标签:user 出版 using download doc 官方 tail acl rpo
MHA(Master High Availability Manager and tools for MySQL)目前在MySQL高可用方面是一个相对成熟的解决方案,它是由日本人youshimaton采用Perl语言编写的一个脚本管理工具。MHA是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。MHA仅适用于MySQL Replication环境,目的在于维持Master主库的高可用性。在MySQL故障切换过程中,MHA能做到0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能最大程度上保证数据库的一致性,以达到真正意义上的高可用。
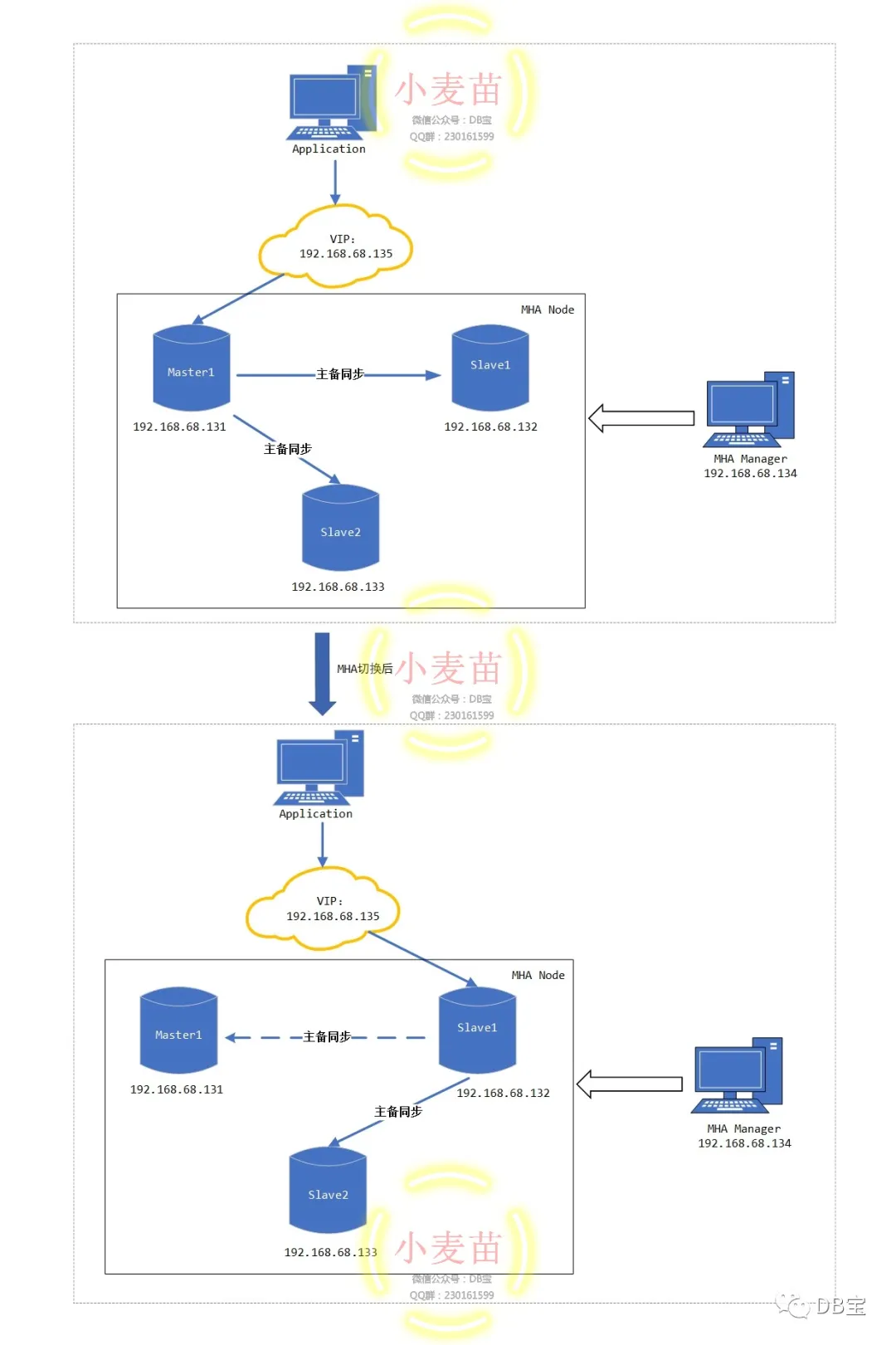
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群必须最少有3台数据库服务器,一主二从,即一台充当Master,一台充当备用Master,另一台充当从库。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中Master节点。当Master出现故障时,它可以自动将具有最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应用程序是完全透明的。MHA node运行在每台MySQL服务器上,它通过监控具备解析和清理logs功能的脚本来加快故障转移的。
Manager工具包情况如下:
- masterha_check_ssh:检查MHA的SSH配置情况。
- masterha_check_repl:检查MySQL复制状况。
- masterha_manager:启动MHA。
- masterha_check_status:检测当前MHA运行状态。
- masterha_master_monitor:检测Master是否宕机。
- masterha_master_switch:控制故障转移(自动或手动)。
- masterha_conf_host:添加或删除配置的server信息。
Node工具包(通常由MHA Manager的脚本触发,无需人工操作)情况如下:l
- save_binary_logs:保存和复制Master的binlog日志。
- apply_diff_relay_logs:识别差异的中级日志时间并将其应用到其他Slave。
- filter_mysqlbinlog:去除不必要的ROOLBACK事件(已经废弃)
- purge_relay_logs:清除中继日志(不阻塞SQL线程)
本文所使用的MHA架构规划如下表:
| IP | 主机名 | 作用 | Server ID | Port | 类型 | 备注 |
|---|---|---|---|---|---|---|
| 192.168.68.131 | MHA-LHR-Master1-ip131 | master node | 573306131 | 3306 | 写入 | 对外提供写服务 |
| 192.168.68.132 | MHA-LHR-Slave1-ip132 | slave node1 (Candicate Master) | 573306132 | 读 | 备选Master提供读服务 | |
| 192.168.68.133 | MHA-LHR-Slave2-ip133 | slave node2 | 573306133 | 读 | 提供读服务 | |
| 192.168.68.134 | MHA-LHR-Monitor-ip134 | Monitor host | 监控其它机器,一旦Mater宕机,将会把备选Master提升为新的Master,而将Slave指向新的Master | |||
| 192.168.68.135 | VIP | 在131和132之间进行浮动漂移 | ||||
| MySQL数据库版本:MySQL 5.7.30,MySQL节点端口都是3306,各自的server_id不一样 |
MHA切换前和切换后的架构图:
# 下载镜像
docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-master1-ip131
docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-slave1-ip132
docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-slave2-ip133
docker pull registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-monitor-ip134
# 重命名镜像
docker tag registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-master1-ip131 lhrbest/mha-lhr-master1-ip131
docker tag registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-slave1-ip132 lhrbest/mha-lhr-slave1-ip132
docker tag registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-slave2-ip133 lhrbest/mha-lhr-slave2-ip133
docker tag registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-monitor-ip134 lhrbest/mha-lhr-monitor-ip134
一共4个镜像,3个MHA Node,一个MHA Manager,压缩包大概3G,下载完成后:
[root@lhrdocker ~]# docker images | grep mha
registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-monitor-ip134 latest 7d29597dc997 14 hours ago 1.53GB
registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-slave2-ip133 latest d3717794e93a 40 hours ago 4.56GB
registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-slave1-ip132 latest f62ee813e487 40 hours ago 4.56GB
registry.cn-hangzhou.aliyuncs.com/lhrbest/mha-lhr-master1-ip131 latest ae7be48d83dc 40 hours ago 4.56GB
编辑yml文件,使用docker-compose来创建MHA相关容器,注意docker-compose.yml文件的格式,对空格、缩进、对齐都有严格要求:
# 创建存放yml文件的路径
mkdir -p /root/mha
# 编辑文件/root/mha/docker-compose.yml
cat > /root/mha/docker-compose.yml <<"EOF"
version: ‘3.8‘
services:
MHA-LHR-Master1-ip131:
container_name: "MHA-LHR-Master1-ip131"
restart: "always"
hostname: MHA-LHR-Master1-ip131
privileged: true
image: lhrbest/mha-lhr-master1-ip131
ports:
- "33061:3306"
- "2201:22"
networks:
mhalhr:
ipv4_address: 192.168.68.131
MHA-LHR-Slave1-ip132:
container_name: "MHA-LHR-Slave1-ip132"
restart: "always"
hostname: MHA-LHR-Slave1-ip132
privileged: true
image: lhrbest/mha-lhr-slave1-ip132
ports:
- "33062:3306"
- "2202:22"
networks:
mhalhr:
ipv4_address: 192.168.68.132
MHA-LHR-Slave2-ip133:
container_name: "MHA-LHR-Slave2-ip133"
restart: "always"
hostname: MHA-LHR-Master1-ip131
privileged: true
image: lhrbest/mha-lhr-slave2-ip133
ports:
- "33063:3306"
- "2203:22"
networks:
mhalhr:
ipv4_address: 192.168.68.133
MHA-LHR-Monitor-ip134:
container_name: "MHA-LHR-Monitor-ip134"
restart: "always"
hostname: MHA-LHR-Monitor-ip134
privileged: true
image: lhrbest/mha-lhr-monitor-ip134
ports:
- "33064:3306"
- "2204:22"
networks:
mhalhr:
ipv4_address: 192.168.68.134
networks:
mhalhr:
name: mhalhr
ipam:
config:
- subnet: "192.168.68.0/16"
EOF
安装 Docker Compose官方文档:https://docs.docker.com/compose/
编辑docker-compose.yml文件官方文档:https://docs.docker.com/compose/compose-file/
[root@lhrdocker ~]# curl --insecure -L https://github.com/docker/compose/releases/download/1.26.2/docker-compose-Linux-x86_64 -o /usr/local/bin/docker-compose
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 638 100 638 0 0 530 0 0:00:01 0:00:01 --:--:-- 531
100 11.6M 100 11.6M 0 0 1994k 0 0:00:06 0:00:06 --:--:-- 2943k
[root@lhrdocker ~]# chmod +x /usr/local/bin/docker-compose
[root@lhrdocker ~]# docker-compose -v
docker-compose version 1.26.2, build eefe0d31
# 启动mha环境的容器,一定要进入文件夹/root/mha/后再操作
[root@lhrdocker ~]# cd /root/mha/
[root@lhrdocker mha]#
[root@lhrdocker mha]# docker-compose up -d
Creating network "mhalhr" with the default driver
Creating MHA-LHR-Monitor-ip134 ... done
Creating MHA-LHR-Slave2-ip133 ... done
