|---|---|
| char | 1 | 1 | -128~127 |
| unsigned char(当byte使用) | 1 | 1 | 0~255 |
| short int /short | 2 | 2 | –32,768~32,767 |
| unsigned short | 2 | 2 | 0~65,535 |
| int | 4 | 4 | -2,147,483,648~2,147,483,647 |
| unsigned int | 4 | 4 | 0~4,294,967,295 |
| long int /long | 4 | 8 | –2,147,483,648~2,147,483,647 |
| unsigned long | 4 | 8 | 0~4,294,967,295 |
| long long int/long long | 8 | 8 | -9,223,372,036,854,775,808~9,223,372,036,854,775,807 |
| 指针 | 4 | 8 | |
| float | 4 | 4 | 3.4E +/- 38 (7 digits) |
| double | 8 | 8 | 1.7E +/- 308 (15 digits) |
[x] 内存分配的每一层面
[x] C++ memory primitves
| 分配 | 释放 | 类型 | 可否重载 |
|---|---|---|---|
malloc |
free |
C函数 | 不可 |
new |
delete |
C++表达式 | 不可 |
::operator new |
::operator delete |
C++函数 | 可 |
allocator<T>::allocate |
allocator<int>::deallocate |
C++标准库 | 可自由设计并以之搭配任何容器 |
上述函数用法:
void primitives_sample() {
//CRT运行时函数
void *p1 = malloc(512);
free(p1);
//new
complex<int>* p2 = new complex<int>;
delete p2;
//::operator new(全局函数,可被重载)
void* p3 = ::operator new(sizeof(int)); //内部调用malloc
::operator delete(p3); //内部调用delete
// allocator分配器(STL容器分配内存的方式) 7代表要7个ints而不是7个直接
void* p4 = allocator<int>().allocate(7);
allocator<int>().deallocate((int*)p4, 7);//还的时候当初要的数量也得还回去
return;
}
malloc/free分配细节:
new/delete探究
new expression
delete expression
operator new
调用malloc
operator delete
new/delete编译器自动生成的代码实现:
//调用new的时候,编译器生成的代码
primitives_new_delete* new_override() {
primitives_new_delete* pc;
try {
void *mem = operator new(sizeof(primitives_new_delete)); //分配内存
pc = static_cast<primitives_new_delete*>(mem); //指针转换
//pc->primitives_new_delete::primitives_new_delete(1, 2); //实际上是这样,但是编译器不支持。指针不可直接调用构造函数
/*
欲直接调用ctor,则使用placement new:
new(p) primitives_new_delete(1, 2);
*/
new(pc) primitives_new_delete(1, 2); //直接调用构造函数(placement new)
return pc;
}catch(std::bad_alloc) {
cout << "Bad Allocation" << endl;
}
return nullptr;
}
//调用delete的时候,编译器生成的代码
void delete_override(primitives_new_delete* pc) {
pc->~primitives_new_delete(); //指针可直接调用析构函数
operator delete(pc); //释放内存
}
Ctor & Dtor 直接调用
//工具人class
class A {
public:
int id;
A(int _id) : id(_id){
cout << "ctor.this = " << this << " id = " << endl;
}
~A() {
cout << "dtor.this = " << this << " id = " << endl;
}
};
static void TEST_Ctor_Dtor() {
string* pstr = new string;
cout << "str = " << *pstr << endl;//先打印一下证明真的拿到了
/*
不能直接调用构造函数
原因:
typedef basic_string string //即string的真正类型是basic_string
*/
//pstr->string::string("jjhou");
//可以直接调用析构
pstr->~string();
A* pA = new A(1);
cout << " id = " << pA->id << endl;
//pA->A::A(3); //直接调用构造函数 //VC6老版本成功了,GC和新版本都GG,所以无法直接调用构造函数,要真的想直接调就用placement_new
}
数组new[]/delete[]探究
new object[]/delete[] object(本质调用malloc/delete)
如果调用了new[]而释放的时候调用的是delete而不是delete[]就会发生内存泄漏,但是不是我们以为的new[]了N个内存,释放只释放了第一个,本质上new出来的对象指向的并不是内存地址而是这一组内存对应的cookie,本质上cookie记录了free本身需要释放的内存大小,所以通过delete也会根据cookie将对应的资源还给操作系统,并不会发生内存泄漏。而真正的泄露发生在调用的析构函数次数上,如果一个成员变量不带指针,没有特定的复写析构函数,那么这个析构是不重要的,调用不调用没区别则不会发生内存泄漏,如果object拥有带指针的成员变量,则意味着析构函数是重要的,需要在析构函数中将指针所引用的内存释放,而delete则会影响析构函数的调用次数,只会调用一次析构,即第一个对象的析构或者最后一个对象的析构(具体是哪个看编译器实现,各家不一样),而其他对象的析构就不会被调用,所以new[]不对应delete[]的话会影响指针指向的内存部分的泄露。
且上述还有一个细节,见下述代码
int* pi = new int[10];//sizeof(pi) = 4
delete pi;//能被释放,且因为没有指针对象,这块的pi指向的是第一个元素内存的地址
class Complex{
public:
int id;
Complex(int _id) : id(_id) {
cout << "default ctor is. " << this << " id = " << id << endl;
}
Complex() : id(0) {
}
~Complex() {
cout << "dtor is. " << this << " id = " << id << endl;
}
};
static void TEST_ARRAY_NEW_DELETE(int size) {
Complex* buf = new Complex[size]; //必须有默认构造函数
Complex* tmp = buf;
cout << "buf = " << buf << " tmp = " << tmp << endl;
for(int i = 0 ; i < size; i ++) {
new (tmp++)Complex(i); //replacemennt new
}
cout << "buf = " << buf << "tmp = " << tmp << endl;
/*
delete pi; 当new[]的对象的析构被重新定义是有意义的时候,他在分配内存时还会在数据头加上一个值表示new出来的长度,这里就是10,pi指向的也是这个10,这时候delete就会编译报错
dtor is. 0x1304e78 id = 0(只释放的第一个)
munmap_chunk(): invalid pointer 无效的指针 (就代表指向的是那个new出来的长度,这里我又做了个测试,吧析构注释了,在运行就并没有报错,佐证了上述解释)
*/
delete []buf; //从最后一个往上进行释放
}
int main(void)
{
TEST_ARRAY_NEW_DELETE(3);
return 0;
}
/*
buf = 0x1835e78 tmp = 0x1835e78
default ctor is. 0x1835e78(8609400) id = 0
default ctor is. 0x1835e7c(8609404) id = 1
default ctor is. 0x1835e80(8609408) id = 2
buf = 0x1835e78tmp = 0x1835e84
dtor is. 0x1835e80 id = 2
dtor is. 0x1835e7c id = 1
dtor is. 0x1835e78 id = 0
*/
Replacement new
允许我们将对象建构在已经分配好的内存上
没有所谓的placement delete,因为placement new根本不分配内存!
