标签:als and func else 标准 heap contain opp img
最近比较闲,学习golang。自己写了一个json 生成器,打算写一个json解析器,一时没啥思路。去github上查找了一下go 的json工具,发现了jsonparser这个工具。于是搞到自己的项目中,把玩调试了一番,简单梳理一下其内部是如何解析json的。
版本:github.com/buger/jsonparser v1.1.1
根据README.md上面的介绍,他比json标准库10倍,并且在解析的过程中,不分配内存。我们先来运行一个例子玩玩。
package main
import (
"fmt"
"github.com/buger/jsonparser"
)
func main() {
data := []byte(`{
"person": {
"name": {
"first": "Leonid",
"last": "Bugaev",
"fullName": "Leonid Bugaev"
},
"github": {
"handle": "buger",
"followers": 109
},
"avatars": [
{ "url": "https://avatars1.githubusercontent.com/u/14009?v=3&s=460", "type": "thumbnail" }
]
},
"company": {
"name": "Acme"
}
}`)
// You can specify key path by providing arguments to Get function
v,dataType,offset,err:=jsonparser.Get(data, "person", "name", "first")
if err!=nil{
panic(err)
}
fmt.Println(string(v))
fmt.Println(dataType.String())
fmt.Println(offset)fmt.Println("-------------------------")
//// There is `GetInt` and `GetBoolean` helpers if you exactly know key data type
//jsonparser.GetInt(data, "person", "github", "followers")
//
//// When you try to get object, it will return you []byte slice pointer to data containing it
//// In `company` it will be `{"name": "Acme"}`
v1,dataType1,offset1,err1:=jsonparser.Get(data, "person","github")
if err1!=nil{
panic(err1)
}
fmt.Println(string(v1))
fmt.Println(dataType1.String())
fmt.Println(offset1)
}
//输出的结果是:
//Leonid
//string
//50
//-------------------------
//{
// "handle": "buger",
// "followers": 109
// }
//object
//179
选定一个入口,

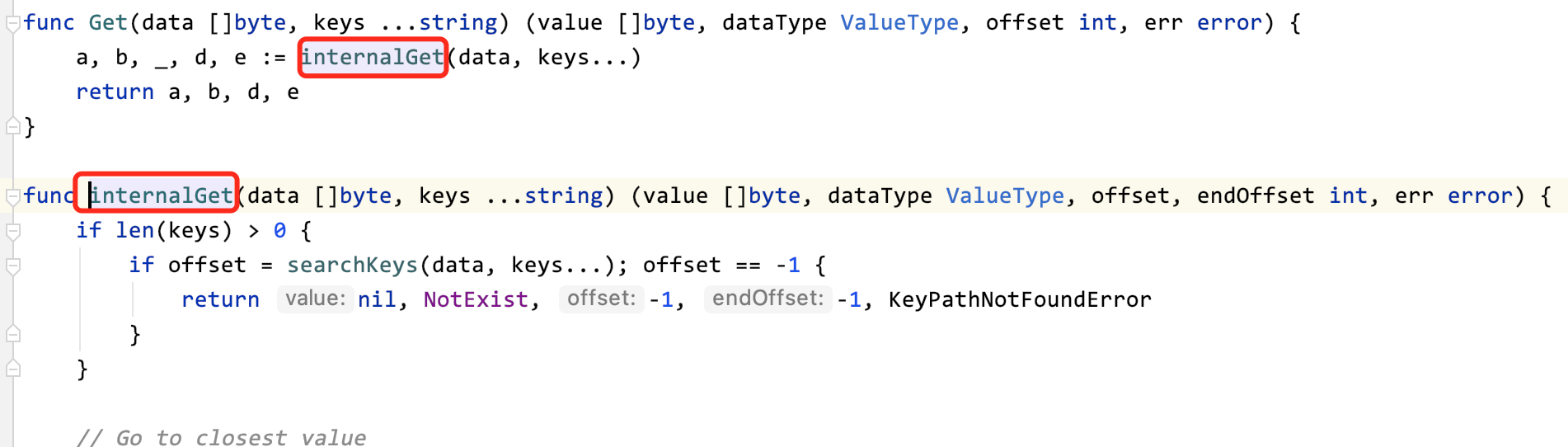
从Get方法进去,可以走到internalGet-->searchKeys
进到searchKeys中,看代码发现此时它会一个byte一个byte的遍历 data,然后判断每个byte的值是否为 " { [ : 等符号,并且在遍历data的时候,会先创建变量来记录 level (这个level,我的理解就是记录 {{ }} 像这样的括号的层级的),然后在匹配到 { }
的时候进行level操作。但是它缺少了空格的匹配,这样会导致空循环。
func searchKeys(data []byte, keys ...string) int {
keyLevel := 0 //记录key的层级
level := 0 //记录 { 的层级
i := 0
ln := len(data)
lk := len(keys) //key 的层级,如上的例子就是 person -> name -> first 这样一层一层的查找值的
lastMatched := true
if lk == 0 {
return 0
}
var stackbuf [unescapeStackBufSize]byte // stack-allocated array for allocation-free unescaping of small strings
for i < ln {
switch data[i] {
case ‘"‘:
i++
keyBegin := i
...