Creating MHA-LHR-Master1-ip131 ... done
Creating MHA-LHR-Slave1-ip132 ... done
[root@lhrdocker mha]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d5b1af2ca979 lhrbest/mha-lhr-slave1-ip132 "/usr/sbin/init" 12 seconds ago Up 9 seconds 16500-16599/tcp, 0.0.0.0:2202->22/tcp, 0.0.0.0:33062->3306/tcp MHA-LHR-Slave1-ip132
8fa79f476aaa lhrbest/mha-lhr-master1-ip131 "/usr/sbin/init" 12 seconds ago Up 10 seconds 16500-16599/tcp, 0.0.0.0:2201->22/tcp, 0.0.0.0:33061->3306/tcp MHA-LHR-Master1-ip131
74407b9df567 lhrbest/mha-lhr-slave2-ip133 "/usr/sbin/init" 12 seconds ago Up 10 seconds 16500-16599/tcp, 0.0.0.0:2203->22/tcp, 0.0.0.0:33063->3306/tcp MHA-LHR-Slave2-ip133
83f1cab03c9b lhrbest/mha-lhr-monitor-ip134 "/usr/sbin/init" 12 seconds ago Up 10 seconds 0.0.0.0:2204->22/tcp, 0.0.0.0:33064->3306/tcp MHA-LHR-Monitor-ip134
[root@lhrdocker mha]#
# 给MHA加入默认的网卡
docker network connect bridge MHA-LHR-Master1-ip131
docker network connect bridge MHA-LHR-Slave1-ip132
docker network connect bridge MHA-LHR-Slave2-ip133
docker network connect bridge MHA-LHR-Monitor-ip134
注意:请确保这4个节点的eth0都是192.168.68.0网段,否则后续的MHA切换可能会出问题。如果不一致,那么可以使用如下命令修改:
# 删除网卡 docker network disconnect bridge MHA-LHR-Master1-ip131 docker network disconnect mhalhr MHA-LHR-Master1-ip131 # 重启容器 docker restart MHA-LHR-Master1-ip131 # 添加网卡 docker network connect mhalhr MHA-LHR-Master1-ip131 --ip 192.168.68.131 docker network connect bridge MHA-LHR-Master1-ip131
# 进入管理节点134
docker exec -it MHA-LHR-Monitor-ip134 bash
# 修改/etc/hosts文件
cat >> /etc/hosts << EOF
192.168.68.131 MHA-LHR-Master1-ip131
192.168.68.132 MHA-LHR-Slave1-ip132
192.168.68.133 MHA-LHR-Slave2-ip133
192.168.68.134 MHA-LHR-Monitor-ip134
EOF
# 进入主库131
docker exec -it MHA-LHR-Master1-ip131 bash
# 添加VIP135
/sbin/ifconfig eth0:1 192.168.68.135/24
ifconfig
添加完成后:
[root@MHA-LHR-Master1-ip131 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.131 netmask 255.255.0.0 broadcast 192.168.255.255
ether 02:42:c0:a8:44:83 txqueuelen 0 (Ethernet)
RX packets 220 bytes 15883 (15.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 189 bytes 17524 (17.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.135 netmask 255.255.255.0 broadcast 192.168.68.255
ether 02:42:c0:a8:44:83 txqueuelen 0 (Ethernet)
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.2 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:ac:11:00:02 txqueuelen 0 (Ethernet)
RX packets 31 bytes 2697 (2.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 14 bytes 3317 (3.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 5 bytes 400 (400.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5 bytes 400 (400.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 管理节点已经可以ping通VIP了
[root@MHA-LHR-Monitor-ip134 /]# ping 192.168.68.135
PING 192.168.68.135 (192.168.68.135) 56(84) bytes of data.
64 bytes from 192.168.68.135: icmp_seq=1 ttl=64 time=0.172 ms
64 bytes from 192.168.68.135: icmp_seq=2 ttl=64 time=0.076 ms
^C
--- 192.168.68.135 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.076/0.124/0.172/0.048 ms
-- 132节点
mysql -h192.168.59.220 -uroot -plhr -P33062
reset slave;
start slave;
show slave status \G
-- 133节点
mysql -h192.168.59.220 -uroot -plhr -P33063
reset slave;
start slave;
show slave status \G
结果:
C:\Users\lhrxxt>mysql -h192.168.59.220 -uroot -plhr -P33062
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.30-log MySQL Community Server (GPL)
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type ‘help;‘ or ‘\h‘ for help. Type ‘\c‘ to clear the current input statement.
MySQL [(none)]> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
MySQL [(none)]> reset slave;
Query OK, 0 rows affected (0.02 sec)
MySQL [(none)]> start slave;
Query OK, 0 rows affected (0.01 sec)
MySQL [(none)]> show slave status \G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.68.131
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: MHA-LHR-Master1-ip131-bin.000011
Read_Master_Log_Pos: 234
Relay_Log_File: MHA-LHR-Master1-ip131-relay-bin.000003
Relay_Log_Pos: 399
Relay_Master_Log_File: MHA-LHR-Master1-ip131-bin.000011
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB: information_schema,performance_schema,mysql,sys
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 234
Relay_Log_Space: 799
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 573306131
Master_UUID: c8ca4f1d-aec3-11ea-942b-0242c0a84483
Master_Info_File: /usr/local/mysql-5.7.30-linux-glibc2.12-x86_64/data/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: c8ca4f1d-aec3-11ea-942b-0242c0a84483:1-11,
d24a77d1-aec3-11ea-9399-0242c0a84484:1-3
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
至此,我们就把MHA环境准备好了,接下来就开始测试MHA的各项功能。
在正式测试之前,我们要保证MHA环境已经配置正确,且MHA管理进程已经启动。
在Manager节点检查SSH、复制及MHA的状态。
[root@MHA-LHR-Monitor-ip134 /]# masterha_check_ssh --conf=/etc/mha/mha.cnf
Sat Aug 8 09:57:42 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 8 09:57:42 2020 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Sat Aug 8 09:57:42 2020 - [info] Reading server configuration from /etc/mha/mha.cnf..
Sat Aug 8 09:57:42 2020 - [info] Starting SSH connection tests..
Sat Aug 8 09:57:43 2020 - [debug]
Sat Aug 8 09:57:42 2020 - [debug] Connecting via SSH from root@192.168.68.131(192.168.68.131:22) to root@192.168.68.132(192.168.68.132:22)..
Sat Aug 8 09:57:42 2020 - [debug] ok.