不会在分配内存(定点内存)
//调用placement new 的编译器生成的代码
void *mem = operator new(sizeof(Complex), buf); //重载
pc = static_cast<Complex*>(mem);
//pc->Complex::Complex(1,2); //构造函数
具体用法上面代码块里我用了,可以看看
重载全局的::operator
operator_new重载
重载operator new(本质上就是placement new)
写法:
/*
重载类内operator new/delete
*/
class Foo{
public:
int _id;
long _data;
string _str;
public:
Foo() : _id(0) {
cout << "default ctor. this = " << this << "id = " << _id << endl;
}
Foo(int i) : _id(i) {
cout << "ctor.this = " << this << "id = " << _id << endl;
}
~Foo() {
cout << "dtor.this = " << this << " id = " << _id << endl;
}
//这些函数必须是静态函数, 因为这是编译器在创建对象时调用的,这时候对象都没有,不可能调用成员函数,所以必须是静态的,也正是因为必须是静态的,如果这些方法没加静态编译器也会自动加上,所以写的时候有些地方没加static,但是最后编译生成的肯定是静态的方法
static void *operator new(size_t size){
Foo *p = (Foo*) malloc(size);
cout << "Foo new()" << endl;
return p;
}
static void operator delete(void* pdead, size_t) {
cout << "Foo delete()" << endl;
free(pdead);
}
static void* operator new[](size_t size){
Foo* p = (Foo*)malloc(size);
cout << "Foo new()" << endl;
return p;
}
void operator delete[] (void * pdead, size_t) {
cout << "Foo delete()" << endl;
free(pdead);
}
};
重载new()/delete()
operator new和placement new的区别
两个都是重载operator new()这个函数签名
但是operator new的参数是operator new(size_t size)
而placement new的参数是operator new(size_t size, void* ptr);
new(p)就是placement new,被称为定点new, 而功能是并不分配内存
class Foo{
public:
Foo() {
cout << "Foo:::Foo()" << endl;
}
Foo(int ) {
cout << "Foo::Foo(int)" << endl;
throw Bad();
}
//一般的operator new()的重载
void* operator new(size_t size) {
cout << "operator new(size_t)" << endl;
return malloc(size);
}
//标准库已提供的placement new()的重载
//当ctor发出异常,下面对应的operator delete就会被调用(其作用就是释放相应的内存)
void* operator new(size_t size, void * start) {
cout << "operator nen(size_t, void*)" << endl;
return start;
}
void* operator new(size_t size, long extra) {
cout << "operator new(size_t, long)" << endl;
return malloc(size + extra);
}
void* operator new(size_t size, long extra, char init) {
cout << "operator new(size_t, long, char)" << endl;
return malloc(size + extra);
}
//相应的delete重载函数
void operator delete(void*, size_t size) {
cout << "operator delete(void*, size_t)" << endl;
}
void operator delete(void*, void*) {
cout << "operator delete(void*, void*)" << endl;
}
void operator delete(void*, long) {
cout << "operator delete(void*, long)" << endl;
}
void operator delete(void*, long, char) {
cout << "operator delete(void*, long, char)" << endl;
}
private:
int m_i;
};
per_class_allocator
为什么要为类写内存分配器?
allocator1.0:
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
/*
通过Screen和Screen_new两个类来测试重载operator new对cookie的影响
结论: Clang两个版本都不带cookie,大小和间隔都是16
GCC 分配区别明显
注意: 在写程序的时候,一定要注意virtual机制带来的内存浪费
优点: 内存池,减少malloc调用次数
缺点: 引入next指针,没有调用free,如果对象是一个int,加上next指针导致内存膨胀率变成了百分百。且不释放资源就会导致这块内存一直被占用
*/
class Screen{
public:
Screen(long x) : i(x){}
~Screen() {}
int get() {return i;}
private:
Screen* next;//32 4 ,64 8
static Screen* freeStore;
static const int screenChunk;
private:
long i; //8
};
class Screen_override
{
public:
Screen_override (int x) : i(x) {}
~Screen_override () {}
int get() {return i;}
//重载
static void* operator new(size_t);
static void operator delete(void*, size_t);
private:
Screen_override* next;//32 4字节 64 8字节
static Screen_override* freeStore;
static const int screenChunk;
private:
int i; //4字节
//64位电脑上 4+8加上内存对其到16位 所以size是16
};
Screen_override* Screen_override::freeStore = 0; //最开始的头结点
const int Screen_override::screenChunk = 5; //这里写了5 所以5个以后不够就要继续去挖
/*
@operator new
逻辑是当freeStore空的时候分配5个
当freeStore不空的时候,从Chunk中取next
*/
void *Screen_override::operator new(size_t size) { //size为元素大小,一次分配5个
Screen_override* p;
if(!freeStore) {
//linked list 是空的,申请一大块
size_t chunk = screenChunk* size;
freeStore = p = reinterpret_cast<Screen_override*>(new char[chunk]);
//将这一块分割成片,当做linked list串接起来
for(; p != &freeStore[screenChunk - 1]; ++p) {
p->next = p + 1;
}
p->next = 0;
}
p = freeStore;
freeStore = freeStore->next;
return p;
}
/*
将deleted object 插回到free list前端
*/
void Screen_override::operator delete(void* p, size_t) {
(static_cast<Screen_override*>(p))->next = freeStore;
freeStore = static_cast<Screen_override*>(p);
}
//测试不重载operator new,分配内存带cookie
void TEST_WITH_COOKIE(){
cout << endl << "TEST_WITH_COOKIE" << endl;
//32位系统下,16字节,4(Alignment) +8(Screen*) +4(Alignment) ; static 成员变量并不算在对象中
//64位系统下,32字节,8(Alignment) +16(Screen*) +8(Alignment) ; static 成员变量并不算在对象中
cout << "size of Screen: " << sizeof(Screen) << endl;
int const N = 100;
Screen* p[N];
for(int i = 0; i < N; i ++) {
p[i] = new Screen(i);
}
for(int i =0 ; i < 10; i ++) {
cout << p[i] << endl;
}
for(int i = 0;i < N; i ++){
delete p[i];
}
return;
}
//重载operator new, 分配内存不带cookie
void TEST_NO_COOKIE(void)
{
cout << endl << "TEST_NO_COOKIE...." << endl;
//16字节
cout << "size of Screen_override: " << sizeof(Screen_override) << endl;
int const N = 100;
Screen_override* p[N];
for(int i =0 ; i < N; i ++) {
p[i] = new Screen_override(i);
}
for(int i =0 ; i < 10; i ++) {
cout << p[i] << endl;
}
for(int i =0 ; i < N; i ++) {
delete p[i];
}
return;
}
int main(void)
{
TEST_WITH_COOKIE();
TEST_NO_COOKIE();
return 0;
}
/*
TEST_WITH_COOKIE
size of Screen: 16
0x89fe80 9043584
0x89fea0 9043616
0x89fec0 9043648
0x89fee0 9043680
0x89ff00 9043712
0x89ff20 9043744
0x89ff40 9043776
0x89ff60 9043808
0x89ff80 9043840
0x89ffa0 9043872
间隔 32 64位系统 一个cookie是8,头尾是16
TEST_NO_COOKIE....