case ‘{‘:
// in case parent key is matched then only we will increase the level otherwise can directly
// can move to the end of this block
if !lastMatched {
end := blockEnd(data[i:], ‘{‘, ‘}‘)
if end == -1 {
return -1
}
i += end - 1
} else {
level++
}
case ‘}‘:
level--
if level == keyLevel {
keyLevel--
}
case ‘[‘:
// If we want to get array element by index
if keyLevel == level && keys[level][0] == ‘[‘ {
var keyLen = len(keys[level])
if keyLen < 3 || keys[level][0] != ‘[‘ || keys[level][keyLen-1] != ‘]‘ {
return -1
....
} else {
// Do not search for keys inside arrays
if arraySkip := blockEnd(data[i:], ‘[‘, ‘]‘); arraySkip == -1 {
return -1
} else {
i += arraySkip - 1
}
}
case ‘:‘: // If encountered, JSON data is malformed
return -1
}
i++
}
return -1
}
继续看匹配到 { } 时,只是进行level的记录操作,没有其他动作。
case ‘{‘:
// in case parent key is matched then only we will increase the level otherwise can directly
// can move to the end of this block
if !lastMatched { //如果是最后的一个
end := blockEnd(data[i:], ‘{‘, ‘}‘)
if end == -1 {
return -1
}
i += end - 1
} else {
level++
}
case ‘}‘:
level--
if level == keyLevel {
keyLevel--
}
当匹配到 " 时,说明已经遍历到key或者value了,
case ‘"‘:
i++
keyBegin := i //记录data的index,这里是截取key的起始位置
strEnd, keyEscaped := stringEnd(data[i:]) // stringEnd方法来返回字符串结束的位置,见后续内容
if strEnd == -1 {
return -1
}
i += strEnd // 更新 i
keyEnd := i - 1 //得到key的结束位置
valueOffset := nextToken(data[i:]) // nextToken 就是空格,换行符等过滤 见后续内容
if valueOffset == -1 {
return -1
}
i += valueOffset //更新 i
// if string is a key
if data[i] == ‘:‘ { //接下来的是 : 表示此时的string 为key
if level < 1 {
return -1
}
key := data[keyBegin:keyEnd] //截取data,得到key的值
// for unescape: if there are no escape sequences, this is cheap; if there are, it is a
// bit more expensive, but causes no allocations unless len(key) > unescapeStackBufSize
var keyUnesc []byte
if !keyEscaped {
keyUnesc = key //将key 赋值给 keyUnesc
} else if ku, err := Unescape(key, stackbuf[:]); err != nil {
return -1
} else {
keyUnesc = ku
}
if level <= len(keys) { //level的层级还在keys 内部时
if equalStr(&keyUnesc, keys[level-1]) { //比较 keyUnesc 是否和keys中按顺序的key相等
lastMatched = true //标记此次匹配成功,
// if key level match
if keyLevel == level-1 { //判断key的层级和level的层级是否正常
keyLevel++ //正常则表示可以匹配第准备去匹配 keys 的下一个了
// If we found all keys in path
if keyLevel == lk { //如果相等,表示已经找到了所有的keys 了
return i + 1
}
}
} else {
lastMatched = false
}
} else {
return -1
}
} else {
i--
}
继续查看上面的 stringEnd 方法
func stringEnd(data []byte) (int, bool) { //接受传递过来的data
escaped := false
for i, c := range data {
if c == ‘"‘ { //此时 i 的位置为 "xxx" 的末尾
if !escaped { //
return i + 1, false //在本例子中,从此处返回
} else {
j := i - 1 // 此时 j 的位置为 "xxx 的末尾,相当于去掉了 "
for {
if j < 0 || data[j] != ‘\\‘ {
return i + 1, true // even number of backslashes
}
j--
if j < 0 || data[j] != ‘\\‘ {
break // odd number of backslashes
}
j--
}
}
} else if c == ‘\\‘ {
escaped = true
}
}
return -1, escaped
}
跳过 ‘ ‘, ‘\n‘, ‘\r‘, ‘\t‘ 这些byte