Sat Aug 8 09:57:42 2020 - [debug] Connecting via SSH from root@192.168.68.131(192.168.68.131:22) to root@192.168.68.133(192.168.68.133:22)..
Sat Aug 8 09:57:42 2020 - [debug] ok.
Sat Aug 8 09:57:43 2020 - [debug]
Sat Aug 8 09:57:42 2020 - [debug] Connecting via SSH from root@192.168.68.132(192.168.68.132:22) to root@192.168.68.131(192.168.68.131:22)..
Sat Aug 8 09:57:42 2020 - [debug] ok.
Sat Aug 8 09:57:42 2020 - [debug] Connecting via SSH from root@192.168.68.132(192.168.68.132:22) to root@192.168.68.133(192.168.68.133:22)..
Sat Aug 8 09:57:43 2020 - [debug] ok.
Sat Aug 8 09:57:44 2020 - [debug]
Sat Aug 8 09:57:43 2020 - [debug] Connecting via SSH from root@192.168.68.133(192.168.68.133:22) to root@192.168.68.131(192.168.68.131:22)..
Sat Aug 8 09:57:43 2020 - [debug] ok.
Sat Aug 8 09:57:43 2020 - [debug] Connecting via SSH from root@192.168.68.133(192.168.68.133:22) to root@192.168.68.132(192.168.68.132:22)..
Sat Aug 8 09:57:43 2020 - [debug] ok.
Sat Aug 8 09:57:44 2020 - [info] All SSH connection tests passed successfully.
结果“All SSH connection tests passed successfully.”表示MHA的3个数据节点之间的SSH是正常的。
[root@MHA-LHR-Monitor-ip134 /]# masterha_check_repl --conf=/etc/mha/mha.cnf
Sat Aug 8 09:59:31 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 8 09:59:31 2020 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Sat Aug 8 09:59:31 2020 - [info] Reading server configuration from /etc/mha/mha.cnf..
Sat Aug 8 09:59:31 2020 - [info] MHA::MasterMonitor version 0.58.
Sat Aug 8 09:59:33 2020 - [info] GTID failover mode = 1
Sat Aug 8 09:59:33 2020 - [info] Dead Servers:
Sat Aug 8 09:59:33 2020 - [info] Alive Servers:
Sat Aug 8 09:59:33 2020 - [info] 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 09:59:33 2020 - [info] 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 09:59:33 2020 - [info] 192.168.68.133(192.168.68.133:3306)
Sat Aug 8 09:59:33 2020 - [info] Alive Slaves:
Sat Aug 8 09:59:33 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 09:59:33 2020 - [info] GTID ON
Sat Aug 8 09:59:33 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 09:59:33 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Aug 8 09:59:33 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 09:59:33 2020 - [info] GTID ON
Sat Aug 8 09:59:33 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 09:59:33 2020 - [info] Current Alive Master: 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 09:59:33 2020 - [info] Checking slave configurations..
Sat Aug 8 09:59:33 2020 - [info] read_only=1 is not set on slave 192.168.68.132(192.168.68.132:3306).
Sat Aug 8 09:59:33 2020 - [info] read_only=1 is not set on slave 192.168.68.133(192.168.68.133:3306).
Sat Aug 8 09:59:33 2020 - [info] Checking replication filtering settings..
Sat Aug 8 09:59:33 2020 - [info] binlog_do_db= , binlog_ignore_db= information_schema,mysql,performance_schema,sys
Sat Aug 8 09:59:33 2020 - [info] Replication filtering check ok.
Sat Aug 8 09:59:33 2020 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Sat Aug 8 09:59:33 2020 - [info] Checking SSH publickey authentication settings on the current master..
Sat Aug 8 09:59:33 2020 - [info] HealthCheck: SSH to 192.168.68.131 is reachable.
Sat Aug 8 09:59:33 2020 - [info]
192.168.68.131(192.168.68.131:3306) (current master)
+--192.168.68.132(192.168.68.132:3306)
+--192.168.68.133(192.168.68.133:3306)
Sat Aug 8 09:59:33 2020 - [info] Checking replication health on 192.168.68.132..
Sat Aug 8 09:59:33 2020 - [info] ok.
Sat Aug 8 09:59:33 2020 - [info] Checking replication health on 192.168.68.133..
Sat Aug 8 09:59:33 2020 - [info] ok.
Sat Aug 8 09:59:33 2020 - [info] Checking master_ip_failover_script status:
Sat Aug 8 09:59:33 2020 - [info] /usr/local/mha/scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.68.131 --orig_master_ip=192.168.68.131 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ip addr del 192.168.68.135/24 dev eth0==/sbin/ifconfig eth0:1 192.168.68.135/24===
Checking the Status of the script.. OK
Sat Aug 8 09:59:33 2020 - [info] OK.
Sat Aug 8 09:59:33 2020 - [warning] shutdown_script is not defined.
Sat Aug 8 09:59:33 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
“MySQL Replication Health is OK.”表示1主2从的架构目前是正常的。
[root@MHA-LHR-Monitor-ip134 /]# masterha_check_status --conf=/etc/mha/mha.cnf
mha is stopped(2:NOT_RUNNING).
注意:如果正常,会显示“PING_OK",否则会显示“NOT_RUNNING",这代表MHA监控没有开启。
[root@MHA-LHR-Monitor-ip134 /]# nohup masterha_manager --conf=/etc/mha/mha.cnf --ignore_last_failover < /dev/null > /usr/local/mha/manager_start.log 2>&1 &
[1] 216
[root@MHA-LHR-Monitor-ip134 /]# masterha_check_status --conf=/etc/mha/mha.cnf
mha (pid:216) is running(0:PING_OK), master:192.168.68.131
检查结果显示“PING_OK”,表示MHA监控软件已经启动了,主库为192.168.68.131。
启动参数介绍:
--remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的IP将会从配置文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,默认情况下,MHA发生切换后会在日志目录下产生mha.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,为了方便,这里设置为--ignore_last_failover。
注意,一旦自动failover发生,mha manager就停止监控了,如果需要请手动再次开启。
masterha_stop --conf=/etc/mha/mha.cnf
我们当然不关闭,不能执行这句哟。
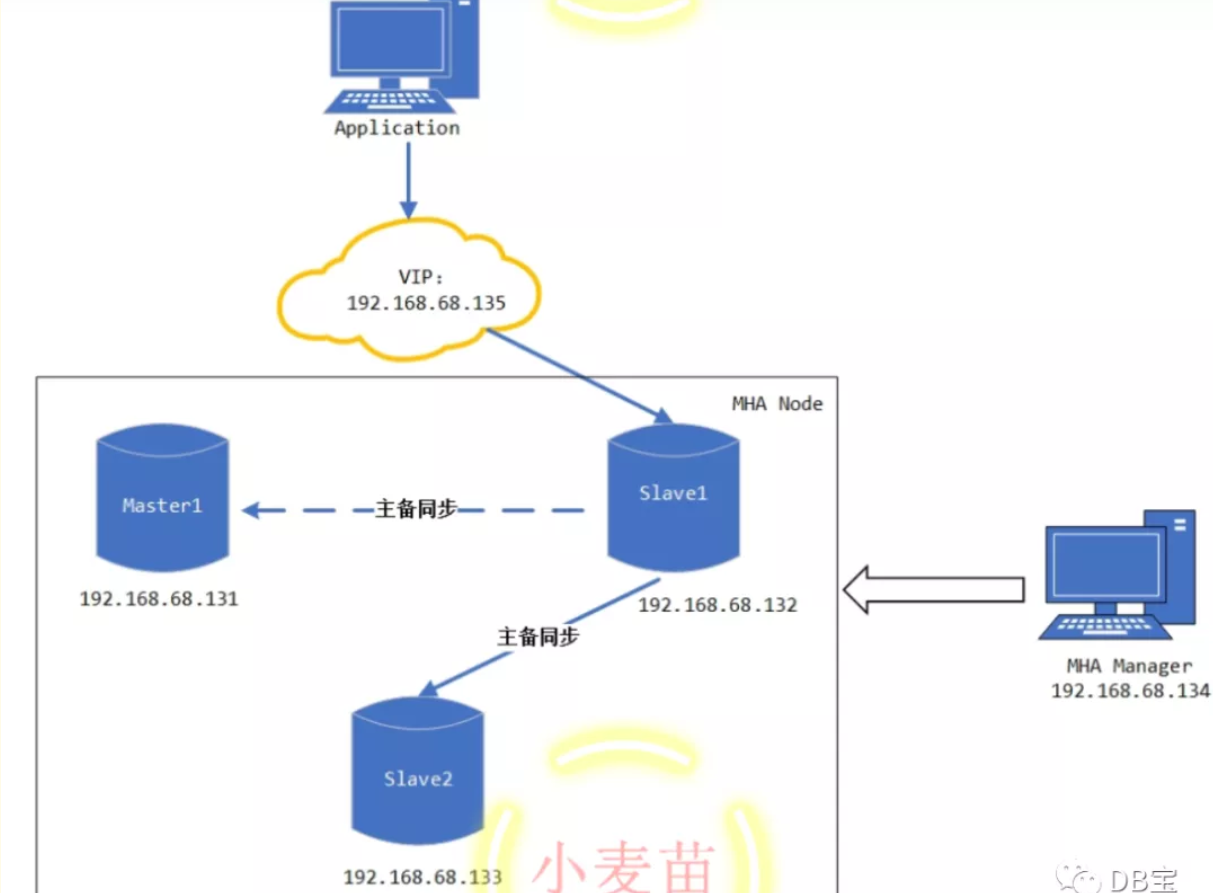
自动故障转移后的架构如下图所示:
按照以下流程测试:
[root@lhrdocker ~]# mysql -uroot -plhr -h192.168.68.135 -P3306
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 10
Server version: 5.7.30-log MySQL Community Server (GPL)
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type ‘help;‘ or ‘\h‘ for help. Type ‘\c‘ to clear the current input statement.