size of Screen_override: 16
0x8a0b00 9046784
0x8a0b10 9046800
0x8a0b20 9046816
0x8a0b30 9046832
0x8a0b40 9046848
//这里间隔32 代表新new了一个复合对象 头尾cookie+16
0x8a0b60 9046880
0x8a0b70 9046896
0x8a0b80 9046912
0x8a0b90 9046928
0x8a0ba0 9046944
*/
allocator2.0 ( 类的内存分配器精简版本)
优点: next指针借用了分配的空间大小来当指针,当这个内存没被分配的时候,这个指针就用来关联内存池中各个内存块,当这个内存被分配出去被外部使用时,外部将自己的具体值写入,覆盖了这个临时指针有关系吗?没有,因为这东西已经借出去了,所以也就不在池中了,没必要维护和内存池的关系了,随便外部干嘛,等到还回来的时候,诶嘿,我再拿前面的几个字节来当指针用,完美。所以这么设计非常巧妙的剩下了指针的空间,利用了类原本的空间大小,没有膨胀率。但是有个要求,当对象大小要大于借用的指针大小(32位4,64位8),如果没有这么大那么就无法用这个策略被内存池管理。
缺点: 内存池最终delete后还是和1.0一样并没有还给OS ,并没有调用free(不是内存泄漏,就是自己缓存了这么一大块内存)
class Airplane
{
public:
Airplane (){}
~Airplane (){}
private:
//声明
struct AirplaneRep{
unsigned long miles; //8字节
char type; //1字节
//总大小9 - > 16 对齐到16
};
private:
//定义:union的巧妙之处,在于未正式分配的是时候借用其中的8个字节作为指针,这是主流的分配器实现必须要做的,不然就很低级。
union { //16字节 Embedded Pointer
AirplaneRep rep; //这个就是对应具体的对象
Airplane* next; //这个是把它看成一个指针,用来针对free list上的对象,就是回收池中的对象
};
public:
unsigned long getMiles() {return rep.miles;}
char getType() {return rep.type;}
void set(unsigned long m, char t) {
rep.miles = m;
rep.type = t;
}
public:
static void* operator new(size_t size);
static void operator delete(void* deadObj, size_t size);
private:
static const int BLOCK_SIZE;
static Airplane* headOfFreeList;
};
Airplane* Airplane::headOfFreeList;
const int Airplane::BLOCK_SIZE = 512;
//重载
void* Airplane::operator new(size_t size) {
if(size != sizeof(Airplane)) { //继承发生就会有问题
return ::operator new(size);
}
Airplane* p = headOfFreeList;
if(p){
headOfFreeList = p->next; //如果P有效就把头移动到下个元素,p返回去(从池子里拿)
}else{
Airplane* newBlock = static_cast<Airplane*>(::operator new(BLOCK_SIZE * sizeof(Airplane))); //申请一大块
//切成一片片,和上面的区别是这个指针是借用的
for(int i = 1; i < BLOCK_SIZE - 1; i ++)
newBlock[i].next = &newBlock[i+1];
newBlock[BLOCK_SIZE - 1].next = 0;
p = newBlock;//拿第一个还回去
headOfFreeList = &newBlock[1];
}
return p;
}
//重载
void Airplane::operator delete(void* deadObj, size_t size) {
if(!deadObj) return;
if(size != sizeof(Airplane)) { //继承情况的时候不加校验这里会出问题
::operator delete(deadObj);
return;
}
//转回指针,回池
Airplane* carcass = static_cast<Airplane*>(deadObj);
carcass->next = headOfFreeList;
headOfFreeList = carcass;
}
int main(void)
{
//cout << sizeof(unsigned long) << endl; 8Bytes
//cout << sizeof(Airplane*) << endl; 8Bytes
cout << sizeof(Airplane) << endl; //16字节
size_t const N = 100;
Airplane* p[N];
for(size_t i = 0; i < N; i ++) {
p[i] = new Airplane;
}
p[1]->set(1000, ‘A‘);
p[2]->set(2000, ‘B‘);
p[3]->set(3000, ‘C‘);
for(int i = 0; i < 10; i ++) {
cout << p[i] << endl;
}
for(size_t i = 0; i < N; i ++) {
delete p[i];
}
return 0;
}
static allocator 3.0+4.0对象内存池
这个原理和2.0一样,只是在使用上不必为不同的class重写一遍相同的member operator new/delete , 解决办法就是将allocator抽象成一个类 ,然后为了省事就用macro包起来就方便写了 MFC就这么偷懒
//DECLAREE_POOL_ALLOC-- used in class definition
#define DECLARE_POOL_ALLOC() public: void* operator new(size_t size) {return myAlloc.allocate(size);} void operator delete(void* p) {return myAlloc.deallocate(p, 0);} public: static my_allocator myAlloc;
//IMPLEMENT_POOL_ALLOC -- used in class implementation file
#define IMPLEMENT_POOL_ALLOC(class_name) my_allocator class_name::myAlloc
class my_allocator{
public:
struct obj{
struct obj* next;
};
public:
my_allocator() {}
~my_allocator() {}
public:
void* allocate(size_t);
void deallocate(void* p, size_t);
//private:
obj* freeStore = nullptr;
int const CHUNK = 5;
};
void* my_allocator::allocate(size_t size) {
cout << "allocating..." << endl;
obj* p;
if(!freeStore) {
freeStore = p = static_cast<obj*>(malloc(size * CHUNK));
for(int i = 1; i < CHUNK - 1; i ++) {
p->next = static_cast<obj*>(p + size);
p = p->next;
}
p->next = nullptr;
}
p = freeStore;
freeStore = freeStore->next;
return p;
}
void my_allocator::deallocate(void* p, size_t) {
static_cast<obj*>(p)->next= freeStore;
freeStore = static_cast<obj*>(p);
}
class Foo{
DECLARE_POOL_ALLOC();
public:
long L;
string str;
public:
Foo(long _L) : L(_L) {}
};
IMPLEMENT_POOL_ALLOC(Foo);
class Goo{
DECLARE_POOL_ALLOC();
public:
complex<double> c;
std::string str;
public:
Goo(const complex<double>& l) : c(l) {}
};
IMPLEMENT_POOL_ALLOC(Goo);
int main(void)
{
Foo* p[10];
cout << "sizeof(Foo)" << sizeof(Foo) << endl;
for(int i =0 ; i < 5; i ++) {
p[i] = new Foo(static_cast<long>(i));
cout << p[i] << endl;
}
for(int i = 0; i < 5; i ++) {
delete p[i];
}
return 0;
}
[x] new handler/default/delete探究
[x] 空类的占用的内存
[x] Std::allocator
