标签:封装 send possible memory 决定 pst guarantee 调用接口 可重入函数
1、背景知识
1.1、Linux内核
Linux内核的主要组件如图1所示,有系统调用接口、进程管理、内存管理、虚拟文件系统、网络堆栈、设备驱动程序、硬件架构的相关代码。
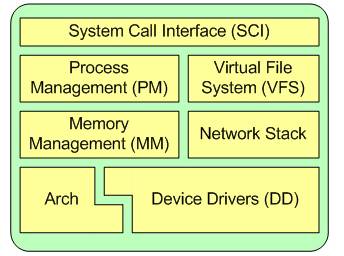
其中进程管理主要控制系统进程对CPU的访问。当需要某个进程运行时,由进程调度器根据基于优先级的调度算法启动新的进程。Linux上单个CPU实现多任务运行,是由进程调度管理来实现的。由于切换的时间和频率都非常的快,由此用户感觉是多个程序在同时运行,而实际上,CPU在同一时间内只有一个进程在运行。中断技术正是进程调度和进程通信中不可或缺的部分。
1.1.1、中断处理
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
I/O设备把中断信号发送给中断控制器时与之相关联的是一个中断号,当中断控制器把中断信号发送给CPU时与之关联的是一个中断向量。换个角度分析就是中断号是从中断控制器层面划分,中断向量是从CPU层面划分,所以中断号与中断向量之间存在一对一映射关系。在Intel X86中最大支持256种中断,从0到255开始编号,这个8位的编号就是中断向量。其中将0到31保留用于异常处理和不可屏蔽中断。
Linux内核中处理中断主要有三个数据结构,irq_desc,irq_chip和irqaction。在\include\linux\irq.h中定义了irq_desc用于描述IRQ线的属性与状态,被称为中断描述符,还定义了irq_chip用于描述不同类型的中断控制器;在\include\linux\interrupt.h中定义了irqaction描述特定设备产生的中断描述符。
Linux中断机制由三部分组成:
中断子系统初始化:内核自身初始化过程中对中断处理机制初始化,例如中断的数据结构以及中断请求等。
中断或异常处理:中断整体处理过程。
中断API:为设备驱动提供API,例如注册,释放和激活等。
由于中断会打断内核中进程的正常调度运行,所以要求中断服务程序尽可能的短小精悍;但是在实际系统中,当中断到来时,要完成工作往往进行大量的耗时处理。因此期望让中断处理程序运行得快,并想让它完成的工作量多,这两个目标相互制约,诞生——顶/底半部机制。
中断处理程序是顶半部——接受中断,它就立即开始执行,但只有做严格时限的工作。能够被允许稍后完成的工作会推迟到底半部去,此后,在合适的时机,底半部会被开终端执行。顶半部简单快速,执行时禁止一些或者全部中断。
底半部稍后执行,而且执行期间可以响应所有的中断。这种设计可以使系统处于中断屏蔽状态的时间尽可能的短,以此来提高系统的响应能力。顶半部只有中断处理程序机制,而底半部的实现有软中断,tasklet和工作队列实现。
如何区分一个工作是放在顶半部还是放在底半部去执行,有如下标准:
任务对时间非常敏感,将其放在中断处理程序中执行。
任务和硬件相关,将其放在中断处理程序中执行。
任务要保证不被其他中断(特别是相同的中断)打断,将其放在中断处理程序中执行。
其他所有任务,考虑放在下半部去执行。
1.1.2、 软中断
软中断作为底半部机制的代表,它也是tasklet实现的基础。软中断一般是“可延迟函数”的总称,它的出现就是因为要满足上面所提出的顶半部和底半部的区别,使得对时间不敏感的任务延后执行,软中断执行中断处理程序留给它去完成的剩余任务,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。特性包括:
a)产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断,只能被硬件中断打断。
b)可以并发运行在多个CPU上。所以软中断必须设计为可重入的函数,因此也需要使用自旋锁来保护其数据结构。
1.1.3、tasklet
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性:
a)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。
b)多个不同类型的tasklet可以并行在多个CPU上。
c)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。
tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
1.1.4、工作队列
把推后执行的任务叫做工作(work),描述它的数据结构为work_struct ,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct ,而工作线程就是负责执行工作队列中的工作。系统默认的工作者线程为events。
工作队列(work queue)是另外一种将工作推后执行的形式。工作队列可以把工作推后,交由一个内核线程去执行,内核线程总是会在进程上下文执行,但由于是内核线程,其不能访问用户空间。最重要特点的就是工作队列允许重新调度甚至是睡眠。
通常,在工作队列和软中断/tasklet中作出选择非常容易。可使用以下规则:
- 如果推后执行的任务需要睡眠,那么只能选择工作队列。
- 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时(内核定时器实现)。
- 如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程,同时不可睡眠。
- 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。
实际上,工作队列的本质就是将工作交给内核线程处理,因此其可以用内核线程替换。但是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以通常推荐使用工作队列。
1.1.5、内核线程
内核经常需要在后台执行一些操作,这种任务就可以通过内核线程(kernel thread)完成,内核线程是独立运行在内核空间的标准进程。内核线程和普通的进程间的区别在于内核线程没有独立的地址空间;内核线程只在内核空间运行,并且可以被调度,也可以被抢占。实际上,内核线程只能由其他内核线程创建,linux驱动模块中可以用kernel_thread(),kthread_create()/kthread_run()两种方式创建内核线程。
1.2、TCP/IP协议
1.2.1、OSI网络模型
OSI参考模型,是由ISO(国际标准化组织)定义的一个灵活的稳健的和可互操作的模型,并不是协议,是用来了解和设计网络体系结构的。使用网络参考模型的目的是规范不同系统的互联标准,使两个不同的系统能够较容易的通信,而不需要改变底层的硬件或者软件的逻辑,每一层指定了不同协议标准。
OSI把网络按照层次分为七层,由下到上分别为物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。每个层次对应了相应的标准或者协议,功能如图2所示:
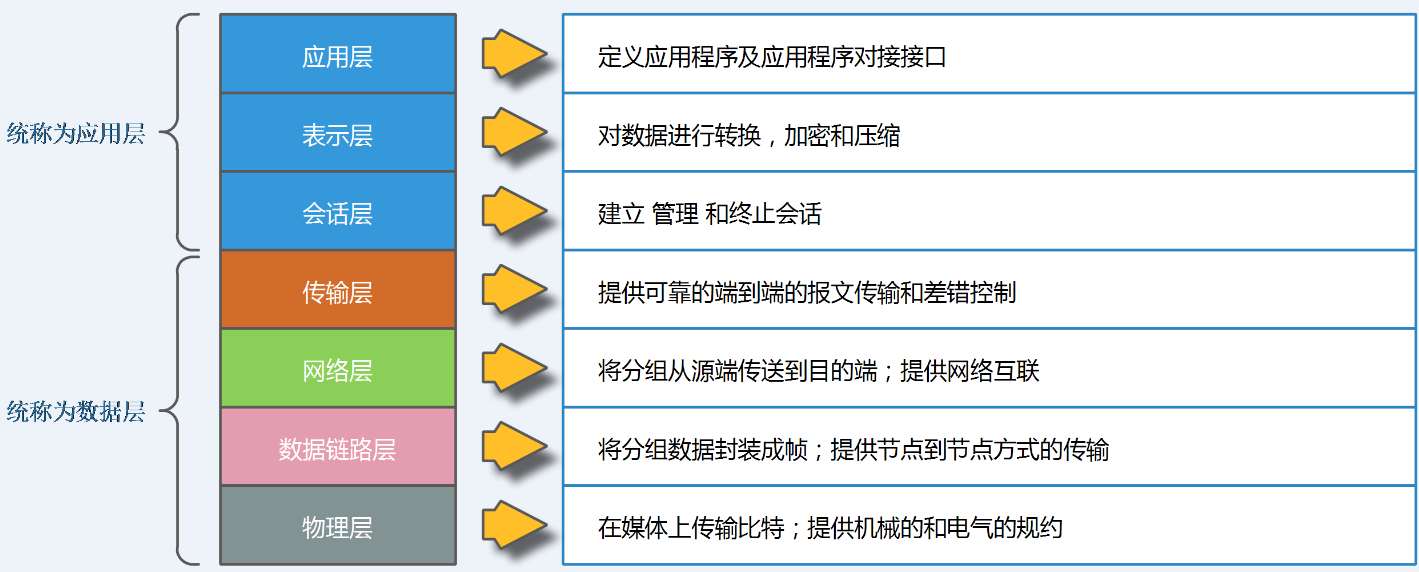
1.2.2、TCP/IP网络模型
OSI七层模型简化四层TCP/IP模型,应用层、表示层、会话层统称为应用层,传输层称为主机到主机层,网络层即为因特网层,数据链路层和网络层统称为网络接入层。网络层次模型组成部分如图3所示:
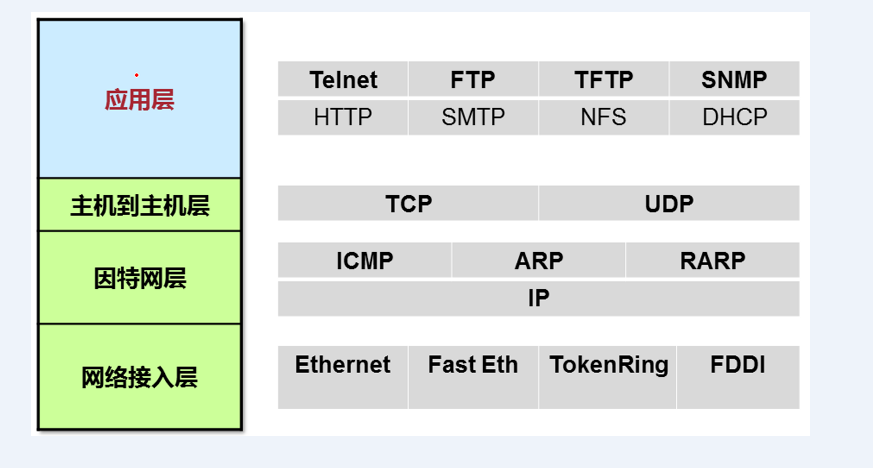
1.2.3、Linux网络结构
在Linux中实际的网络结构如图4所示:
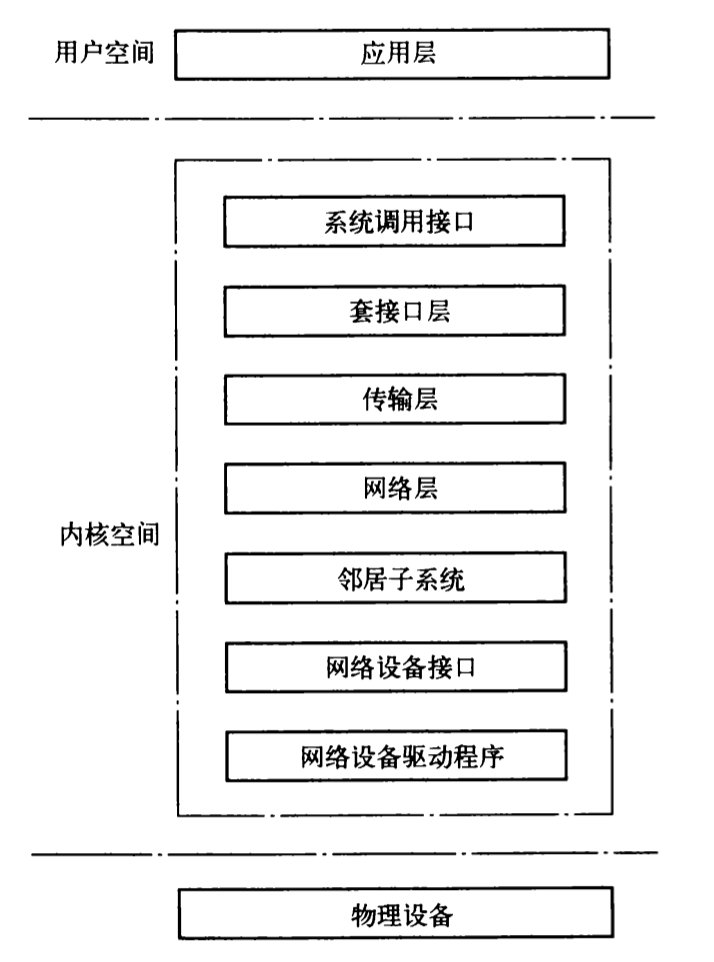
应用层主要在用户空间,用户空间的各个APP模块实现了Linux设备的各种不同的功能。例如对于一台Linux路由器来讲,用户空间实现了路由协议、mpls协议、dhcp协议等一些具体应用功能的模块。
Linux的内核空间为应用层的各协议模块提供收发数据包的功能,上层协议统一都由Linux内核协议栈提供的系统调用接口。Linux协议栈只要完成的就是内核空间的各个网络子系统的实现。
物理设备,提供对网络的链接能力。例如网卡收发包交换芯片等。
下面介绍内核空间的子模块的功能:
2、编译、部署、运行
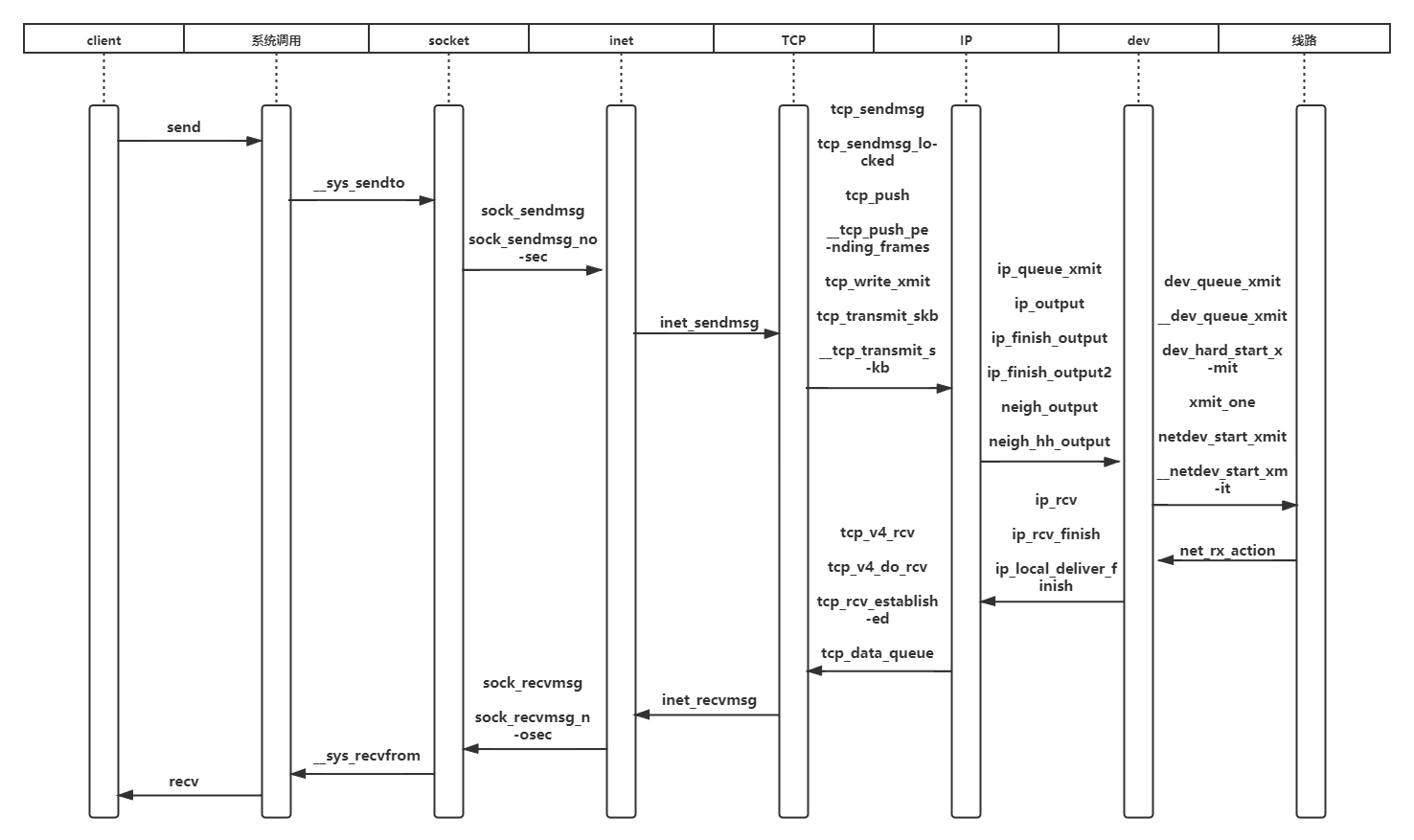
结合背景知识,可以大致获得本次调研的流程,通过进程管理中的中断技术,跟踪Linux内核中TCP/IP协议栈的运行过程,分析调用顺序和调用参数。
2.1、编译内核
本次编译的运行环境为Ubuntu 20.04.1 LTS 64位,编译内核版本为Linux-5.4.34,使用工具busybox-1.31.1制作内存根文件系统,使用QEMU创建虚拟机。内核编译成功如图5:
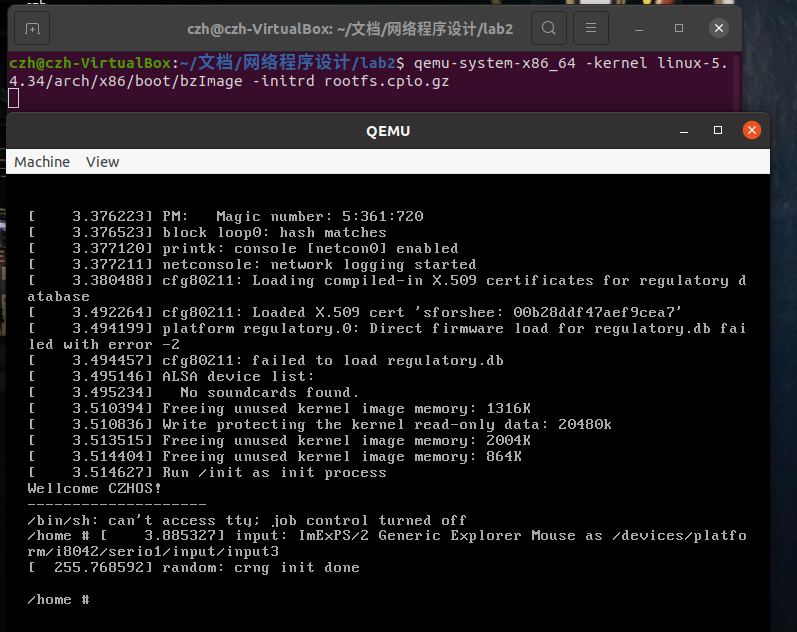
2.2、编写测试程序
编写一个基于TCP协议的通信程序,包括服务器端server和客户端client。代码运行的思路如图6所示:
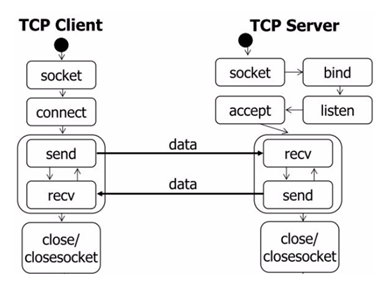
2.3、运行
在编译内核之前将测试程序放入内核文件系统中,通过gdb进行调试。成功截图如图7:
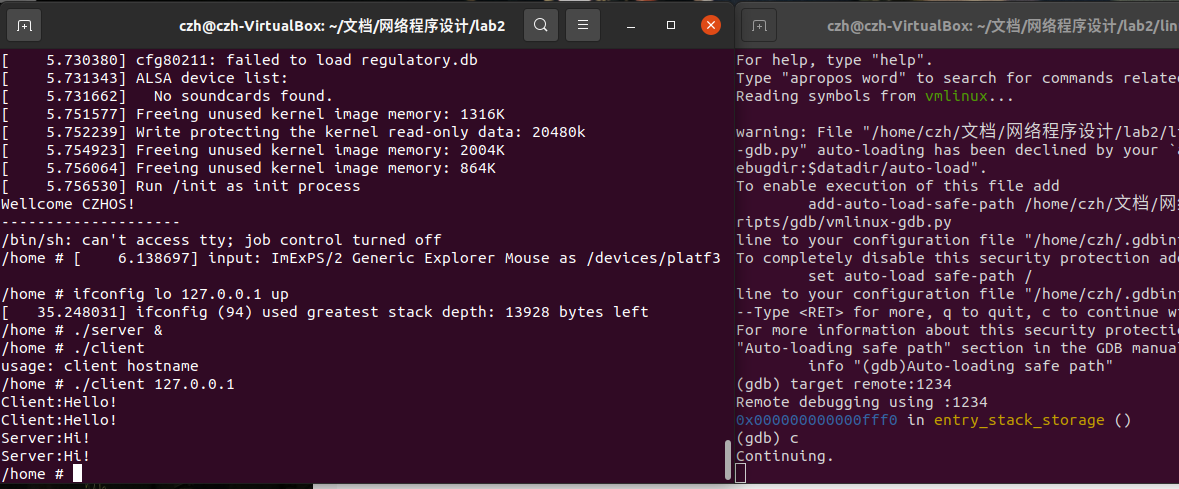
3、源代码分析
3.1、send过程源代码分析
3.1.1、应用层
通过资料查询,我们可以确定send函数发送数据经历的主要内核函数有__sys_sendto,在gdb中设置断点找出send调用__sys_sendto的过程图8:
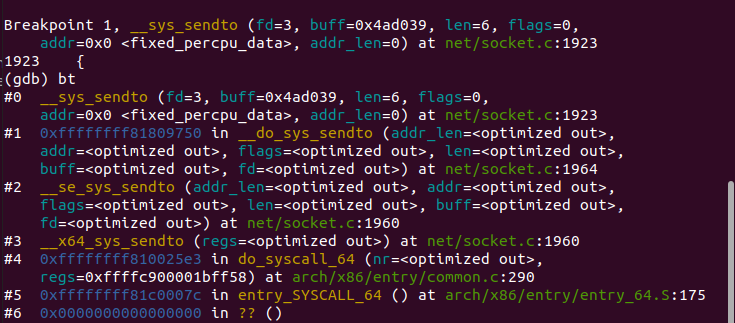
__sys_sendto函数源代码如下:
1 /* 2 * Send a datagram to a given address. We move the address into kernel 3 * space and check the user space data area is readable before invoking 4 * the protocol. 5 */ 6 int __sys_sendto(int fd, void __user *buff, size_t len, unsigned int flags, 7 struct sockaddr __user *addr, int addr_len) 8 { 9 struct socket *sock; 10 struct sockaddr_storage address; 11 int err; 12 struct msghdr msg; 13 struct iovec iov; 14 int fput_needed; 15 16 err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); 17 if (unlikely(err)) 18 return err; 19 sock = sockfd_lookup_light(fd, &err, &fput_needed); 20 if (!sock) 21 goto out; 22 23 msg.msg_name = NULL; 24 msg.msg_control = NULL; 25 msg.msg_controllen = 0; 26 msg.msg_namelen = 0; 27 if (addr) { 28 err = move_addr_to_kernel(addr, addr_len, &address); 29 if (err < 0) 30 goto out_put; 31 msg.msg_name = (struct sockaddr *)&address; 32 msg.msg_namelen = addr_len; 33 } 34 if (sock->file->f_flags & O_NONBLOCK) 35 flags |= MSG_DONTWAIT; 36 msg.msg_flags = flags; 37 err = sock_sendmsg(sock, &msg); 38 39 out_put: 40 fput_light(sock->file, fput_needed); 41 out: 42 return err; 43 }
可以看出该函数的目的是根据描述符fd,寻找对应的socket结构体,然后发送数据包的相关信息给内核,该消息结构体为msghdr,最后调用sock_sendmsg。
一直运行到调用inet_sendmsg,中间调用为图9:
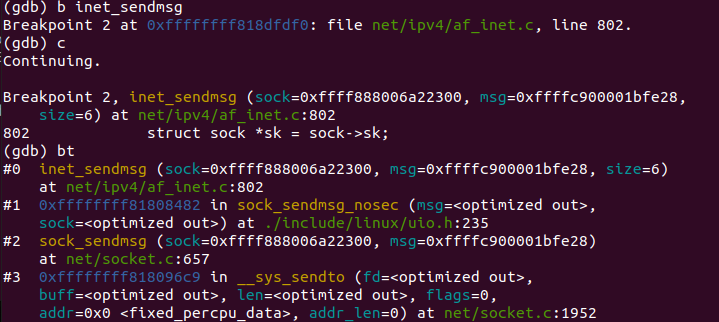
inet_sendmsg函数源代码如下:
1 int inet_sendmsg(struct socket *sock, struct msghdr *msg, size_t size) 2 { 3 struct sock *sk = sock->sk; 4 5 if (unlikely(inet_send_prepare(sk))) 6 return -EAGAIN; 7 8 return INDIRECT_CALL_2(sk->sk_prot->sendmsg, tcp_sendmsg, udp_sendmsg, 9 sk, msg, size); 10 } 11 EXPORT_SYMBOL(inet_sendmsg);
可以看出该函数具体到tcp_sendmsg和udp_sendmsg,这也是应用层的最后一个调用。
3.1.2、主机到主机层
主机到主机层负责数据包传输,有TCP的有连接和UDP的无连接,本次采用TCP,所以调用tcp_sendmsg负责发送,该函数给sk加锁后调用tcp_sendmsg_locked函数。tcp_sendmsg_locked函数源代码如下:
1 int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size) 2 { 3 struct tcp_sock *tp = tcp_sk(sk); 4 struct ubuf_info *uarg = NULL; 5 struct sk_buff *skb; 6 struct sockcm_cookie sockc; 7 int flags, err, copied = 0; 8 int mss_now = 0, size_goal, copied_syn = 0; 9 int process_backlog = 0; 10 bool zc = false; 11 long timeo; 12 13 flags = msg->msg_flags; 14 15 if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) { 16 skb = tcp_write_queue_tail(sk); 17 uarg = sock_zerocopy_realloc(sk, size, skb_zcopy(skb)); 18 if (!uarg) { 19 err = -ENOBUFS; 20 goto out_err; 21 } 22 23 zc = sk->sk_route_caps & NETIF_F_SG; 24 if (!zc) 25 uarg->zerocopy = 0; 26 } 27 28 if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) && 29 !tp->repair) { 30 err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size, uarg); 31 if (err == -EINPROGRESS && copied_syn > 0) 32 goto out; 33 else if (err) 34 goto out_err; 35 } 36 37 timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT); //超时标记 38 39 tcp_rate_check_app_limited(sk); /* is sending application-limited? */ 40 41 /* Wait for a connection to finish. One exception is TCP Fast Open 42 * (passive side) where data is allowed to be sent before a connection 43 * is fully established. 44 */ 45 if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) && 46 !tcp_passive_fastopen(sk)) { 47 err = sk_stream_wait_connect(sk, &timeo); 48 if (err != 0) 49 goto do_error; 50 } 51 52 if (unlikely(tp->repair)) { 53 if (tp->repair_queue == TCP_RECV_QUEUE) { 54 copied = tcp_send_rcvq(sk, msg, size); 55 goto out_nopush; 56 } 57 58 err = -EINVAL; 59 if (tp->repair_queue == TCP_NO_QUEUE) 60 goto out_err; 61 62 /* ‘common‘ sending to sendq */ 63 } 64 65 sockcm_init(&sockc, sk); 66 if (msg->msg_controllen) { 67 err = sock_cmsg_send(sk, msg, &sockc); 68 if (unlikely(err)) { 69 err = -EINVAL; 70 goto out_err; 71 } 72 } 73 74 /* This should be in poll */ 75 sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk); 76 77 /* Ok commence sending. */ 78 copied = 0; 79 80 restart: 81 mss_now = tcp_send_mss(sk, &size_goal, flags); 82 83 err = -EPIPE; 84 if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN)) 85 goto do_error; 86 87 while (msg_data_left(msg)) { 88 int copy = 0; 89 90 skb = tcp_write_queue_tail(sk); 91 if (skb) 92 copy = size_goal - skb->len; 93 94 if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) { 95 bool first_skb; 96 97 new_segment: 98 if (!sk_stream_memory_free(sk)) 99 goto wait_for_sndbuf; 100 101 if (unlikely(process_backlog >= 16)) { 102 process_backlog = 0; 103 if (sk_flush_backlog(sk)) 104 goto restart; 105 } 106 first_skb = tcp_rtx_and_write_queues_empty(sk); 107 skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, 108 first_skb); 109 if (!skb) 110 goto wait_for_memory; 111 112 process_backlog++; 113 skb->ip_summed = CHECKSUM_PARTIAL; 114 115 skb_entail(sk, skb); 116 copy = size_goal; 117 118 /* All packets are restored as if they have 119 * already been sent. skb_mstamp_ns isn‘t set to 120 * avoid wrong rtt estimation. 121 */ 122 if (tp->repair) 123 TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED; 124 } 125 126 /* Try to append data to the end of skb. */ 127 if (copy > msg_data_left(msg)) 128 copy = msg_data_left(msg); 129 130 /* Where to copy to? */ 131 if (skb_availroom(skb) > 0 && !zc) { 132 /* We have some space in skb head. Superb! */ 133 copy = min_t(int, copy, skb_availroom(skb)); 134 err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy); 135 if (err) 136 goto do_fault; 137 } else if (!zc) { 138 bool merge = true; 139 int i = skb_shinfo(skb)->nr_frags; 140 struct page_frag *pfrag = sk_page_frag(sk); 141 142 if (!sk_page_frag_refill(sk, pfrag)) 143 goto wait_for_memory; 144 145 if (!skb_can_coalesce(skb, i, pfrag->page, 