标签:处理 描述 mvcc 存储 四种 因此 pre 多版本 nsis
ACID是事务应该具备的特性,一个标准的事务处理系统必须具备这些标准特征:
SQL标准中定义了四种隔离级别,从低到高分别是READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE:
事务的实现和日志是分不开的,InnoDB的事务是现实基于redo log实现的,这个日志是InnoDB存储引擎专属的日志,MySQL在服务层也提供了一个日志叫bin log,虽然这个日志和事务关系不大,但是是比较常用的日志,合并在这里一起介绍一下。
InnoDB的redo log大小是固定的,可能有多个大小相同的文件组成,用双指针组成一个环形队列,如下图所示:
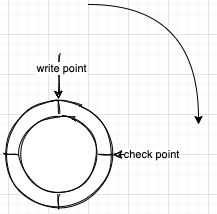
图中表示有四个文件,write point表示写指针,check point表示擦除指针,write point和check point之间的数据表示写在redo log还没写到磁盘记录的数据。
当有一条数据更新时,InnoDB会把更新操作写到redo log,并更新内存,这时更新操作就算完成了,InnoDB会在合适的时候把redo log里的记录更新到磁盘记录,或者说更新到数据库里。
上面所说的实现,就是MySQL的WAL技术,WAL全名是Write-Ahead Logging,也就是写磁盘记录之前先把记录保存在日志里,等到合适的时候在更新到磁盘记录。
那么什么时候是合适的时候呢?一个合适的时候是系统比较空闲的时候,这是写磁盘比较合适,还有一个"合适的时候"是redo log写满的时候,如果write point指针追上check point指针,也就是说redo log写满了没来得及擦除,那么这时不能执行更新操作,需要停下来把redo log部分日志擦除,留出一些空间。
redo log的写入和事务是保持一致的,都是两阶段的,更新操作执行时,会把记录写入redo log,此时这条记录的状态是prepare,等到事务提交后,存储引擎会把这条记录的状态改成commit,redo log可以让InnoDB具备crash-safe能力,即使数据库异常重启,也能保证提交的数据不丢失。
从上面描述可以知道,redo log的好处主要有两个方面,一个方面是保证每次更新都是顺序写,这样可以提高更新操作的效率,另一个方面是保证crash-safe能力。
从我个人来看,redo log可以满足事务的原子性、一致性、持久性,因为redo log生效是在事务提交后,那么在事务提交后,一个事务里的所有操作同时成功、生效,符合事务的原子性、一致性,redo log提供的crash-safe能力符合事务的持久性。
上面说的redo log是存储引擎层的日志,只有InnoDB才有的日志,这里说的bin log是服务端层的,属于MySQL服务层提供的通用能力,是一种归档日志。
bin log使用场景比较多,比如可以基于bin log做数据恢复、主从复制,目前工作时很多数据复制、数据巡检都是基于bin log实现的。
redo log和bin log的不同点主要有三个:
undo log主要记录数据被修改之前的日志,表数据修改前会把数据写到undo log,方便后续回滚、MVCC使用。
undo log主要有两种:
同一条数据可以在系统中存在多个版本,就是多版本并发控制,也就是MVCC。
上面说到的事务隔离级别,读提交和可重复读都会用到MVCC。
MySQL里对一条数据的读分为两种,一种是快照读,一种是当前读:
既然快照读是基于MVCC实现的,那么可以知道,MVCC可以提供读取历史版本数据的能力,这个能力的实现,依赖版本链、undo log、read view。
版本链依赖数据库记录上的回滚指针和undo log来实现,数据库每条数据记录都有一个字段标识上一个版本的指针,使用这个指针可以配合undo log这条数据的上一个版本,undo log里的数据记录也存有这么一个指针指向更前版本的数据,这样可以找到一条链,一路回溯到需要的最早的版本。
在读提交和可重复读隔离级别下,如果用到快照读,会创建read view:
read view在创建时会记录当前已提交最大事务号,这时如果读取一条数据,就可以拿着这个最大事务号和版本链上的数据进行比较,判断应该使用哪个版本的数据。
由此可知,读提交隔离级别每次快照读都会创建一个read view,所以每次读到的数据都是新的,可重复读隔离级别使用第一次快照读时创建的read view,所以可以做到可重复读。
可重复读隔离级别下整个快照读的行为可以参考下面这张图,竖线表示一个事务的提交,可以理解只能读到创建read view时已经提交的数据,而read view的创建是在第一次快照读的时候,而不是事务开启的时候。
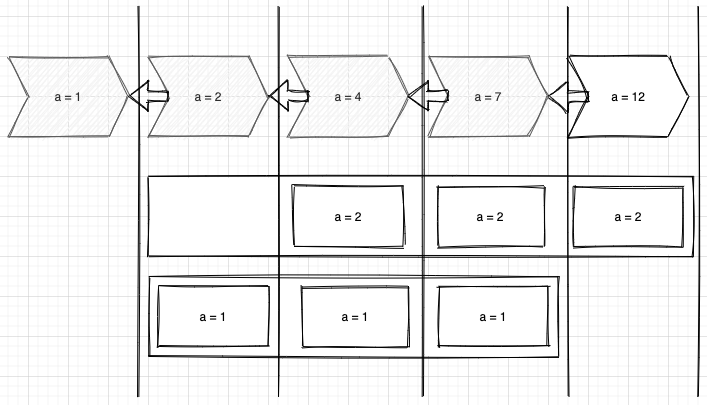
上面说的事务号大小判断只是一个因素,这里说明一下具体的判断逻辑。
创建read view是会保存一些值:
快照读能读到这条数据的条件是:
在快照读情况下,新插入的数据因为版本号过大(新插入的数据的事务号大于read view记录的已提交最大事务号),会被过滤掉,快照读情况下,MVCC解决了幻读问题。
在当前读情况下,因为每次读都会读取到最新数据,所以新插入的数据还是会被读出来,因此在当前读情况下会有幻读问题存在。
标签:处理 描述 mvcc 存储 四种 因此 pre 多版本 nsis
原文地址:https://www.cnblogs.com/gouden/p/14457646.html