主流平台的分配器实现
VC6.0和BorlandC5.0这两个著名的编译器标准库内部实现中,每个容器的std::allocater都是通过::operator new/delete来完成的——本质就是直接调用malloc其他什么都没有做。而GNU2.9 C++中使用的版本是std::alloc——使用了诸如pool等高级的分配逻辑,在经过更新迭代后在GNU4.9中改名为__gnu_cxx::__pool_alloc——也是本章的重点关注对象。
GNU2.9中的std::alloc内存分配流程:
size容器所申请的对象大小;chunk分配器提供的内存单元——共16个。
维护16条长度各异(第n条链表一次分配的chunk大小为:8*(n + 1)Bytes,)的自由链表,超过能分配最大的内存单元(8*16 = 128)会申请malloc。所有使用malloc的申请对象都会带cookie。
分配器会将申请的内存size按照分配单元调整到合适的边界(比如std::alloc是8的倍数,malloc也会调整)
拿到一个申请的size需要分配的对象,首先定位它在分配器上的指针端口。然后查看是否有战备池的内存可以用,如果有直接使用,这时候一般分配的数量是1~20个chunk。没有则调用malloc分配。第一次分配pool为零,则直接调用malloc。
分配器调用malloc分配大小为size * 20 * 2 +ROUNDUP(memory_allocated >> 4); 其中会有20个chunk是为申请的对象准备的,剩下的内存(并不会分割)作为战备池为以后的分配器行为做准备——这是一个很重要的概念,分配全程需要关注战备区pool的容量。 其中ROUNDUP()是对齐函数,memory_allocated是已经分配好的内存总量。随着内存分配操作越来越多,memory_allocated也是越来越大——符合计算机内存分配越来越多的增长趋势,>>4就是除以16,为什么加这个额外申请空间,这应该是gnu里面开发的经验值,没有解释。
如果战备池剩下的内存小于要分配的size,那剩下的这一小块pool则被看成是碎片——计算应该放在那个链表后就会挂到相应的链表头指针上,作为多出来的备用item。
如果malloc系统内存分配失败,则需要在最接近的大于size的已分配好的空闲chunk中回填pool,完成分配。如果向上走也无法分配成功,那系统分配才算完全失败。
由于一次性分配20个chunk,而每一次分配必须按照其size来选择链表头结点,所以有很大概率某些指针上的空闲chunk就会比较多。而std::alloc对chunk的选择一定是大于等于size的。从技术的角度,将这些空闲的chunk合并在一起难度非常大。
分配器面向的用户是容器——元素一样大的集合,如果用户直接使用分配器,就必须记住分配的大小。这是因为自主分配的内存不会带cookie,而容器的第一个目标参数都会是参数类型,只要sizeof一下就可以计算出来所申请的size。
#include <iostream>
#include <algorithm>
#include <cstring>
#include <list>
using namespace std;
/*
上述概念的精简版实现
重点理解:
备战池,内存对齐,内存碎片
*/
/*
一级分配器
*/
class alloc_pri{
public:
static void* allocate(size_t size) {
void* result = malloc(size);
return result;
}
static void deallocate(void* p, size_t) {
free(p);
}
};
typedef alloc_pri malloc_alloc;
/*
二级分配器
*/
class alloc_default{
private:
//链表指标
static const int _align = 8;
static const int _max = 128;
static const int _list = _max / _align;
//嵌入式指针
union obj{
union obj* next;
};
private:
//链表元素
static obj* free_list[_list];
static char* start_free;
static char* end_free;
static size_t heap_size;
//工具函数
static size_t FREELIST_INDEX(size_t bytes);
static size_t ROUND_UP(size_t bytes);
//核心函数
static void* refill(size_t size);
static char* chunk_alloc(size_t, int &);
public:
//分配函数
static void* allocate(size_t);
static void deallocate(void*, size_t);
static void realloc(void* p, size_t, size_t);
};
/*类静态变量定义*/
char* alloc_default::start_free = 0;
char* alloc_default::end_free = 0;
size_t alloc_default::heap_size = 0;
alloc_default::obj* alloc_default::free_list[_list]
= {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0}; //16 chunks
/************分配函数实现
和6per_class_allocator的分配算法完全一样
*/
void* alloc_default::allocate(size_t size) {
obj** my_free_list; //指向内存池链表的的指针
obj* result;
//当需要申请的size大于allocator的最大chunk的时候, 直接调用一级分配器————>malloc()
if(size > _max)
return (malloc_alloc::allocate(size));
//根据申请的size判断内存池相应的指针端口
my_free_list = free_list + FREELIST_INDEX(size);
result = *my_free_list;
//如果链表为空 如果第一次或者List被用光了,则result为空
if(!result) {
void* t = refill(ROUND_UP(size));
return t;
}
//如果有可用区块,分配
*my_free_list = result->next;
return result;
}
void alloc_default::deallocate(void* p, size_t size) {
obj* q = static_cast<obj*>(p);
//当需要销毁的size大于deallocator的最大chunk的时候, 直接调用一级分配器————>free()
if(size > _max) {
malloc_alloc::deallocate(p, size);
return;
}
obj** my_free_list = free_list + FREELIST_INDEX(size);
q->next = *my_free_list;
*my_free_list = q;
}
/**************工具函数实现
纯粹数学计算/理解向上取整
*/
size_t alloc_default::FREELIST_INDEX(size_t bytes) {
return ((bytes + _align - 1) / _align - 1);
}
size_t alloc_default::ROUND_UP(size_t bytes) {
return (bytes + _align) & ~(_align - 1);
}
/********************核心函数
@功能:
充值
*/
void* alloc_default::refill(size_t size) {
int nobjs = 20;
char* chunk = chunk_alloc(size, nobjs); // 不一定是20个 如果备战池为零,则重新分配20个chunk,而备战池有内存资源,则不一定分配20个
if(1 == nobjs) return(chunk); //如果分配了一个,则直接返回
//定位
obj** my_free_list = free_list + FREELIST_INDEX(size);
obj* result = (obj*)chunk; //确定好了需要分配的一块
//将分配好的内存chunk链接到相应的指针端口,并初始化next_obj
obj* current_obj, *next_obj;
*my_free_list = next_obj = (obj*)(chunk + size);
//利用嵌入式指针完成分配的内存的链表化
for(int i = 1; ; i ++) {
current_obj = next_obj;
next_obj = (obj*)((char*)next_obj + size);
if(i == nobjs - 1) {
current_obj->next = nullptr;
break;
}else {
current_obj->next = next_obj;
}
}
return (result);
}
/*
@功能
按照申请的size,如果分配器的chunk都小于等于size;诉求第一级分配器即malloc
然后确定需要挂载的chunk区块,如果战备池有空闲的内存则直接分配,没有的话调用
refill()在周边区块上补充
而chunk_alloc()函数是备战池内存分配的核心逻辑
*/
char* alloc_default::chunk_alloc(size_t size, int& nobjs) {