146 pfrag->offset)) { 147 if (i >= sysctl_max_skb_frags) { 148 tcp_mark_push(tp, skb); 149 goto new_segment; 150 } 151 merge = false; 152 } 153 154 copy = min_t(int, copy, pfrag->size - pfrag->offset); 155 156 if (!sk_wmem_schedule(sk, copy)) 157 goto wait_for_memory; 158 159 err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb, 160 pfrag->page, 161 pfrag->offset, 162 copy); 163 if (err) 164 goto do_error; 165 166 //更新skb 167 if (merge) { 168 skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy); 169 } else { 170 skb_fill_page_desc(skb, i, pfrag->page, 171 pfrag->offset, copy); 172 page_ref_inc(pfrag->page); 173 } 174 pfrag->offset += copy; 175 } else { 176 err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg); 177 if (err == -EMSGSIZE || err == -EEXIST) { 178 tcp_mark_push(tp, skb); 179 goto new_segment; 180 } 181 if (err < 0) 182 goto do_error; 183 copy = err; 184 } 185 186 if (!copied) 187 TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH; 188 189 WRITE_ONCE(tp->write_seq, tp->write_seq + copy); 190 TCP_SKB_CB(skb)->end_seq += copy; 191 tcp_skb_pcount_set(skb, 0); 192 193 copied += copy; 194 if (!msg_data_left(msg)) { 195 if (unlikely(flags & MSG_EOR)) 196 TCP_SKB_CB(skb)->eor = 1; 197 goto out; 198 } 199 200 if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair)) 201 continue; 202 203 if (forced_push(tp)) { 204 tcp_mark_push(tp, skb); 205 __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH); 206 } else if (skb == tcp_send_head(sk)) 207 tcp_push_one(sk, mss_now); 208 continue; 209 210 wait_for_sndbuf: 211 set_bit(SOCK_NOSPACE, &sk->sk_socket->flags); 212 wait_for_memory: 213 if (copied) 214 tcp_push(sk, flags & ~MSG_MORE, mss_now, 215 TCP_NAGLE_PUSH, size_goal); 216 217 err = sk_stream_wait_memory(sk, &timeo); 218 if (err != 0) 219 goto do_error; 220 221 mss_now = tcp_send_mss(sk, &size_goal, flags); 222 } 223 224 out: 225 if (copied) { 226 tcp_tx_timestamp(sk, sockc.tsflags); 227 tcp_push(sk, flags, mss_now, tp->nonagle, size_goal); 228 } 229 out_nopush: 230 sock_zerocopy_put(uarg); 231 return copied + copied_syn; 232 233 do_error: 234 skb = tcp_write_queue_tail(sk); 235 do_fault: 236 tcp_remove_empty_skb(sk, skb); 237 238 if (copied + copied_syn) 239 goto out; 240 out_err: 241 sock_zerocopy_put_abort(uarg, true); 242 err = sk_stream_error(sk, flags, err); 243 /* make sure we wake any epoll edge trigger waiter */ 244 if (unlikely(tcp_rtx_and_write_queues_empty(sk) && err == -EAGAIN)) { 245 sk->sk_write_space(sk); 246 tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED); 247 } 248 return err; 249 } 250 EXPORT_SYMBOL_GPL(tcp_sendmsg_locked);
该函数要完成的工作就是将应用程序要发送的数据组织成skb,然后尽可能的发出去。
主要流程包括获取当前的MSS、网络设备支持的最大数据长度size_goal;遍历用户层的数据块数组,获取发送队列的最后一个skb,如果是尚未发送的,且长度尚未达到size_goal,那么可以往此skb继续追加数据,否则需要申请一个新的skb来装载数据。接下来就是拷贝消息头中的数据到skb中了,如果skb的线性数据区已经用完了,那么就使用分页区,拷贝成功后更新:送队列的最后一个序号、skb的结束序号、已经拷贝到发送队列的数据量,尽可能的将发送队列中的skb发送出去。
之后是TCP具体传输方式的实现tcp_write_xmit。到这里的函数调用栈为图10:
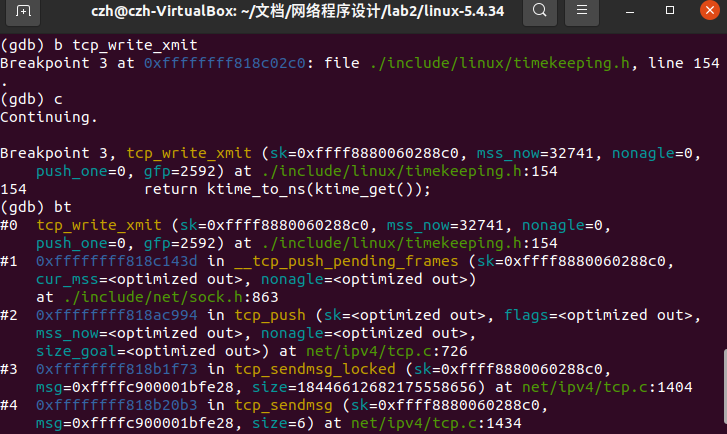
tcp_write_xmit函数源代码如下:
1 static int tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle, 2 int push_one, gfp_t gfp) 3 { 4 struct tcp_sock *tp = tcp_sk(sk); 5 struct sk_buff *skb; 6 unsigned int tso_segs, sent_pkts; 7 int cwnd_quota; 8 int result; 9 10 sent_pkts = 0; 11 12 if (!push_one) { 13 /* Do MTU probing. */ 14 result = tcp_mtu_probe(sk); 15 if (!result) { 16 return 0; 17 } else if (result > 0) { 18 sent_pkts = 1; 19 } 20 } 21 22 /*如果发送队列不为空,则准备开始发送报文*/ 23 while ((skb = tcp_send_head(sk))) { 24 unsigned int limit; 25 26 tso_segs = tcp_init_tso_segs(sk, skb, mss_now); 27 BUG_ON(!tso_segs); 28 29 cwnd_quota = tcp_cwnd_test(tp, skb); 30 if (!cwnd_quota) 31 break; 32 33 /*检测当前报文是否完全处于发送窗口内,如果是则可以发送,否则不能发送*/ 34 if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) 35 break; 36 37 if (tso_segs == 1) { 38 /*根据nagle算法,计算是否需要发送数据*/ 39 if (unlikely(!tcp_nagle_test(tp, skb, mss_now, 40 (tcp_skb_is_last(sk, skb) ? 41 nonagle : 42 TCP_NAGLE_PUSH)))) 43 break; 44 } else { 45 46 if (!push_one && tcp_tso_should_defer(sk, skb)) 47 break; 48 } 49 50 limit = mss_now; 51 52 if (tso_segs > 1 && !tcp_urg_mode(tp)) 53 limit = tcp_mss_split_point(sk, skb, mss_now, 54 cwnd_quota); 55 56 57 if (skb->len > limit && 58 unlikely(tso_fragment(sk, skb, limit, mss_now, gfp))) 59 break; 60 61 /*更新TCP时间戳,记录此报文发送的时间*/ 62 TCP_SKB_CB(skb)->when = tcp_time_stamp; 63 64 /*调用tcp_transmit_skb()发送TCP段*/ 65 if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp))) 66 break; 67 68 tcp_event_new_data_sent(sk, skb); 69 70 tcp_minshall_update(tp, mss_now, skb); 71 sent_pkts++; //更新已发送报文总数 72 73 if (push_one) 74 break; 75 } 76 77 /*如果本次有数据发送,则对TCP拥塞窗口进行检查确认。*/ 78 if (likely(sent_pkts)) { 79 tcp_cwnd_validate(sk); 80 return 0; 81 } 82 83 return !tp->packets_out && tcp_send_head(sk); 84 }
tcp_write_xmit()将发送队列上的SBK发送出去,返回值为0表示发送成功。函数执行过程主要有判断正在网络上传输的包数目是否超过拥塞窗口,如果超过了,则不发送;判断当前报文完全到达发送窗口;判断发送算法是否为nagle算法;通过以上判断后将该skb发送出去;更新发送窗口状态发送下一个skb。最终调用的是tcp_transmit_skb函数,又调用了__tcp_transmit_skb函数传输到IP协议相关参数。
__tcp_transmit_skb复制或者拷贝skb,构造skb中的tcp首部,并将调用主机到主机层的发送函数发送skb;在发送前,首先需要克隆或者复制skb,因为在成功发送到网络设备之后,skb会释放,而tcp层不能真正的释放,是需要等到对该数据段的ack才可以释放;然后构造tcp首部和选项;最后调用该层提供的发送回调函数发送skb,ip层即因特网层的回调函数为ip_queue_xmit。
3.1.3、因特网层
本层的功能主要与IP有关,包括路由,IP数据报等。之前的ip_queue_xmit函数调用__ip_queue_xmit函数以完成面向连接套接字的包输出。到此的函数调用栈如图11:
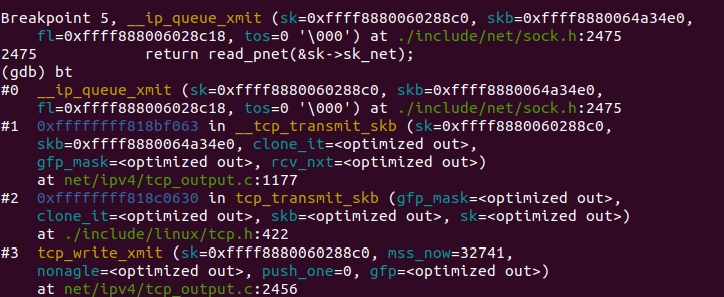
该函数源代码如下:
1 /* Note: skb->sk can be different from sk, in case of tunnels */ 2 int __ip_queue_xmit(struct sock *sk, struct sk_buff *skb, struct flowi *fl, 3 __u8 tos) 4 { 5 struct inet_sock *inet = inet_sk(sk); 6 struct net *net = sock_net(sk); 7 struct ip_options_rcu *inet_opt; 8 struct flowi4 *fl4; 9 struct rtable *rt; 10 struct iphdr *iph; 11 int res; 12 13 /* Skip all of this if the packet is already routed, 14 * f.e. by something like SCTP. 15 */ 16 rcu_read_lock(); 17 inet_opt = rcu_dereference(inet->inet_opt); 18 fl4 = &fl->u.ip4; 19 rt = skb_rtable(skb); 20 if (rt) 21 goto packet_routed; 22 23 /* Make sure we can route this packet. */ 24 rt = (struct rtable *)__sk_dst_check(sk, 0); 25 if (!rt) { 26 __be32 daddr; 27 28 /* Use correct destination address if we have options. */ 29 daddr = inet->inet_daddr; 30 if (inet_opt && inet_opt->opt.srr) 31 daddr = inet_opt->opt.faddr; 32 33 /* If this fails, retransmit mechanism of transport layer will 34 * keep trying until route appears or the connection times 35 * itself out. 36 */ 37 rt = ip_route_output_ports(net, fl4, sk, 38 daddr, inet->inet_saddr, 39 inet->inet_dport, 40 inet->inet_sport, 