mysql> select @@hostname;
+-----------------------+
| @@hostname |
+-----------------------+
| MHA-LHR-Master1-ip131 |
+-----------------------+
1 row in set (0.00 sec)
mysql> show slave hosts;
+-----------+----------------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+----------------+------+-----------+--------------------------------------+
| 573306133 | 192.168.68.133 | 3306 | 573306131 | d391ce7e-aec3-11ea-94cd-0242c0a84485 |
| 573306132 | 192.168.68.132 | 3306 | 573306131 | d24a77d1-aec3-11ea-9399-0242c0a84484 |
+-----------+----------------+------+-----------+--------------------------------------+
2 rows in set (0.00 sec)
docker stop MHA-LHR-Master1-ip131
① VIP135自动漂移到132
[root@MHA-LHR-Slave1-ip132 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.132 netmask 255.255.0.0 broadcast 192.168.255.255
ether 02:42:c0:a8:44:84 txqueuelen 0 (Ethernet)
RX packets 411 bytes 58030 (56.6 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 343 bytes 108902 (106.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.68.135 netmask 255.255.255.0 broadcast 192.168.68.255
ether 02:42:c0:a8:44:84 txqueuelen 0 (Ethernet)
② 主库自动变为132,命令为:show slave hosts;
mysql> select @@hostname;
ERROR 2013 (HY000): Lost connection to MySQL server during query
mysql> select @@hostname;
ERROR 2006 (HY000): MySQL server has gone away
No connection. Trying to reconnect...
Connection id: 15
Current database: *** NONE ***
+----------------------+
| @@hostname |
+----------------------+
| MHA-LHR-Slave1-ip132 |
+----------------------+
1 row in set (0.00 sec)
mysql> show slave hosts;
+-----------+----------------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+----------------+------+-----------+--------------------------------------+
| 573306133 | 192.168.68.133 | 3306 | 573306132 | d391ce7e-aec3-11ea-94cd-0242c0a84485 |
+-----------+----------------+------+-----------+--------------------------------------+
1 row in set (0.00 sec)
③ MHA进程自动停止
[1]+ Done nohup masterha_manager --conf=/etc/mha/mha.cnf --ignore_last_failover < /dev/null > /usr/local/mha/manager_start.log 2>&1
[root@MHA-LHR-Monitor-ip134 /]#
[root@MHA-LHR-Monitor-ip134 /]#
[root@MHA-LHR-Monitor-ip134 /]# ps -ef|grep mha
root 486 120 0 11:03 pts/0 00:00:00 grep --color=auto mha
④ MHA切换过程日志:
[root@MHA-LHR-Monitor-ip134 /]# tailf /usr/local/mha/manager_running.log
Sat Aug 8 11:01:23 2020 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query)
Sat Aug 8 11:01:23 2020 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s MHA-LHR-Slave1-ip132 -s MHA-LHR-Slave2-ip133 --user=root --master_host=MHA-LHR-Master1-ip131 --master_ip=192.168.68.131 --master_port=3306 --user=root --master_host=192.168.68.131 --master_ip=192.168.68.131 --master_port=3306 --master_user=mha --master_password=lhr --ping_type=SELECT
Sat Aug 8 11:01:23 2020 - [info] Executing SSH check script: exit 0
Sat Aug 8 11:01:23 2020 - [warning] HealthCheck: SSH to 192.168.68.131 is NOT reachable.
Monitoring server MHA-LHR-Slave1-ip132 is reachable, Master is not reachable from MHA-LHR-Slave1-ip132. OK.
Monitoring server MHA-LHR-Slave2-ip133 is reachable, Master is not reachable from MHA-LHR-Slave2-ip133. OK.
Sat Aug 8 11:01:23 2020 - [info] Master is not reachable from all other monitoring servers. Failover should start.
Sat Aug 8 11:01:24 2020 - [warning] Got error on MySQL connect: 2003 (Can‘t connect to MySQL server on ‘192.168.68.131‘ (4))
Sat Aug 8 11:01:24 2020 - [warning] Connection failed 2 time(s)..
Sat Aug 8 11:01:25 2020 - [warning] Got error on MySQL connect: 2003 (Can‘t connect to MySQL server on ‘192.168.68.131‘ (4))
Sat Aug 8 11:01:25 2020 - [warning] Connection failed 3 time(s)..
Sat Aug 8 11:01:26 2020 - [warning] Got error on MySQL connect: 2003 (Can‘t connect to MySQL server on ‘192.168.68.131‘ (4))
Sat Aug 8 11:01:26 2020 - [warning] Connection failed 4 time(s)..
Sat Aug 8 11:01:26 2020 - [warning] Master is not reachable from health checker!
Sat Aug 8 11:01:26 2020 - [warning] Master 192.168.68.131(192.168.68.131:3306) is not reachable!
Sat Aug 8 11:01:26 2020 - [warning] SSH is NOT reachable.
Sat Aug 8 11:01:26 2020 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/mha/mha.cnf again, and trying to connect to all servers to check server status..
Sat Aug 8 11:01:26 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 8 11:01:26 2020 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:01:26 2020 - [info] Reading server configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:01:27 2020 - [info] GTID failover mode = 1
Sat Aug 8 11:01:27 2020 - [info] Dead Servers:
Sat Aug 8 11:01:27 2020 - [info] 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:27 2020 - [info] Alive Servers:
Sat Aug 8 11:01:27 2020 - [info] 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:01:27 2020 - [info] 192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:01:27 2020 - [info] Alive Slaves:
Sat Aug 8 11:01:27 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:27 2020 - [info] GTID ON
Sat Aug 8 11:01:27 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:27 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Aug 8 11:01:27 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:27 2020 - [info] GTID ON
Sat Aug 8 11:01:27 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:27 2020 - [info] Checking slave configurations..
Sat Aug 8 11:01:27 2020 - [info] read_only=1 is not set on slave 192.168.68.132(192.168.68.132:3306).
Sat Aug 8 11:01:27 2020 - [info] read_only=1 is not set on slave 192.168.68.133(192.168.68.133:3306).
Sat Aug 8 11:01:27 2020 - [info] Checking replication filtering settings..
Sat Aug 8 11:01:27 2020 - [info] Replication filtering check ok.
Sat Aug 8 11:01:27 2020 - [info] Master is down!
Sat Aug 8 11:01:27 2020 - [info] Terminating monitoring script.
Sat Aug 8 11:01:27 2020 - [info] Got exit code 20 (Master dead).
Sat Aug 8 11:01:27 2020 - [info] MHA::MasterFailover version 0.58.
Sat Aug 8 11:01:27 2020 - [info] Starting master failover.
Sat Aug 8 11:01:27 2020 - [info]
Sat Aug 8 11:01:27 2020 - [info] * Phase 1: Configuration Check Phase..
Sat Aug 8 11:01:27 2020 - [info]
Sat Aug 8 11:01:29 2020 - [info] GTID failover mode = 1
Sat Aug 8 11:01:29 2020 - [info] Dead Servers:
Sat Aug 8 11:01:29 2020 - [info] 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:29 2020 - [info] Checking master reachability via MySQL(double check)...
Sat Aug 8 11:01:30 2020 - [info] ok.
Sat Aug 8 11:01:30 2020 - [info] Alive Servers:
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:01:30 2020 - [info] Alive Slaves:
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info] Starting GTID based failover.