size_t total_bytes = size * nobjs;
size_t bytes_left = end_free - start_free;
char* result;
if(bytes_left >= total_bytes) { //pool空间满足申请内存
result = start_free;
start_free += total_bytes;
return (result);
}else if(bytes_left >= size) { //pool空间满足一块以上
nobjs = bytes_left / size; //改变需求
total_bytes = size * nobjs;
result = start_free;
start_free += total_bytes;
return (result);
}else { //pool空间不满足(碎片)
size_t bytes_to_get = 2 * total_bytes + ROUND_UP(heap_size >> 4);
//处理碎片(将其挂到相应的chunk指针端口)
if(bytes_to_get > 0) {
obj** my_free_list = free_list + FREELIST_INDEX(bytes_left);
((obj*)start_free)->next = *my_free_list;
*my_free_list = (obj*)start_free;
}
//开始从system-heap上分配内存
start_free = (char*)malloc(bytes_to_get);
if(0 == start_free) { //如果当前chunk没有分配成功,则向上继续找chunk分配
obj** my_free_list, *p;
for(int i = size; i <= _max; i += _align) {
my_free_list = free_list + FREELIST_INDEX(i);
p = *my_free_list;
if(0 != p) {
*my_free_list = p->next;
start_free = (char*)p;
end_free = start_free + i;
return (chunk_alloc(size, nobjs));
}
}
end_free = 0;
start_free = (char*)malloc_alloc::allocate(bytes_to_get);
}
heap_size += bytes_to_get;
end_free = start_free + bytes_to_get;
return (chunk_alloc(size, nobjs)); //备战池有内存了,所以递归重新处理分配逻辑
}
}
typedef alloc_default alloc;
class Foo{
public:
int m;
};
int main(void)
{
//Foo(1)是stack memory, 而当需要push_back的时候,alloc需要准备一块内存
list<Foo, alloc> c; //不带cookie
c.push_back(Foo(1)); //push_back 需要拷贝构造
//p是heap memory, 容器向分配器发出需求,alloc为其分配内存
Foo* p = new Foo(2); //带cookie
c.push_back(*p); //push_back 需要拷贝构造
delete p;
return 0;
}
[x] malloc
Windows下VC6.0中C++程序的流程(简化版)——伪码中的API都是Windows平台下的。执行流程是前一个函数调用后一个函数。需要有OS-虚拟内存的基础。
mainCRTStartup(); //由C Runtime Library
/*
系统启动最初由HeapAlloc分配4096字节并传给指针_crtheap,并建立16个Header。接着第一个Header的一个指针利用VirtualAlloc(0, 1Mb, MEM_RESERVE)函数向操作系统直接申请了1MB的虚拟地址空间(并不分配内存),另外一个指针从_crtheap中又分配了sizeof(region)大小的内存用来建立管理中心。
总结一下,最开始进行了两种操作,一个操作是真正的向OS要了4KB的物理内存_crtheap,用来建立region控制中心和16个Header——这里用的是API是HeapAlloc();而另一个操作是作为控制中心的region申请了1MB的虚拟地址空间(注意这里并没有直接分配内存)——用的API是VirtualAlloc()。这一切操作都是在ioinit函数真正申请内存之前就完成了。
*/
_heap_init()
_ioinit() 第一次尝试申请内存共100h
_heap_alloc_dbg() 调试模式下
typedef struct _CrtMemBlockHeader{ //在debug模式下准备附加到所申请的内存之上的 所以在debug模式下分配的内存会比申请的内存大一些
struct _CrtMemBlockHeader* pBlockHeaderNext;
struct _CrtMemBlockHeader* pBlockHeaderPrev;
char* szFileName; //指向被调试文件的文件名
int nLine; //文件行
size_t nDataSize; //记录真正分配的大小
int nBlockUse; //记录这个内存块被干嘛用了
/*
_FREE_BLOCK 0
_NOROMAL_BLOCK 1 用户申请的一般都是这个
_CRT_BLOCK 2
_IGNORE_BLOCK 3
_CLIENT_BLOCK 4
_MAX_BLOCKS 5
*/
long IRequest;//id
unsigned char gap[nNoMansLandSize]; //4个字符指针(填充无人区,后面还会补一个,用来检测有没有被写脏数据数据)
}_CrtMemBlockHeader;
_heap_alloc_base();// 检查如果mallocl的内存小于1024采用SBH小区块分配器
_sbh_alloc_block();//计算好总共需要分配的内存字节,如果是debug模式就是36个debug的数据块+上下cookie,如果是正常模式则只有上下cookie(上下cookie是为了回收的时候上下合并):
heap_alloc_new_region()
第一个Header的指针申请region——由HeapAlloc(_crtheap, sizeof(region))分配
内存分配原理: 16个Header(有一个头指针为其定位)。每一个Header负责管理1MB——申请虚拟地址空间调用Windows API——VirtualAlloc()。每一个Header有两根指针——其中一根指向其管理中心——region。
//region结构
typedef struct tagRegion{
int indGroupUse; //整数
char cntRegionSize[64]; //64个character
//unsigned int 32位 高位和低位合并之后——>32组数据,每组64bits
BITVEC bitvGroupHi[32];
BITVEC bitvGroupLo[32];
//32个group 每一个group管理32KB
struct tagGroup grpHeadList[32];
}REGION,&PREGION;
//group结构
typedef struct tagGroup{
int cntEntries;
// 64对双向链表
struct tagListHead ListHead[64]; //类似alloc的分配方式,0号链表管理16字节,1号32字节...63管理1024字节且最后一条链表有个特殊设计,大于1k的全归他管
}GROUP, *PGROUP;
//双向链表
typedef struct tagListHead{
struct tagEntry* pEntryNext;
struct tagEntry* pEntryPrev;
}LISTHEAD, *PLISTHEAD;
typedef struct tagEntry{
int sizeFront; //记录4080Bytes
struct tagEntry* pEntryNext;
struct tagEntry* pEntryPrev;
}ENTRY *PENTRY;
heap_alloc_new_group()
1MB分为32个单元,每单元32KB的大小。然后每一个单元又分为8个page,每部分4KB——对应操作系统的page。而管理中心region一共有32个group,所以每一个group管理8x4KB的内存资源。
从上面的代码中可以知道:一个group共有64个双向指针,这些指针所管理的内存按照16的倍数递增(即1st—16字节,2nd—32字节...64th—>=1024字节)。 因此一个group实际上可以管理的大小是16*(1 + 2 + ...+ 64) = 32KB + 512Bytes。符合最开始的设定。
根据ioinit申请的内存大小110h,加上debug模块和cookie,再进行16字节的对齐。最后需要向每一个page申请130h字节的内存。最后还剩下ec0h = ff0h - 130h。那一个page便会被切割成为两部分——一部分是分配的130h内存,这一部分需要将130h改为131h代表脱离了SBH系统的控制分离出去。 另一部分是剩下的ec0h。双方的结构都是heap_alloc_dbg::struce _CrtMemBlockHeader并且都需要更新cookie。以后每一次分配都需要根据分配的size计算所挂的链表——如果该链表上没有区块,则向上移动直到最后一条链表上再分配。
至此,malloc函数的整个分配过程基本结束了。
[x] Free
free(p) //将p回收到相应的链表上
落在哪个Header上?