41 sk->sk_protocol, 42 RT_CONN_FLAGS_TOS(sk, tos), 43 sk->sk_bound_dev_if); 44 if (IS_ERR(rt)) 45 goto no_route; 46 sk_setup_caps(sk, &rt->dst); 47 } 48 skb_dst_set_noref(skb, &rt->dst); 49 50 packet_routed: 51 if (inet_opt && inet_opt->opt.is_strictroute && rt->rt_uses_gateway) 52 goto no_route; 53 54 /* OK, we know where to send it, allocate and build IP header. */ 55 skb_push(skb, sizeof(struct iphdr) + (inet_opt ? inet_opt->opt.optlen : 0)); 56 skb_reset_network_header(skb); 57 iph = ip_hdr(skb); 58 *((__be16 *)iph) = htons((4 << 12) | (5 << 8) | (tos & 0xff)); 59 if (ip_dont_fragment(sk, &rt->dst) && !skb->ignore_df) 60 iph->frag_off = htons(IP_DF); 61 else 62 iph->frag_off = 0; 63 iph->ttl = ip_select_ttl(inet, &rt->dst); 64 iph->protocol = sk->sk_protocol; 65 ip_copy_addrs(iph, fl4); 66 67 /* Transport layer set skb->h.foo itself. */ 68 69 if (inet_opt && inet_opt->opt.optlen) { 70 iph->ihl += inet_opt->opt.optlen >> 2; 71 ip_options_build(skb, &inet_opt->opt, inet->inet_daddr, rt, 0); 72 } 73 74 ip_select_ident_segs(net, skb, sk, 75 skb_shinfo(skb)->gso_segs ?: 1); 76 77 /* TODO : should we use skb->sk here instead of sk ? */ 78 skb->priority = sk->sk_priority; 79 skb->mark = sk->sk_mark; 80 81 res = ip_local_out(net, sk, skb); 82 rcu_read_unlock(); 83 return res; 84 85 no_route: 86 rcu_read_unlock(); 87 IP_INC_STATS(net, IPSTATS_MIB_OUTNOROUTES); 88 kfree_skb(skb); 89 return -EHOSTUNREACH; 90 } 91 EXPORT_SYMBOL(__ip_queue_xmit);
当套接字处于连接状态时,所有从套接字发出的包都具有确定的路由, 无需为每一个输出包查询它的目的入口,可将套接字直接绑定到路由入口上, 这由套接字的目的缓冲指针(dst_cache)来完成。ip_queue_xmit()首先为输入包建立IP包头, 经过本地包过滤器后,再将IP包分片输出(ip_fragment)。检查完分片之后,则会调用邻居子系统的输出函数neigh_output进行输出,输出则分为有二层头缓存和没有两种情况,有缓存时调用neigh_hh_output进行快速输出,没有缓存时,则调用邻居子系统的输出回调函数进行慢速输出。
3.1.4、网络接入层
Linux 用户想要使用网络功能,不能通过直接操作硬件完成,而需要直接或间接的操作一个 Linux 为我们抽象出来的设备,既通用的 Linux 网络设备来完成。本层的工作就是对抽象的网络设备进行选择传输。neigh_hh_output调用dev_queue_xmit函数,当前调用栈如图12:
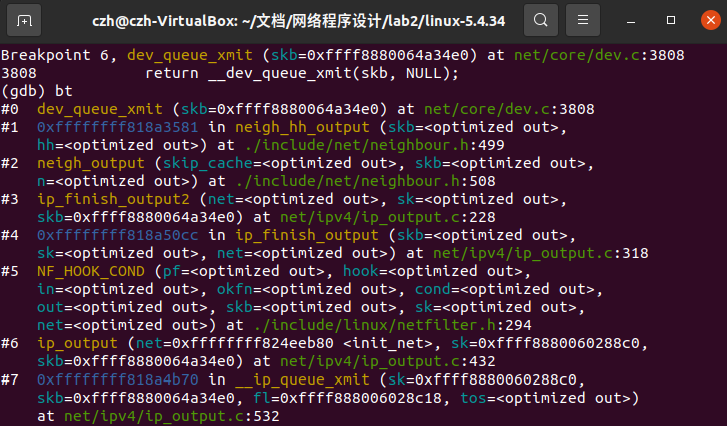
而dev_queue_xmit实际返回函数__dev_queue_xmit,函数源代码如下:
1 /** 2 * __dev_queue_xmit - transmit a buffer 3 * @skb: buffer to transmit 4 * @sb_dev: suboordinate device used for L2 forwarding offload 5 * 6 * Queue a buffer for transmission to a network device. The caller must 7 * have set the device and priority and built the buffer before calling 8 * this function. The function can be called from an interrupt. 9 * 10 * A negative errno code is returned on a failure. A success does not 11 * guarantee the frame will be transmitted as it may be dropped due 12 * to congestion or traffic shaping. 13 * 14 * ----------------------------------------------------------------------------------- 15 * I notice this method can also return errors from the queue disciplines, 16 * including NET_XMIT_DROP, which is a positive value. So, errors can also 17 * be positive. 18 * 19 * Regardless of the return value, the skb is consumed, so it is currently 20 * difficult to retry a send to this method. (You can bump the ref count 21 * before sending to hold a reference for retry if you are careful.) 22 * 23 * When calling this method, interrupts MUST be enabled. This is because 24 * the BH enable code must have IRQs enabled so that it will not deadlock. 