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] ** Phase 1: Configuration Check Phase completed.
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 2: Dead Master Shutdown Phase..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] Forcing shutdown so that applications never connect to the current master..
Sat Aug 8 11:01:30 2020 - [info] Executing master IP deactivation script:
Sat Aug 8 11:01:30 2020 - [info] /usr/local/mha/scripts/master_ip_failover --orig_master_host=192.168.68.131 --orig_master_ip=192.168.68.131 --orig_master_port=3306 --command=stop
IN SCRIPT TEST====/sbin/ip addr del 192.168.68.135/24 dev eth0==/sbin/ifconfig eth0:1 192.168.68.135/24===
Disabling the VIP on old master: 192.168.68.131
Sat Aug 8 11:01:30 2020 - [info] done.
Sat Aug 8 11:01:30 2020 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Sat Aug 8 11:01:30 2020 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 3: Master Recovery Phase..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] The latest binary log file/position on all slaves is MHA-LHR-Master1-ip131-bin.000011:234
Sat Aug 8 11:01:30 2020 - [info] Latest slaves (Slaves that received relay log files to the latest):
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info] The oldest binary log file/position on all slaves is MHA-LHR-Master1-ip131-bin.000011:234
Sat Aug 8 11:01:30 2020 - [info] Oldest slaves:
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 3.3: Determining New Master Phase..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] Searching new master from slaves..
Sat Aug 8 11:01:30 2020 - [info] Candidate masters from the configuration file:
Sat Aug 8 11:01:30 2020 - [info] 192.168.68.132(192.168.68.132:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:01:30 2020 - [info] GTID ON
Sat Aug 8 11:01:30 2020 - [info] Replicating from 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:01:30 2020 - [info] Primary candidate for the new Master (candidate_master is set)
Sat Aug 8 11:01:30 2020 - [info] Non-candidate masters:
Sat Aug 8 11:01:30 2020 - [info] Searching from candidate_master slaves which have received the latest relay log events..
Sat Aug 8 11:01:30 2020 - [info] New master is 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:01:30 2020 - [info] Starting master failover..
Sat Aug 8 11:01:30 2020 - [info]
From:
192.168.68.131(192.168.68.131:3306) (current master)
+--192.168.68.132(192.168.68.132:3306)
+--192.168.68.133(192.168.68.133:3306)
To:
192.168.68.132(192.168.68.132:3306) (new master)
+--192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 3.3: New Master Recovery Phase..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] Waiting all logs to be applied..
Sat Aug 8 11:01:30 2020 - [info] done.
Sat Aug 8 11:01:30 2020 - [info] Getting new master‘s binlog name and position..
Sat Aug 8 11:01:30 2020 - [info] MHA-LHR-Slave1-ip132-bin.000008:234
Sat Aug 8 11:01:30 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=‘192.168.68.132‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘repl‘, MASTER_PASSWORD=‘xxx‘;
Sat Aug 8 11:01:30 2020 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: MHA-LHR-Slave1-ip132-bin.000008, 234, c8ca4f1d-aec3-11ea-942b-0242c0a84483:1-11,
d24a77d1-aec3-11ea-9399-0242c0a84484:1-3
Sat Aug 8 11:01:30 2020 - [info] Executing master IP activate script:
Sat Aug 8 11:01:30 2020 - [info] /usr/local/mha/scripts/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.68.131 --orig_master_ip=192.168.68.131 --orig_master_port=3306 --new_master_host=192.168.68.132 --new_master_ip=192.168.68.132 --new_master_port=3306 --new_master_user=‘mha‘ --new_master_password=xxx
Unknown option: new_master_user
Unknown option: new_master_password
IN SCRIPT TEST====/sbin/ip addr del 192.168.68.135/24 dev eth0==/sbin/ifconfig eth0:1 192.168.68.135/24===
Enabling the VIP - 192.168.68.135/24 on the new master - 192.168.68.132
Sat Aug 8 11:01:30 2020 - [info] OK.
Sat Aug 8 11:01:30 2020 - [info] ** Finished master recovery successfully.
Sat Aug 8 11:01:30 2020 - [info] * Phase 3: Master Recovery Phase completed.
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 4: Slaves Recovery Phase..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] * Phase 4.1: Starting Slaves in parallel..
Sat Aug 8 11:01:30 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] -- Slave recovery on host 192.168.68.133(192.168.68.133:3306) started, pid: 474. Check tmp log /usr/local/mha/192.168.68.133_3306_20200808110127.log if it takes time..
Sat Aug 8 11:01:32 2020 - [info]
Sat Aug 8 11:01:32 2020 - [info] Log messages from 192.168.68.133 ...
Sat Aug 8 11:01:32 2020 - [info]
Sat Aug 8 11:01:30 2020 - [info] Resetting slave 192.168.68.133(192.168.68.133:3306) and starting replication from the new master 192.168.68.132(192.168.68.132:3306)..
Sat Aug 8 11:01:30 2020 - [info] Executed CHANGE MASTER.
Sat Aug 8 11:01:31 2020 - [info] Slave started.
Sat Aug 8 11:01:31 2020 - [info] gtid_wait(c8ca4f1d-aec3-11ea-942b-0242c0a84483:1-11,
d24a77d1-aec3-11ea-9399-0242c0a84484:1-3) completed on 192.168.68.133(192.168.68.133:3306). Executed 0 events.
Sat Aug 8 11:01:32 2020 - [info] End of log messages from 192.168.68.133.
Sat Aug 8 11:01:32 2020 - [info] -- Slave on host 192.168.68.133(192.168.68.133:3306) started.
Sat Aug 8 11:01:32 2020 - [info] All new slave servers recovered successfully.
Sat Aug 8 11:01:32 2020 - [info]
Sat Aug 8 11:01:32 2020 - [info] * Phase 5: New master cleanup phase..
Sat Aug 8 11:01:32 2020 - [info]
Sat Aug 8 11:01:32 2020 - [info] Resetting slave info on the new master..
Sat Aug 8 11:01:32 2020 - [info] 192.168.68.132: Resetting slave info succeeded.
Sat Aug 8 11:01:32 2020 - [info] Master failover to 192.168.68.132(192.168.68.132:3306) completed successfully.
Sat Aug 8 11:01:32 2020 - [info]
----- Failover Report -----
mha: MySQL Master failover 192.168.68.131(192.168.68.131:3306) to 192.168.68.132(192.168.68.132:3306) succeeded
Master 192.168.68.131(192.168.68.131:3306) is down!
Check MHA Manager logs at MHA-LHR-Monitor-ip134:/usr/local/mha/manager_running.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.68.131(192.168.68.131:3306)
Selected 192.168.68.132(192.168.68.132:3306) as a new master.
192.168.68.132(192.168.68.132:3306): OK: Applying all logs succeeded.
192.168.68.132(192.168.68.132:3306): OK: Activated master IP address.
192.168.68.133(192.168.68.133:3306): OK: Slave started, replicating from 192.168.68.132(192.168.68.132:3306)
192.168.68.132(192.168.68.132:3306): Resetting slave info succeeded.
Master failover to 192.168.68.132(192.168.68.132:3306) completed successfully.
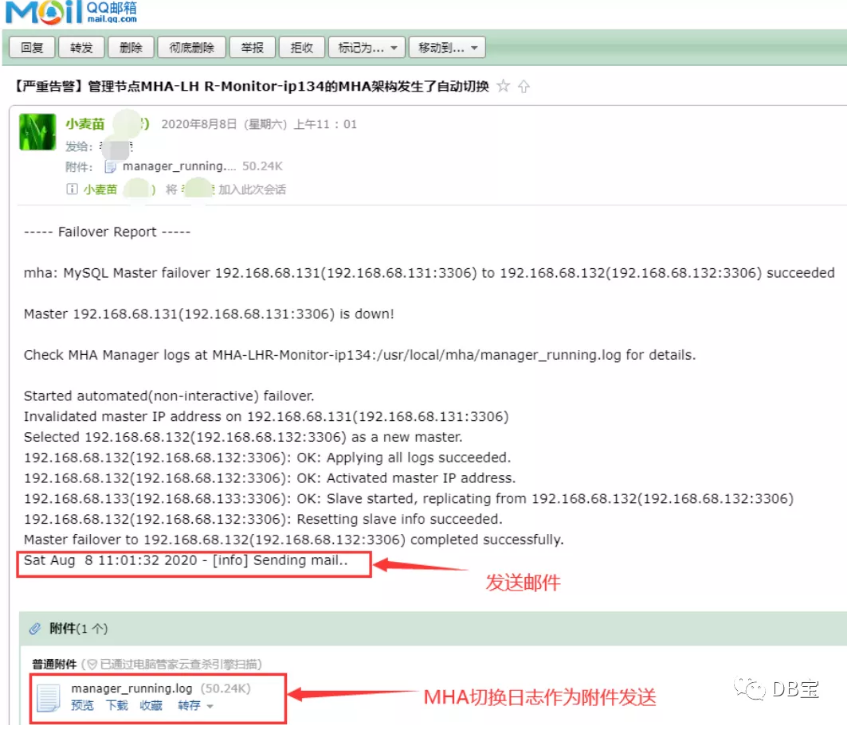
Sat Aug 8 11:01:32 2020 - [info] Sending mail..