落在哪个Group上?
落在哪个free-list上?
整个系统的主要结构就是:Header/Region——Group——free-list上述各个数据结构的大小都知道,所以很容易定位p指针。
Group`回收: `(p - 头指针)/32K
Header回收: 使用头指针__sbh_pHeaderList从第一个Header开始索引判断。
free-list回收: 将区块size/16 - 1然后判断回收需要挂在group上的哪一个链表上面。
合并:每一个区块都有上下的cookie,根据cookie的最后一位是不是1判断是否可以合并。
Defering:当出现两个Group全回收(Counter判断)的时候,则将Defer指针指向第一个准备释放给OS,如果只有一个全回收的Group则不释放。
[x] Loki::allocator
Loki::allocator核心有三个类:Chunk,FixedAllocator 和 SmallObjAllocator。它们的类层次关系如下,其中SmallObjAllocator 是最上层的,直接供客户端使用的类。
Chunk 就是直接管理单一内存块的类。它负责向操作系统索取内存块,并将内存块串成 “链表”。
先来看看其中的初始化函数 Init()
void FixedAllocator::Chunk::Init(std::size_t blockSize, unsigned char blocks)
{
pData_ = new unsigned char[blockSize * blocks];
Reset(blockSize, blocks);
}
void FixedAllocator::Chunk::Reset(std::size_t blockSize, unsigned char blocks)
{
firstAvailableBlock_ = 0;
blocksAvailable_ = blocks;
unsigned char i = 0;
unsigned char* p = pData_;
for (; i != blocks; p += blockSize) //指向下一个可用的 block 的 index
{
*p = ++i;
}
}
传入参数为 block 的大小和数量
用 operator new 分配出一大块内存 chunk,并用指针 pData_ 指向 chunk。
Reset() 函数对这块内存进行分割。利用嵌入式指针的思想,每一块 block 的第一个 byte 存放的是下一个可用的 block 距离起始位置 pData_ 的偏移量(以 block 大小为单位),以这种形式将 block 串成 “链表”。(这里的核心就是申请的内存块其实是顺序结构的,而用index来模拟了指针)
firstAvailableBlock_ 表示当前可用的 block 的偏移量;blocksAvailable_ 表示当前 chunk 中剩余的 block 数量。
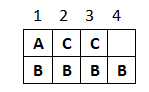
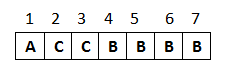
初始状态的 chunk 如下图所示:

初始分配状态如下:

内存分配 allocate
void* FixedAllocator::Chunk::Allocate(std::size_t blockSize)
{
if (!blocksAvailable_) return 0;//如果没有可用空间了就返回
unsigned char* pResult =
pData_ + (firstAvailableBlock_ * blockSize);//分配空间
firstAvailableBlock_ = *pResult;//下一个预分配的idx为这个分配出去的result内部的值标示的地址
--blocksAvailable_;//调整可用空间
return pResult;
}

内存回收 deallocate
void FixedAllocator::Chunk::Deallocate(void* p, std::size_t blockSize)
{
unsigned char* toRelease = static_cast<unsigned char*>(p);//借他的空间来标示自己的内部的idx
*toRelease = firstAvailableBlock_;//吧这个值存成之前的预分配的下一个的idx
//修改 “头指针idx”
//回收的 block 指针距离头指针 pData_ 的距离(以 block 为单位)
firstAvailableBlock_ = static_cast<unsigned char>(
(toRelease - pData_) / blockSize);//然后告诉容器下一个分配“我”,“我”可以用
++blocksAvailable_;//可分配容量增加
}

FixedAllocate
FixedAllocate 则负责管理一个具有相同 block size 的 chunk 的集合。它负责根据客户需求,创建特定 block 大小的 chunk ,并放置在容器 vector 中进行管理。
allocate
void* FixedAllocator::Allocate()
{
if (allocChunk_ == 0 || allocChunk_->blocksAvailable_ == 0)
{ //目前没有标定的 chunk ,或者这个 chunk 已经用完了
//从头找起
Chunks::iterator i = chunks_.begin();
for (;; ++i)
{
//没找到,则创建一个新的 chunk,
if (i == chunks_.end())
{
// Initialize
chunks_.reserve(chunks_.size() + 1);
Chunk newChunk;
newChunk.Init(blockSize_, numBlocks_);
chunks_.push_back(newChunk);
allocChunk_ = &chunks_.back();
//上面容器的大小会增长一个,可能会引起 vetor 的扩容操作,导致原来的元素被搬移到新的地方,而原来的deallocChunk指向的地址已经不可用,原来的那个经过搬移之后已经无法确定新的位置了,所以这里的 deallocChunk 需要重新标定,直接标定为第一个(就是因为已经全部不可用了才申请的新内存块,所以回收到哪里指向原来chunkslist的任何一个都同一个效果)
deallocChunk_ = &chunks_.front();
break;
}
//找到的话直接分配新的allocChunk_
if (i->blocksAvailable_ > 0)
{
allocChunk_ = &*i;
break;
}
}
}
//返回
return allocChunk_->Allocate(blockSize_);
}
allocChunk_ 指向当前正在使用中的 chunk。如果 allocChunk_ 指向的 chunk 中的 block 已经用完了,那么就在容器中去寻找其他可用的 chunk 。如果没有找到,就新建一个 chunk ,放进容器中,并标定为当前的 allocChunk_。deallocChunk_ 成员没有关系的。但是,创建新的 chunk 并添加进 vector 中后,可能会引起 vector 的内存重分配动作(内存搬移),导致原来的 deallocChunk_ 指向的内存并不存在了,所以要对 deallocChunk_ 重新标定。它这里直接重新标定为第一个 chunk,因为原来的那个已经无法确定位置了。内存回收 deallocate
void FixedAllocator::Deallocate(void* p)
{
deallocChunk_ = VicinityFind(p);
DoDeallocate(p);
}
/*
VicinityFind() 函数采用一种分头查找的算法,从上一次 deallocChunk_ 的位置出发,在容器中分两头查找。这也应该是设计这个 deallocChunk_ 指针的原因把。内存分配通常是给容器服务的。而容器内元素连续创建时,通常就从同一个 chunk 获得连续的地址空间。归还的时候当然也需要归还到同一块 chunk 。通过对上一次归还 chunk 的记录,能提高搜索的效率。下面是 VicinityFind() 的实现代码:
*/
Chunk * FixedAllocator::VicinityFind( void * p ) const