// Find position of next character which is not whitespace
func nextToken(data []byte) int {
for i, c := range data {
switch c {
case ‘ ‘, ‘\n‘, ‘\r‘, ‘\t‘:
continue
default:
return i
}
}
return -1
}
当查到了符合层级的key后就回到了internalGet
func internalGet(data []byte, keys ...string) (value []byte, dataType ValueType, offset, endOffset int, err error) {
if len(keys) > 0 {
if offset = searchKeys(data, keys...); offset == -1 { //查到了符合层级的key,返回offset
return nil, NotExist, -1, -1, KeyPathNotFoundError
}
}
// Go to closest value
nO := nextToken(data[offset:]) // 跳过 ‘ ‘, ‘\n‘, ‘\r‘, ‘\t‘ 这些byte
if nO == -1 {
return nil, NotExist, offset, -1, MalformedJsonError
}
offset += nO //更新offset
value, dataType, endOffset, err = getType(data, offset) //开始读取value的值,并返回dataType
if err != nil {
return value, dataType, offset, endOffset, err
}
// Strip quotes from string values
if dataType == String {
value = value[1 : len(value)-1]
}
return value[:len(value):len(value)], dataType, offset, endOffset, nil
}
进入getType,读取value的值。
func getType(data []byte, offset int) ([]byte, ValueType, int, error) {
var dataType ValueType
endOffset := offset
// if string value
if data[offset] == ‘"‘ { // 匹配 "
dataType = String
if idx, _ := stringEnd(data[offset+1:]); idx != -1 { //开始匹配下一个 " 然后返回index
endOffset += idx + 1 //确定了index就直接走到return了
} else {
return nil, dataType, offset, MalformedStringError
}
} else if data[offset] == ‘[‘ { // if array value
dataType = Array
// break label, for stopping nested loops
endOffset = blockEnd(data[offset:], ‘[‘, ‘]‘)
if endOffset == -1 {
return nil, dataType, offset, MalformedArrayError
}
endOffset += offset
} else if data[offset] == ‘{‘ { // if object value
dataType = Object
// break label, for stopping nested loops
endOffset = blockEnd(data[offset:], ‘{‘, ‘}‘)
if endOffset == -1 {
return nil, dataType, offset, MalformedObjectError
}
endOffset += offset
} else {
// Number, Boolean or None
end := tokenEnd(data[endOffset:])
if end == -1 {
return nil, dataType, offset, MalformedValueError
}
value := data[offset : endOffset+end]
switch data[offset] {
case ‘t‘, ‘f‘: // true or false
if bytes.Equal(value, trueLiteral) || bytes.Equal(value, falseLiteral) {
dataType = Boolean
} else {
return nil, Unknown, offset, UnknownValueTypeError
}
case ‘u‘, ‘n‘: // undefined or null
if bytes.Equal(value, nullLiteral) {
dataType = Null
} else {
return nil, Unknown, offset, UnknownValueTypeError
}
case ‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘, ‘5‘, ‘6‘, ‘7‘, ‘8‘, ‘9‘, ‘-‘:
dataType = Number
default:
return nil, Unknown, offset, UnknownValueTypeError
}
endOffset += end
}
return data[offset:endOffset], dataType, endOffset, nil // 通过切片截取数据,返回
}
如上就返回了指定的value 。
jsonparser 主要是通过遍历给定的json字节数组,然后按层级来查找和匹配 { " : 等符号,然后通过数组切片截取来取值。它主要是维护了几个变量,例如层级变量、offset变量等。
标签:als and func else 标准 heap contain opp img
原文地址:https://www.cnblogs.com/junjiedeng/p/14437384.html