⑤ 同时,邮件收到告警
注意:
1、首先确保你的134环境可以上外网
[root@MHA-LHR-Monitor-ip134 /]# ping 8.8.8.8 PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data. 64 bytes from 8.8.8.8: icmp_seq=1 ttl=127 time=109 ms 64 bytes from 8.8.8.8: icmp_seq=2 ttl=127 time=152 ms 64 bytes from 8.8.8.8: icmp_seq=3 ttl=127 time=132 ms ^C --- 8.8.8.8 ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2004ms rtt min/avg/max/mdev = 109.295/131.671/152.728/17.758 ms [root@MHA-LHR-Monitor-ip134 /]#2、如果你想修改邮件的收件人,那么需要修改134管理节点的/usr/local/bin/send_report文件,将其中的lhrbest@qq.com修改为收件人的邮箱地址即可。文件/usr/local/bin/send_report内容如下所示:
[root@MHA-LHR-Monitor-ip134 /]# cat /usr/local/bin/send_report #!/bin/bash start_num=+`awk ‘/Failover Report/{print NR}‘ /usr/local/mha/manager_running.log | tail -n 1` tail -n $start_num /usr/local/mha/manager_running.log | mail -s ‘【严重告警】‘管理节点`hostname -s`‘的MHA架构发生了自动切换‘ -a ‘/usr/local/mha/manager_running.log‘ lhrbest@qq.com [root@MHA-LHR-Monitor-ip134 /]#
# 启动131
docker start MHA-LHR-Master1-ip131
# 在134的日志文件中找到恢复的语句
grep "All other slaves should start replication from here" /usr/local/mha/manager_running.log
# 在131上执行恢复
CHANGE MASTER TO MASTER_HOST=‘192.168.68.132‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘repl‘, MASTER_PASSWORD=‘lhr‘;
start slave;
show slave status;
# 在134上检查
masterha_check_repl --conf=/etc/mha/mha.cnf
执行过程:
[root@MHA-LHR-Monitor-ip134 /]# grep "All other slaves should start replication from here" /usr/local/mha/manager_running.log
Mon Jun 15 14:16:31 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=‘192.168.68.132‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘repl‘, MASTER_PASSWORD=‘xxx‘;
Sat Aug 8 11:01:30 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=‘192.168.68.132‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘repl‘, MASTER_PASSWORD=‘xxx‘;
[root@MHA-LHR-Monitor-ip134 /]#
[root@MHA-LHR-Monitor-ip134 /]# masterha_check_repl --conf=/etc/mha/mha.cnf
Sat Aug 8 11:23:30 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 8 11:23:30 2020 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:23:30 2020 - [info] Reading server configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:23:30 2020 - [info] MHA::MasterMonitor version 0.58.
Sat Aug 8 11:23:32 2020 - [info] GTID failover mode = 1
Sat Aug 8 11:23:32 2020 - [info] Dead Servers:
Sat Aug 8 11:23:32 2020 - [info] Alive Servers:
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:23:32 2020 - [info] Alive Slaves:
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.131(192.168.68.131:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:23:32 2020 - [info] GTID ON
Sat Aug 8 11:23:32 2020 - [info] Replicating from 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:23:32 2020 - [info] GTID ON
Sat Aug 8 11:23:32 2020 - [info] Replicating from 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] Current Alive Master: 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] Checking slave configurations..
Sat Aug 8 11:23:32 2020 - [info] read_only=1 is not set on slave 192.168.68.131(192.168.68.131:3306).
Sat Aug 8 11:23:32 2020 - [info] read_only=1 is not set on slave 192.168.68.133(192.168.68.133:3306).
Sat Aug 8 11:23:32 2020 - [info] Checking replication filtering settings..
Sat Aug 8 11:23:32 2020 - [info] binlog_do_db= , binlog_ignore_db= information_schema,mysql,performance_schema,sys
Sat Aug 8 11:23:32 2020 - [info] Replication filtering check ok.
Sat Aug 8 11:23:32 2020 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Sat Aug 8 11:23:32 2020 - [info] Checking SSH publickey authentication settings on the current master..
Sat Aug 8 11:23:32 2020 - [info] HealthCheck: SSH to 192.168.68.132 is reachable.
Sat Aug 8 11:23:32 2020 - [info]
192.168.68.132(192.168.68.132:3306) (current master)
+--192.168.68.131(192.168.68.131:3306)
+--192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:23:32 2020 - [info] Checking replication health on 192.168.68.131..
Sat Aug 8 11:23:32 2020 - [info] ok.
Sat Aug 8 11:23:32 2020 - [info] Checking replication health on 192.168.68.133..
Sat Aug 8 11:23:32 2020 - [info] ok.
Sat Aug 8 11:23:32 2020 - [info] Checking master_ip_failover_script status:
Sat Aug 8 11:23:32 2020 - [info] /usr/local/mha/scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.68.132 --orig_master_ip=192.168.68.132 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ip addr del 192.168.68.135/24 dev eth0==/sbin/ifconfig eth0:1 192.168.68.135/24===
Checking the Status of the script.. OK
Sat Aug 8 11:23:32 2020 - [info] OK.
Sat Aug 8 11:23:32 2020 - [warning] shutdown_script is not defined.
Sat Aug 8 11:23:32 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
类似Oracle DG中的switchover。在该场景下,主库并没有宕机。在主库活着的时候,将主库降级为备库,将备用主库提升为主库,并且重新配置主从关系。此时,MHA进程不能启动。
masterha_master_switch --conf=/etc/mha/mha.cnf --master_state=alive --orig_master_is_new_slave --running_updates_limit=10000 --interactive=0 --new_master_host=192.168.68.131 --new_master_port=3306
参数解释:
--interactive 为是否交互,即你要输入yes或no
--running_updates_limit 如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。故障切换时,候选master如果有延迟的话,mha切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover时relay日志的大小决定
--orig_master_is_new_slave 将原来的主降低为从并重新加入主从关系
--new_master_host 指定新的主库的主机名,建议写IP地址
--new_master_port 指定新的主库上mysql服务的端口
在切换完成后,主库为131,备库为132和133,VIP自动切换到131,即回到了最初的MHA状态。
[root@MHA-LHR-Monitor-ip134 /]# masterha_check_repl --conf=/etc/mha/mha.cnf
Sat Aug 8 11:23:30 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 8 11:23:30 2020 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:23:30 2020 - [info] Reading server configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:23:30 2020 - [info] MHA::MasterMonitor version 0.58.
Sat Aug 8 11:23:32 2020 - [info] GTID failover mode = 1
Sat Aug 8 11:23:32 2020 - [info] Dead Servers:
Sat Aug 8 11:23:32 2020 - [info] Alive Servers:
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.131(192.168.68.131:3306)
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:23:32 2020 - [info] Alive Slaves:
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.131(192.168.68.131:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:23:32 2020 - [info] GTID ON
Sat Aug 8 11:23:32 2020 - [info] Replicating from 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:23:32 2020 - [info] GTID ON
Sat Aug 8 11:23:32 2020 - [info] Replicating from 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] Current Alive Master: 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:23:32 2020 - [info] Checking slave configurations..
Sat Aug 8 11:23:32 2020 - [info] read_only=1 is not set on slave 192.168.68.131(192.168.68.131:3306).
Sat Aug 8 11:23:32 2020 - [info] read_only=1 is not set on slave 192.168.68.133(192.168.68.133:3306).
Sat Aug 8 11:23:32 2020 - [info] Checking replication filtering settings..
Sat Aug 8 11:23:32 2020 - [info] binlog_do_db= , binlog_ignore_db= information_schema,mysql,performance_schema,sys
Sat Aug 8 11:23:32 2020 - [info] Replication filtering check ok.
Sat Aug 8 11:23:32 2020 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Sat Aug 8 11:23:32 2020 - [info] Checking SSH publickey authentication settings on the current master..