{
if ( chunks_.empty() ) return NULL;
assert(deallocChunk_);
const std::size_t chunkLength = numBlocks_ * blockSize_;
Chunk * lo = deallocChunk_;
Chunk * hi = deallocChunk_ + 1;
const Chunk * loBound = &chunks_.front();
const Chunk * hiBound = &chunks_.back() + 1;
//特殊情况:deallocChunk_是数组中的最后一个
if (hi == hiBound) hi = NULL;
//这里从上一次 deallocChunk_ 的位置出发,在容器中分两头查找。内存分配通常是给容器服务的。而容器内元素连续创建时,通常就从同一个 chunk 获得连续的地址空间。归还的时候当然也需要归还到同一块 chunk 。通过对上一次归还 chunk 的记录,能提高搜索的效率。但是这个搜索方式有个隐患, 双端查找没找
for (;;)
{
if (lo)
{
if ( lo->HasBlock( p, chunkLength ) ) return lo;
if ( lo == loBound )
{
lo = NULL;
if ( NULL == hi ) break;//新版本改了,这是我拿的新版本代码,当上下都找不到的时候会退出循环,不然会死循环,什么时候出现呢?当你Deallocate一个并不是他分配出来的对象的时候,就肯定找不到,必死循环
}
else --lo;
}
if (hi)
{
if ( hi->HasBlock( p, chunkLength ) ) return hi;
if ( ++hi == hiBound )
{
hi = NULL;
if ( NULL == lo ) break;
}
}
}
return NULL;
}
/*
最后内存回收的动作由函数 DoDeallocate() 完成。如果当前回收的 chunk 已经将所有的 block 全部回收完了,即 deallocChunk_->blocksAvailable_ == numBlocks_ ,本来这块内存就可以归还给 OS 了的。但是这里采取了一个延迟归还的动作。把这个空的 chunk 通过 swap 函数放在 vector 的末尾,并且将 allocChunk_ 指向它,供下一次再使用。只有当有两个空 chunk 出现时,才会把上一个空的 chunk 归还给 OS。下面是源码:
*/
void FixedAllocator::DoDeallocate(void* p)
{
//调用块,将调整内部列表,但不会释放内存
deallocChunk_->Deallocate(p, blockSize_);
//如果已经全回收了
if (deallocChunk_->blocksAvailable_ == numBlocks_)
{
// deallocChunk_是完全空的,这时候应该释放它了吗?(先等等,不要激进)
Chunk& lastChunk = chunks_.back();
//最后一个就是当前的 deallocChunk
if (&lastChunk == deallocChunk_)
{
//当有两个空deallocChunk_的时候,我再去释放,如果只有一个就缓存起来备用,万一马上就有人用了呢
if (chunks_.size() > 1 &&
deallocChunk_[-1].blocksAvailable_ == numBlocks_)
{
// 有两个,释放最后一个
lastChunk.Release();
chunks_.pop_back();
allocChunk_ = deallocChunk_ = &chunks_.front();
}
return;
}
if (lastChunk.blocksAvailable_ == numBlocks_)//可用空间等于预分配大小,代表是全空的
{
//和上面一样释放一下
lastChunk.Release();
chunks_.pop_back();
allocChunk_ = deallocChunk_;
}
else
{
//如果只有一个空的,要把这个空的放到容器末尾,让申请器去使用
std::swap(*deallocChunk_, lastChunk);
allocChunk_ = &chunks_.back();
}
}
}
SmallObjAllocator
void* SmallObjAllocator::Allocate(std::size_t numBytes)
{
//SmallObjAllocator 不可能无穷无尽的满足客户不同的 block size 的需求。它设有一个最大的 block size 变量 `maxObjectSize_` 。如果客户端需求的 block size 大于这个 threshold,就直接交由 operator new 去进行处理。
if (numBytes > maxObjectSize_) return operator new(numBytes);
//pLastAlloc_ 记录上一次分配 block 的 FixedAllocator object 。如果这一次需求的 block size 等于上一次分配的 block size,就直接使用同一个 FixedAllocator object 去分配内存。我认为这个变量的设计和 FixedAllocator 中 deallocChunk_ 的设计道理是一样的。 SmallObjAllocator 是给容器服务,而容器通常连续多次为其中的 element 索取多个相同 size 的 block,所以对上一次分配的 FixedAllocator object 进行记录能够减少不必要的查找动作。
if (pLastAlloc_ && pLastAlloc_->BlockSize() == numBytes)
{
return pLastAlloc_->Allocate();
}
/*
如果这一次需求的 block size 不等于上一次分配的 block size,就遍历容器寻找不小于需求的 block size 而且最接近的位置,也就是 std::lower_bound() 函数的功能。如果找到 block size 相等的,就直接分配;如果没找到相等的,就在该位置上插入一个新的 FixedAllocator object。同样,为了防止 vector 扩容操作引起重新分配内存,需要对 pLastDealloc_进行重定位。
*/
//找到第一个 >= numBytes 的位置
Pool::iterator i = std::lower_bound(pool_.begin(), pool_.end(), numBytes);
//没找到相同的,就重新创建一个 FixedAllocator
if (i == pool_.end() || i->BlockSize() != numBytes)
{
i = pool_.insert(i, FixedAllocator(numBytes));
pLastDealloc_ = &*pool_.begin();
}
pLastAlloc_ = &*i;
return pLastAlloc_->Allocate();
}
内存回收 deallocate
void SmallObjAllocator::Deallocate(void* p, std::size_t numBytes)
{
/*设计同上*/
if (numBytes > maxObjectSize_) return operator delete(p);
if (pLastDealloc_ && pLastDealloc_->BlockSize() == numBytes)
{
pLastDealloc_->Deallocate(p);
return;
}
Pool::iterator i = std::lower_bound(pool_.begin(), pool_.end(), numBytes);
assert(i != pool_.end());
assert(i->BlockSize() == numBytes);
pLastDealloc_ = &*i;
pLastDealloc_->Deallocate(p);
}
与alloc比较
