标签:style https grid color def lock play parse imp
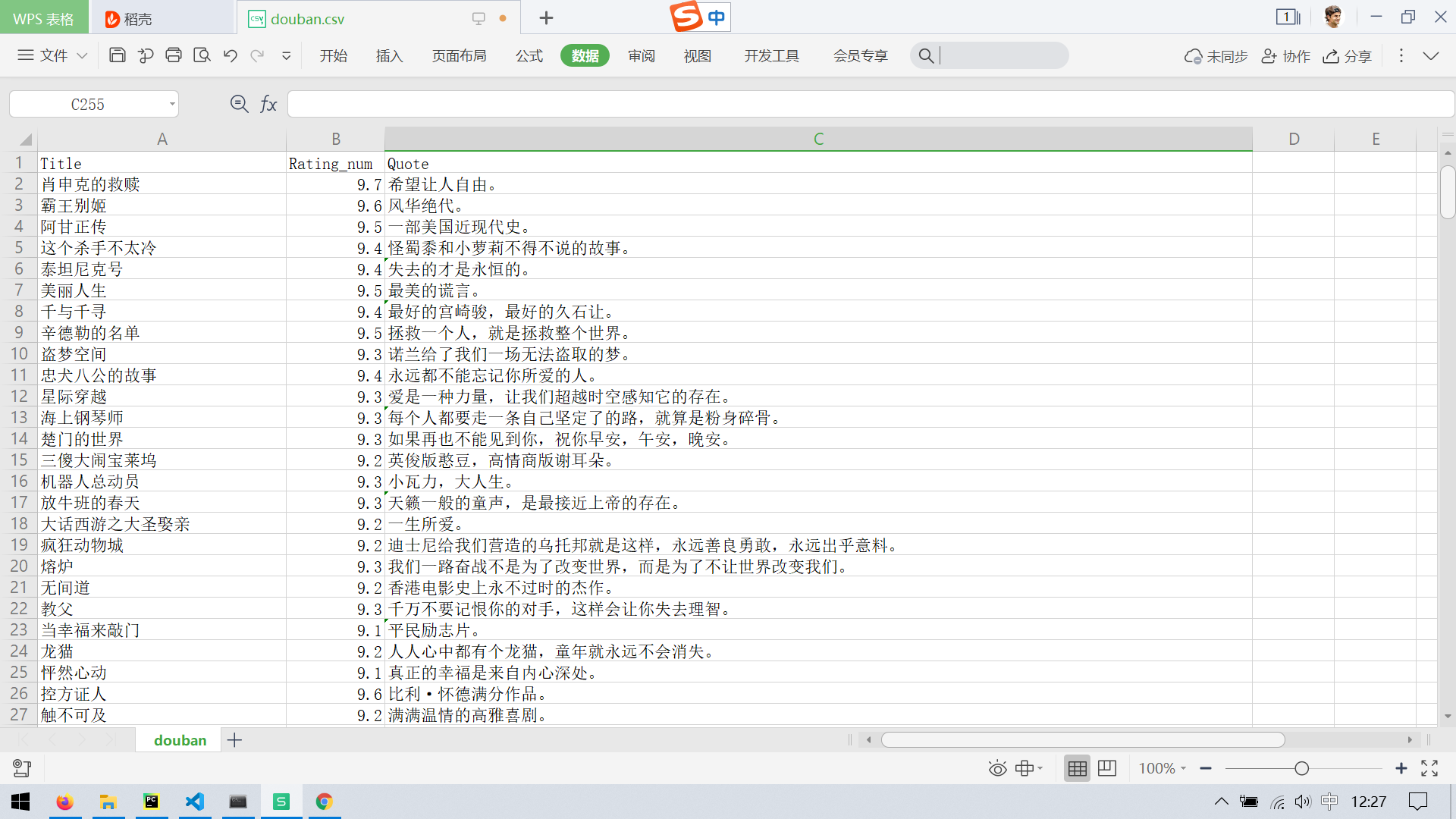
1 import scrapy 2 import re 3 from fake_useragent import UserAgent 4 5 6 class DoubanSpider(scrapy.Spider): 7 name = "douban" 8 start_urls = [‘https://movie.douban.com/top250‘, ] 9 custom_settings = {"USER_AGENT": UserAgent().random} 10 11 def parse(self, response): 12 for movie in response.xpath("//ol[@class=‘grid_view‘]/li"): 13 14 yield { 15 ‘Title‘: movie.xpath(".//span[@class=‘title‘]/text()").get(), 16 ‘Rating_num‘: movie.xpath(".//span[@class=‘rating_num‘]/text()").get(), 17 ‘Quote‘: movie.xpath(".//p[@class=‘quote‘]/span/text()").get() 18 } 19 20 next_page = response.xpath("//span[@class=‘next‘]/a/@href").get() 21 if next_page is not None: 22 yield response.follow(next_page, callback=self.parse)
scrapy runspider douban一层能解决.py -o douban.csv
标签:style https grid color def lock play parse imp
原文地址:https://www.cnblogs.com/waterr/p/14334338.html