Sat Aug 8 11:23:32 2020 - [info] HealthCheck: SSH to 192.168.68.132 is reachable.
Sat Aug 8 11:23:32 2020 - [info]
192.168.68.132(192.168.68.132:3306) (current master)
+--192.168.68.131(192.168.68.131:3306)
+--192.168.68.133(192.168.68.133:3306)
Sat Aug 8 11:23:32 2020 - [info] Checking replication health on 192.168.68.131..
Sat Aug 8 11:23:32 2020 - [info] ok.
Sat Aug 8 11:23:32 2020 - [info] Checking replication health on 192.168.68.133..
Sat Aug 8 11:23:32 2020 - [info] ok.
Sat Aug 8 11:23:32 2020 - [info] Checking master_ip_failover_script status:
Sat Aug 8 11:23:32 2020 - [info] /usr/local/mha/scripts/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.68.132 --orig_master_ip=192.168.68.132 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ip addr del 192.168.68.135/24 dev eth0==/sbin/ifconfig eth0:1 192.168.68.135/24===
Checking the Status of the script.. OK
Sat Aug 8 11:23:32 2020 - [info] OK.
Sat Aug 8 11:23:32 2020 - [warning] shutdown_script is not defined.
Sat Aug 8 11:23:32 2020 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
[root@MHA-LHR-Monitor-ip134 /]# masterha_master_switch --conf=/etc/mha/mha.cnf --master_state=alive > --orig_master_is_new_slave --running_updates_limit=10000 --interactive=0 > --new_master_host=192.168.68.131 --new_master_port=3306
Sat Aug 8 11:26:36 2020 - [info] MHA::MasterRotate version 0.58.
Sat Aug 8 11:26:36 2020 - [info] Starting online master switch..
Sat Aug 8 11:26:36 2020 - [info]
Sat Aug 8 11:26:36 2020 - [info] * Phase 1: Configuration Check Phase..
Sat Aug 8 11:26:36 2020 - [info]
Sat Aug 8 11:26:36 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Sat Aug 8 11:26:36 2020 - [info] Reading application default configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:26:36 2020 - [info] Reading server configuration from /etc/mha/mha.cnf..
Sat Aug 8 11:26:37 2020 - [info] GTID failover mode = 1
Sat Aug 8 11:26:37 2020 - [info] Current Alive Master: 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:26:37 2020 - [info] Alive Slaves:
Sat Aug 8 11:26:37 2020 - [info] 192.168.68.131(192.168.68.131:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:26:37 2020 - [info] GTID ON
Sat Aug 8 11:26:37 2020 - [info] Replicating from 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:26:37 2020 - [info] 192.168.68.133(192.168.68.133:3306) Version=5.7.30-log (oldest major version between slaves) log-bin:enabled
Sat Aug 8 11:26:37 2020 - [info] GTID ON
Sat Aug 8 11:26:37 2020 - [info] Replicating from 192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:26:37 2020 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..
Sat Aug 8 11:26:37 2020 - [info] ok.
Sat Aug 8 11:26:37 2020 - [info] Checking MHA is not monitoring or doing failover..
Sat Aug 8 11:26:37 2020 - [info] Checking replication health on 192.168.68.131..
Sat Aug 8 11:26:37 2020 - [info] ok.
Sat Aug 8 11:26:37 2020 - [info] Checking replication health on 192.168.68.133..
Sat Aug 8 11:26:37 2020 - [info] ok.
Sat Aug 8 11:26:37 2020 - [info] 192.168.68.131 can be new master.
Sat Aug 8 11:26:37 2020 - [info]
From:
192.168.68.132(192.168.68.132:3306) (current master)
+--192.168.68.131(192.168.68.131:3306)
+--192.168.68.133(192.168.68.133:3306)
To:
192.168.68.131(192.168.68.131:3306) (new master)
+--192.168.68.133(192.168.68.133:3306)
+--192.168.68.132(192.168.68.132:3306)
Sat Aug 8 11:26:37 2020 - [info] Checking whether 192.168.68.131(192.168.68.131:3306) is ok for the new master..
Sat Aug 8 11:26:37 2020 - [info] ok.
Sat Aug 8 11:26:37 2020 - [info] 192.168.68.132(192.168.68.132:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host.
Sat Aug 8 11:26:37 2020 - [info] 192.168.68.132(192.168.68.132:3306): Resetting slave pointing to the dummy host.
Sat Aug 8 11:26:37 2020 - [info] ** Phase 1: Configuration Check Phase completed.
Sat Aug 8 11:26:37 2020 - [info]
Sat Aug 8 11:26:37 2020 - [info] * Phase 2: Rejecting updates Phase..
Sat Aug 8 11:26:37 2020 - [info]
Sat Aug 8 11:26:37 2020 - [info] Executing master ip online change script to disable write on the current master:
Sat Aug 8 11:26:37 2020 - [info] /usr/local/mha/scripts/master_ip_online_change --command=stop --orig_master_host=192.168.68.132 --orig_master_ip=192.168.68.132 --orig_master_port=3306 --orig_master_user=‘mha‘ --new_master_host=192.168.68.131 --new_master_ip=192.168.68.131 --new_master_port=3306 --new_master_user=‘mha‘ --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_master_password=xxx
Sat Aug 8 11:26:37 2020 758267 Set read_only on the new master.. ok.
Sat Aug 8 11:26:37 2020 763087 Waiting all running 2 threads are disconnected.. (max 1500 milliseconds)
{‘Time‘ => ‘1507‘,‘db‘ => undef,‘Id‘ => ‘14‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.133:60218‘}
{‘Time‘ => ‘227‘,‘db‘ => undef,‘Id‘ => ‘18‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.131:60292‘}
Sat Aug 8 11:26:38 2020 267483 Waiting all running 2 threads are disconnected.. (max 1000 milliseconds)
{‘Time‘ => ‘1508‘,‘db‘ => undef,‘Id‘ => ‘14‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.133:60218‘}
{‘Time‘ => ‘228‘,‘db‘ => undef,‘Id‘ => ‘18‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.131:60292‘}
Sat Aug 8 11:26:38 2020 771131 Waiting all running 2 threads are disconnected.. (max 500 milliseconds)
{‘Time‘ => ‘1508‘,‘db‘ => undef,‘Id‘ => ‘14‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.133:60218‘}
{‘Time‘ => ‘228‘,‘db‘ => undef,‘Id‘ => ‘18‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.131:60292‘}
Sat Aug 8 11:26:39 2020 274787 Set read_only=1 on the orig master.. ok.
Sat Aug 8 11:26:39 2020 276192 Waiting all running 2 queries are disconnected.. (max 500 milliseconds)
{‘Time‘ => ‘1509‘,‘db‘ => undef,‘Id‘ => ‘14‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.133:60218‘}
{‘Time‘ => ‘229‘,‘db‘ => undef,‘Id‘ => ‘18‘,‘User‘ => ‘repl‘,‘State‘ => ‘Master has sent all binlog to slave; waiting for more updates‘,‘Command‘ => ‘Binlog Dump GTID‘,‘Info‘ => undef,‘Host‘ => ‘192.168.68.131:60292‘}
Sat Aug 8 11:26:39 2020 778101 Killing all application threads..
Sat Aug 8 11:26:39 2020 778804 done.
Disabling the VIP an old master: 192.168.68.132
Warning: Executing wildcard deletion to stay compatible with old scripts.
Explicitly specify the prefix length (192.168.68.135/32) to avoid this warning.
This special behaviour is likely to disappear in further releases,
fix your scripts!
Sat Aug 8 11:26:39 2020 - [info] ok.
Sat Aug 8 11:26:39 2020 - [info] Locking all tables on the orig master to reject updates from everybody (including root):
Sat Aug 8 11:26:39 2020 - [info] Executing FLUSH TABLES WITH READ LOCK..
Sat Aug 8 11:26:39 2020 - [info] ok.
Sat Aug 8 11:26:39 2020 - [info] Orig master binlog:pos is MHA-LHR-Slave1-ip132-bin.000008:234.
Sat Aug 8 11:26:39 2020 - [info] Waiting to execute all relay logs on 192.168.68.131(192.168.68.131:3306)..
Sat Aug 8 11:26:39 2020 - [info] master_pos_wait(MHA-LHR-Slave1-ip132-bin.000008:234) completed on 192.168.68.131(192.168.68.131:3306). Executed 0 events.
Sat Aug 8 11:26:39 2020 - [info] done.
Sat Aug 8 11:26:39 2020 - [info] Getting new master‘s binlog name and position..