loki::allocator 通过利用一个 blocksAvailable_ 变量,就很容易的判断出某一块 chunk 中的 block 是否已经全部归还了,这样就可以归还给 OS。loki::allocator 能够为不大于最大 block size 的所有 block size 服务。[ ] Other issues
GNU-C下的6个分配器
new_allocator
::operator new/delete,虽然底层还是调用malloc/free,但是好处是可以支持全局重载::operator new/delete让用户自定义分配内存的操作malloc_allocator
malloc/freearray_allocator
/*
该分配器直接使用静态数组进行分配,开局直接指定大小,牛皮,所以空间固定,而且回收不会释放,总的来说,没什么用 - -
*/
//数组分配器, 从数组中直接分配
template<typename _Tp, typename _Array = std::tr1::array<_Tp, 1>> //底部是C++数组 静态数组(不需要释放)——所以deallocate()是空的
class array_allocator : public array_allocator_base<_Tp>
{
public:
typedef size_t size_type;
typedef _Tp value_type;
typedef _Array array_type;
private:
array_type* _M_array; //指向数组的指针
size_type _M_used;
public:
array_allocator(array_type* __array = NULL)throw() : _M_array(_array), _M_used(size_type()){}
}
using namespace std;
using namespace std::tr1;
using namespace __gnu::cxx;
int my[65535];
array_allocator<int, array<int, 65535>>
myalloc(&my); //初始化
//分配空间 但是不会回收释放过的空间
int* p1 = myalloc::allocate(1);
int* p2 = myalloc.allocate(3);
myalloc.deallocate(p1);
myalloc.deallocate(p2);
}
debug_allocator
pool_allocator:
bitmap_allocator
blocks,每个区块8个字节。加上bitmap以及一些区块叫super-blocks。假设有64个blocks,则需要的bitmap是64bits——两个unsigned int。bitmap每一个bit为1表示还未分配。use-count表示用掉的区块计数(整数)。size-super-block 表示super-block的大小——64 * 8(block size) +4(use-count) + 4*2(bitmap) = 524Bytes。__mini_vector: 自行实现的高仿Vector,用来管理结构管理bitmap——成倍增长,为啥自己实现嘞,因为如果用了Vector,又服务于Vector,那不就鸡生蛋蛋生鸡了嘛。super-block是基本单元。当启动第二个super-block的时候,首先区块数量会加倍——从64Bytes变成128Bytes。接着bitmap会变成4个unsigned int。这时候size-super-block为128 * 8(block size) + 4 * 4(bitmap) + 4(use-count)= 1044bytes 。由于需要有两个控制中心——所以__mini_vector也需要增加,因为是类vector所以有时成倍增长。__mini_vector用来控制回收的链表,内部按大小排序,最多64个entry,如果超过了区块就会还最大的给操作系统。当freelist中有值的时候,再分配时不会new一个新的Entry,会从这里拿一个出去补给系统。[x] 结构体的占用的字节数
先看三种结构体的书写格式
struct TestSturct
{
char A;
int B;
short C;
}test1;
struct TestSturct
{
char A;
int B;
short C;
}test2;
struct TestSturct
{
char A;
int B;
short C;
}test3;
我们都知道,char类型占用1个字节,int型占用4个字节,short类型占用2个字节,那么我们可能会犯一个错误就是直接1+4+2=7,该结构体占用7个字节。这是错的。
计算结构体大小时需要考虑其内存布局,结构体在内存中存放是按单元存放的,每个单元多大取决于结构体中最大基本类型的大小。
对格式一:
以int型占用4个来作为倍数,因为A占用一个字节后,B放不下,所以开辟新的单元,然后开辟新的单元放C,所以格式一占用的字节数为:3*4=12;
同理对于格式二:
A后面还有三个字节,足够C存放,所以C根着A后面存放,然后开辟新单元存放B数据。所以格式二占用的内存字节为2*4=8.
对于格式三:
上面结构计算大小,sizeof(Phone3) = 1 + 2 + 4 = 7, 其大小为结构体中个字段大小之和,这也是最节省空间的一种写法。
总结
[x] 内存泄漏出现的时机和原因,如何避免
原因
如何避免?
不要手动管理内存,可以尝试在适用的情况下使用智能指针。
使用string而不是char*。string类在内部处理所有内存管理,而且它速度快且优化得很好。
除非要用旧的lib接口,否则不要使用原始指针。
在C++中避免内存泄漏的最好方法是尽可能少地在程序级别上进行new和delete调用--最好是没有。任何需要动态内存的东西都应该隐藏在一个RAII对象中,当它超出范围时释放内存。RAII在构造函数中分配内存并在析构函数中释放内存,这样当变量离开当前范围时,内存就可以被释放。
(注:RAII资源获取即初始化,也就是说在构造函数中申请分配资源,在析构函数中释放资源)
使用了内存分配的函数,要记得使用其想用的函数释放掉内存。可以始终在new和delete之间编写代码,通过new关键字分配内存,通过delete关键字取消分配内存。
培养良好的编码习惯,在涉及内存的程序段中,检测内存是否发生泄漏。
[x] c++的内存区域划分
[x] 谈谈堆与栈的关系与区别
现代计算机都直接在代码底层支持栈的数据结构,这体现在,有专门的寄存器指向栈所在的地址,有专门的机器指令完成数据入栈出栈的操作。这种机制的特点是效率高,支持的数据有限,一般是整数,指针,浮点数等系统直接支持的数据类型,并不直接支持其他的数据结构。因为栈的这种特点,对栈的使用在程序中是非常频繁的。对子程序的调用就是直接利用栈完成的。机器的call指令里隐含了把返回地址推入栈,然后跳转至子程序地址的操作,而子程序中的ret指令则隐含从堆栈中弹出返回地址并跳转之的操作。C/C++中的自动变量是直接利用栈的例子,这也就是为什么当函数返回时,该函数的自动变量自动失效的原因。
和栈不同,堆的数据结构并不是由系统(无论是机器系统还是操作系统)支持的,而是由函数库提供的。基本的malloc/realloc/free 函数维护了一套内部的堆数据结构。当程序使用这些函数去获得新的内存空间时,这套函数首先试图从内部堆中寻找可用的内存空间,如果没有可以使用的内存空间,则试图利用系统调用来动态增加程序数据段的内存大小,新分配得到的空间首先被组织进内部堆中去,然后再以适当的形式返回给调用者。当程序释放分配的内存空间时,这片内存空间被返回内部堆结构中,可能会被适当的处理(比如和其他空闲空间合并成更大的空闲空间),以更适合下一次内存分配申请。这套复杂的分配机制实际上相当于一个内存分配的缓冲池(Cache),使用这套机制有如下若干原因:
堆和栈的对比
不同问题的对比
明确区分堆与栈:
void f()
{
int* p=new int[5];
delete[] p;
}
这条短短的一句话就包含了堆与栈,看到new,我们首先就应该想到,我们分配了一块堆内存,那么指针p呢?他分配的是一块栈内存,所以这句话的意思就是:在栈内存中存放了一个指向一块堆内存的指针p.在程序会先确定在堆中分配内存的大小,然后调用operator new分配内存,然后返回这块内存的首地址,放入栈中
堆和栈主要的区别由以下几点:
标签:位置 term 指令 assert 字节 tor 类对象 检测 center
原文地址:https://www.cnblogs.com/moran-amos/p/14310167.html