25 * --BLG 26 */ 27 static int __dev_queue_xmit(struct sk_buff *skb, struct net_device *sb_dev) 28 { 29 struct net_device *dev = skb->dev; 30 struct netdev_queue *txq; 31 struct Qdisc *q; 32 int rc = -ENOMEM; 33 bool again = false; 34 35 skb_reset_mac_header(skb); 36 37 if (unlikely(skb_shinfo(skb)->tx_flags & SKBTX_SCHED_TSTAMP)) 38 __skb_tstamp_tx(skb, NULL, skb->sk, SCM_TSTAMP_SCHED); 39 40 /* Disable soft irqs for various locks below. Also 41 * stops preemption for RCU. 42 */ 43 rcu_read_lock_bh(); 44 45 skb_update_prio(skb); 46 47 qdisc_pkt_len_init(skb); 48 #ifdef CONFIG_NET_CLS_ACT 49 skb->tc_at_ingress = 0; 50 #ifdef CONFIG_NET_EGRESS 51 if (static_branch_unlikely(&egress_needed_key)) { 52 skb = sch_handle_egress(skb, &rc, dev); 53 if (!skb) 54 goto out; 55 } 56 #endif 57 #endif 58 /* If device/qdisc don‘t need skb->dst, release it right now while 59 * its hot in this cpu cache. 60 */ 61 if (dev->priv_flags & IFF_XMIT_DST_RELEASE) 62 skb_dst_drop(skb); 63 else 64 skb_dst_force(skb); 65 66 txq = netdev_core_pick_tx(dev, skb, sb_dev); 67 q = rcu_dereference_bh(txq->qdisc); 68 69 trace_net_dev_queue(skb); 70 if (q->enqueue) { 71 rc = __dev_xmit_skb(skb, q, dev, txq); 72 goto out; 73 } 74 75 /* The device has no queue. Common case for software devices: 76 * loopback, all the sorts of tunnels... 77 78 * Really, it is unlikely that netif_tx_lock protection is necessary 79 * here. (f.e. loopback and IP tunnels are clean ignoring statistics 80 * counters.) 81 * However, it is possible, that they rely on protection 82 * made by us here. 83 84 * Check this and shot the lock. It is not prone from deadlocks. 85 *Either shot noqueue qdisc, it is even simpler 8) 86 */ 87 if (dev->flags & IFF_UP) { 88 int cpu = smp_processor_id(); /* ok because BHs are off */ 89 90 if (txq->xmit_lock_owner != cpu) { 91 if (dev_xmit_recursion()) 92 goto recursion_alert; 93 94 skb = validate_xmit_skb(skb, dev, &again); 95 if (!skb) 96 goto out; 97 98 HARD_TX_LOCK(dev, txq, cpu); 99 100 if (!netif_xmit_stopped(txq)) { 101 dev_xmit_recursion_inc(); 102 skb = dev_hard_start_xmit(skb, dev, txq, &rc); 103 dev_xmit_recursion_dec(); 104 if (dev_xmit_complete(rc)) { 105 HARD_TX_UNLOCK(dev, txq); 106 goto out; 107 } 108 } 109 HARD_TX_UNLOCK(dev, txq); 110 net_crit_ratelimited( 111 "Virtual device %s asks to queue packet!\n", 112 dev->name); 113 } else { 114 /* Recursion is detected! It is possible, 115 * unfortunately 116 */ 117 recursion_alert: 118 net_crit_ratelimited( 119 "Dead loop on virtual device %s, fix it urgently!\n", 120 dev->name); 121 } 122 } 123 124 rc = -ENETDOWN; 125 rcu_read_unlock_bh(); 126 127 atomic_long_inc(&dev->tx_dropped); 128 kfree_skb_list(skb); 129 return rc; 130 out: 131 rcu_read_unlock_bh(); 132 return rc; 133 }
该函数是设备驱动程序执行传输的接口。也就是所有的数据包在填充完成后,最终发送数据时,都会调用该函数。从此函数可以看出,当驱动使用发送队列的时候会循环从队列中取出包向外发出,而不使用队列的时候只发送一次,如果没发送成功就直接丢弃。经过队列选择后,当前的函数调用栈如图13:
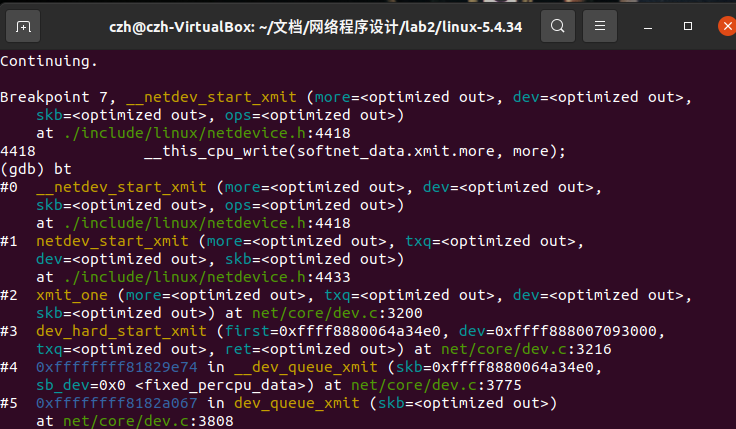
最后根据驱动配置相应的硬件进行传输。
3.2、recv过程源代码分析
3.2.1、网络接入层
Linux内核2.4以后,整个协议栈主要使用软中断softirq。软中断softirq优势明显,可以同时在多个 CPU 上执行。这一阶段会根据协议的不同来处理数据分组。CPU开始处理软中断 do_softirq,接着net_rx_action处理前面标记的NET_RX_SOFTIRQ,把出队列的skb送入相应列表处理(根据协议不同到不同的列表)。比如,IP分组交给ip_rcv处理,ARP分组交给 arp_rcv处理等,函数调用栈如图14所示:
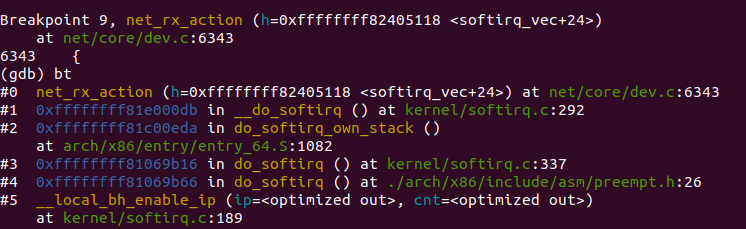
net_rx_action函数源代码如下:
1 static __latent_entropy void net_rx_action(struct softirq_action *h) 2 { 3 struct softnet_data *sd = this_cpu_ptr(&softnet_data); 4 unsigned long time_limit = jiffies + 5 usecs_to_jiffies(netdev_budget_usecs); 6 int budget = netdev_budget; 7 LIST_HEAD(list); 8 LIST_HEAD(repoll); 9 10 local_irq_disable(); 11 list_splice_init(&sd->poll_list, &list); 12 local_irq_enable(); 13 14 for (;;) { 15 struct napi_struct *n; 16 17 if (list_empty(&list)) { 18 if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll)) 19 goto out; 20 break; 21 } 22 23 n = list_first_entry(&list, struct napi_struct, poll_list); 24 budget -= napi_poll(n, &repoll); 25 26 /* If softirq window is exhausted then punt. 27 * Allow this to run for 2 jiffies since which will allow 28 * an average latency of 1.5/HZ. 29 */ 30 if (unlikely(budget <= 0 || 31 time_after_eq(jiffies, time_limit))) { 32 sd->time_squeeze++; 33 break; 34 } 35 } 36 37 local_irq_disable(); 38 39 list_splice_tail_init(&sd->poll_list, &list); 40 list_splice_tail(&repoll, &list); 41 list_splice(&list, &sd->poll_list); 42 if (!list_empty(&sd->poll_list)) 43 __raise_softirq_irqoff(NET_RX_SOFTIRQ); 44 45 net_rps_action_and_irq_enable(sd); 46 out: 47 __kfree_skb_flush(); 48 }
该函数调用设备的poll方法(默认为process_backlog),而process_backlog函数将进一步调用netif_receive_skb将数据包传上协议栈,如果设备自身注册了poll函数,也将调用netif_receive_skb函数。网桥的处理入口netif_receive_skb里面,针对IP协议,ip_rcv函数被调用。
3.2.2、因特网层
ip_rcv函数验证IP分组,比如目的地址是否本机地址,校验和是否正确等。若正确,则交给netfilter的NF_IP_PRE_ROUTING钩子,否则就丢弃。到了ip_rcv_finish函数,数据包就要根据skb结构的目的或路由信息判断数据包的去向。当前的函数调用栈如图15所示:
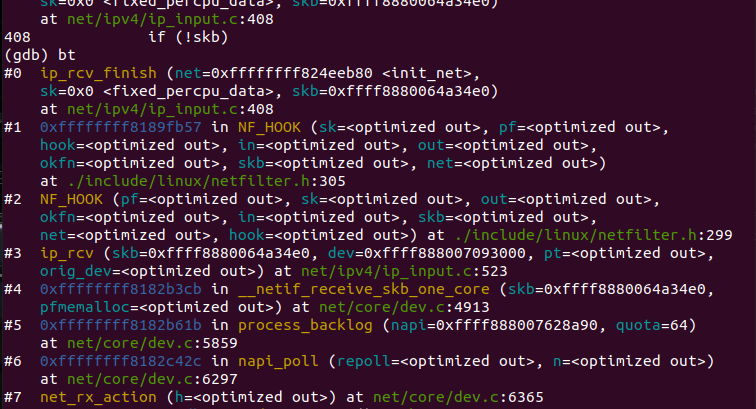
ip_rcv_finish函数源代码如下:
1 static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb) 2 { 3 struct net_device *dev = skb->dev; 4 int ret; 5 6 /* if ingress device is enslaved to an L3 master device pass the 7 * skb to its handler for processing 8 */ 9 skb = l3mdev_ip_rcv(skb); 10 if (!skb) 11 return NET_RX_SUCCESS; 12 13 ret = ip_rcv_finish_core(net, sk, skb, dev); 14 if (ret != NET_RX_DROP) 15 ret = dst_input(skb); 16 return ret; 17 }
ip_local_deliver处理到本机的数据分组;ip_forward处理需要转发的数据分组;ip_mr_input转发组播数据包。如果是转发的数据包,还需要找出出口设备和下一跳。具体来说,从skb->nh(IP头,由netif_receive_skb初始化)结构得到IP地址;而skb->dst 或许包含了数据分组到达目的地的路由信息,如果没有,则需要查找路由,如果最后结果显示目的地不可达,那么就丢弃该数据包。ip_rcv_finish函数最后执行dst_input,决定数据包的下一步的处理。
3.2.2、主机到主机层
由上一步ip_local_deliver得到协议为TCP,调用tcp_v4_rcv。tcp_v4_rcv函数主要做以下几个工作:
(1)设置TCP_CB
(2)查找控制块
(3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理
(4)接收TCP段。
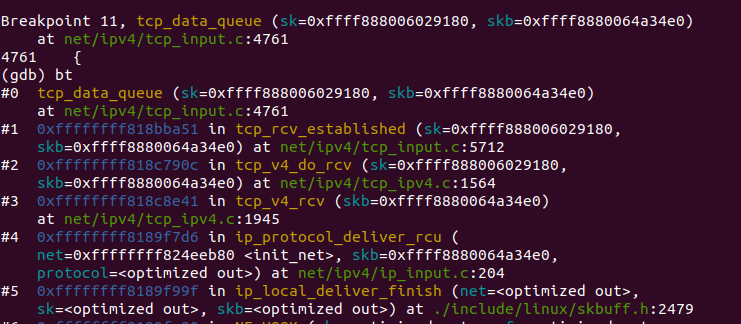
tcp_v4_rcv之后调用tcp_v4_do_rcv函数,该函数检查是否已连接套接字,若是已连接则调用tcp_rcv_established处理,其过程根据首部预测字段分为快速路径和慢速路径,区别在于检查的细致程度。
再由tcp_data_queue分多种情况接收处理数据段,当前函数调用栈如图16所示:
recvmsg系统调用在tcp层的实现是tcp_recvmsg函数,该函数完成从接收队列中读取数据复制到用户空间的任务:
函数在执行过程中会锁定控制块,避免软中断在tcp层的影响;
函数会涉及从接收队列receive_queue,预处理队列prequeue和后备队列backlog中读取数据;
其中从prequeue和backlog中读取的数据,还需要经过sk_backlog_rcv回调,该回调的实现为tcp_v4_do_rcv,实际上是先缓存到队列中,然后需要读取的时候,才进入协议栈处理。
此时,是在进程上下文执行的,因为会设置tp->ucopy.task=current,在协议栈处理过程中,会直接将数据复制到用户空间。
3.2.2、应用层
recv过程的该层函数调用与send过程类似,内核函数为__sys_recvfrom,通过调用sock_recvmsg来对数据进行接收,该函数实际调用的是sock->ops->recvmsg(sock, msg, msg_data_left(msg), flags);同样类似send过程中,调用的实际上是socket在初始化时赋值给结构体struct proto tcp_prot的函数tcp_rcvmsg,由此与下层函数相连,函数调用栈如图17所示:
4、时序图
标签:封装 send possible memory 决定 pst guarantee 调用接口 可重入函数
原文地址:https://www.cnblogs.com/yi-qian/p/14348176.html