Sat Aug 8 11:26:39 2020 - [info] MHA-LHR-Master1-ip131-bin.000013:234
Sat Aug 8 11:26:39 2020 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST=‘192.168.68.131‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘repl‘, MASTER_PASSWORD=‘xxx‘;
Sat Aug 8 11:26:39 2020 - [info] Executing master ip online change script to allow write on the new master:
Sat Aug 8 11:26:39 2020 - [info] /usr/local/mha/scripts/master_ip_online_change --command=start --orig_master_host=192.168.68.132 --orig_master_ip=192.168.68.132 --orig_master_port=3306 --orig_master_user=‘mha‘ --new_master_host=192.168.68.131 --new_master_ip=192.168.68.131 --new_master_port=3306 --new_master_user=‘mha‘ --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_master_password=xxx
Sat Aug 8 11:26:40 2020 027564 Set read_only=0 on the new master.
Enabling the VIP 192.168.68.135 on the new master: 192.168.68.131
Sat Aug 8 11:26:42 2020 - [info] ok.
Sat Aug 8 11:26:42 2020 - [info]
Sat Aug 8 11:26:42 2020 - [info] * Switching slaves in parallel..
Sat Aug 8 11:26:42 2020 - [info]
Sat Aug 8 11:26:42 2020 - [info] -- Slave switch on host 192.168.68.133(192.168.68.133:3306) started, pid: 640
Sat Aug 8 11:26:42 2020 - [info]
Sat Aug 8 11:26:44 2020 - [info] Log messages from 192.168.68.133 ...
Sat Aug 8 11:26:44 2020 - [info]
Sat Aug 8 11:26:42 2020 - [info] Waiting to execute all relay logs on 192.168.68.133(192.168.68.133:3306)..
Sat Aug 8 11:26:42 2020 - [info] master_pos_wait(MHA-LHR-Slave1-ip132-bin.000008:234) completed on 192.168.68.133(192.168.68.133:3306). Executed 0 events.
Sat Aug 8 11:26:42 2020 - [info] done.
Sat Aug 8 11:26:42 2020 - [info] Resetting slave 192.168.68.133(192.168.68.133:3306) and starting replication from the new master 192.168.68.131(192.168.68.131:3306)..
Sat Aug 8 11:26:42 2020 - [info] Executed CHANGE MASTER.
Sat Aug 8 11:26:43 2020 - [info] Slave started.
Sat Aug 8 11:26:44 2020 - [info] End of log messages from 192.168.68.133 ...
Sat Aug 8 11:26:44 2020 - [info]
Sat Aug 8 11:26:44 2020 - [info] -- Slave switch on host 192.168.68.133(192.168.68.133:3306) succeeded.
Sat Aug 8 11:26:44 2020 - [info] Unlocking all tables on the orig master:
Sat Aug 8 11:26:44 2020 - [info] Executing UNLOCK TABLES..
Sat Aug 8 11:26:44 2020 - [info] ok.
Sat Aug 8 11:26:44 2020 - [info] Starting orig master as a new slave..
Sat Aug 8 11:26:44 2020 - [info] Resetting slave 192.168.68.132(192.168.68.132:3306) and starting replication from the new master 192.168.68.131(192.168.68.131:3306)..
Sat Aug 8 11:26:44 2020 - [info] Executed CHANGE MASTER.
Sat Aug 8 11:26:44 2020 - [info] Slave started.
Sat Aug 8 11:26:44 2020 - [info] All new slave servers switched successfully.
Sat Aug 8 11:26:44 2020 - [info]
Sat Aug 8 11:26:44 2020 - [info] * Phase 5: New master cleanup phase..
Sat Aug 8 11:26:44 2020 - [info]
Sat Aug 8 11:26:44 2020 - [info] 192.168.68.131: Resetting slave info succeeded.
Sat Aug 8 11:26:44 2020 - [info] Switching master to 192.168.68.131(192.168.68.131:3306) completed successfully.
测试场景一测试的是,在主库故障后,MHA自动执行故障转移动作。
测试场景二测试的是,在主库故障后,MHA进程未启动的情况下,我们手动来切换。这种情况为MySQL主从关系中主库因为故障宕机了,但是MHA Master监控并没有开启,这个时候就需要手动来failover了。该情况下,日志打印输出和自动failover是没有什么区别的。需要注意的是,如果主库未宕机,那么不能手动执行故障切换,会报错的。
# 关闭主库
docker stop MHA-LHR-Master1-ip131
# 在134上执行手动切换
masterha_master_switch --conf=/etc/mha/mha.cnf --master_state=dead --ignore_last_failover --interactive=0 --dead_master_host=192.168.68.131 --dead_master_port=3306 --new_master_host=192.168.68.132 -―new_master_port=3306
接下来,宕掉的主库需要手动恢复,这里不再详细演示。需要注意的是,手动切换也会发送告警邮件。
# 安装mysql-utilities包,依赖于Python2.7,版本需要对应,否则报错
rpm -e mysql-connector-python-2.1.8-1.el7.x86_64 --nodeps
#centos 7
rpm -Uvh http://repo.mysql.com/yum/mysql-connectors-community/el/7/x86_64/mysql-connector-python-1.1.6-1.el7.noarch.rpm
#centos 6
rpm -Uvh http://repo.mysql.com/yum/mysql-connectors-community/el/6/x86_64/mysql-connector-python-1.1.6-1.el6.noarch.rpm
yum install -y mysql-utilities
我的镜像环境已安装配置好了,直接执行即可,执行结果:
[root@MHA-LHR-Monitor-ip134 /]# mysqlrplshow --master=root:lhr@192.168.68.131:3306 --discover-slaves-login=root:lhr --verbose
# master on 192.168.68.131: ... connected.
# Finding slaves for master: 192.168.68.131:3306
# Replication Topology Graph
192.168.68.131:3306 (MASTER)
|
+--- 192.168.68.132:3306 [IO: Yes, SQL: Yes] - (SLAVE)
|
+--- 192.168.68.133:3306 [IO: Yes, SQL: Yes] - (SLAVE)
[root@MHA-LHR-Monitor-ip134 /]# mysqlrplcheck --master=root:lhr@192.168.68.131:3306 --slave=root:lhr@192.168.68.132:3306 -v
# master on 192.168.68.131: ... connected.
# slave on 192.168.68.132: ... connected.
Test Description Status
---------------------------------------------------------------------------
Checking for binary logging on master [pass]
Are there binlog exceptions? [WARN]
+---------+--------+--------------------------------------------------+
| server | do_db | ignore_db |
+---------+--------+--------------------------------------------------+
| master | | mysql,information_schema,performance_schema,sys |
| slave | | information_schema,performance_schema,mysql,sys |
+---------+--------+--------------------------------------------------+
Replication user exists? [pass]
Checking server_id values [pass]
master id = 573306131
slave id = 573306132
Checking server_uuid values [pass]
master uuid = c8ca4f1d-aec3-11ea-942b-0242c0a84483
slave uuid = d24a77d1-aec3-11ea-9399-0242c0a84484
Is slave connected to master? [pass]
Check master information file [WARN]
Cannot read master information file from a remote machine.
Checking InnoDB compatibility [pass]
Checking storage engines compatibility [pass]
Checking lower_case_table_names settings [pass]
Master lower_case_table_names: 0
Slave lower_case_table_names: 0
Checking slave delay (seconds behind master) [pass]
# ...done.
有关MHA的常见测试就结束了,更详细的内容请咨询小麦苗的MySQL DBA课程。
About Me
● 本文作者:小麦苗,部分内容整理自网络,若有侵权请联系小麦苗删除
● 本文在个人微 信公众号(DB宝)上有同步更新
● QQ群号: 230161599 、618766405,微信群私聊
● 个人QQ号(646634621),微 信号(db_bao),注明添加缘由
● 于 2021年2月 在西安完成
● 最新修改时间:2021年2月
● 版权所有,欢迎分享本文,转载请保留出处
●小麦苗的微店: https://weidian.com/?userid=793741433
●小麦苗出版的数据库类丛书: http://blog.itpub.net/26736162/viewspace-2142121/
●小麦苗OCP、OCM、高可用、DBA学习班(Oracle、MySQL、NoSQL): http://blog.itpub.net/26736162/viewspace-2148098/
●数据库笔试面试题库及解答: https://mp.weixin.qq.com/s/Vm5PqNcDcITkOr9cQg6T7w
使用微信客户端扫描下面的二维码来关注小麦苗的微信公众号(DB宝)及QQ群(DBA宝典)、添加小麦苗微信, 学习最实用的数据库技术。
标签:user 出版 using download doc 官方 tail acl rpo
原文地址:https://www.cnblogs.com/lhrbest/p/14414442.html